 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePikeLPN: Mitigating Overlooked Inefficiencies of Low-Precision Neural Networks
Mar 29, 2024Low-precision quantization is recognized for its efficacy in neural network optimization. Our analysis reveals that non-quantized elementwise operations which are prevalent in layers such as parameterized activation functions, batch normalization, and quantization scaling dominate the inference cost of low-precision models. These non-quantized elementwise operations are commonly overlooked in SOTA efficiency metrics such as Arithmetic Computation Effort (ACE). In this paper, we propose ACEv2 - an extended version of ACE which offers a better alignment with the inference cost of quantized models and their energy consumption on ML hardware. Moreover, we introduce PikeLPN, a model that addresses these efficiency issues by applying quantization to both elementwise operations and multiply-accumulate operations. In particular, we present a novel quantization technique for batch normalization layers named QuantNorm which allows for quantizing the batch normalization parameters without compromising the model performance. Additionally, we propose applying Double Quantization where the quantization scaling parameters are quantized. Furthermore, we recognize and resolve the issue of distribution mismatch in Separable Convolution layers by introducing Distribution-Heterogeneous Quantization which enables quantizing them to low-precision. PikeLPN achieves Pareto-optimality in efficiency-accuracy trade-off with up to 3X efficiency improvement compared to SOTA low-precision models.
Some Improvements on Deep Convolutional Neural Network Based Image Classification
Dec 19, 2013


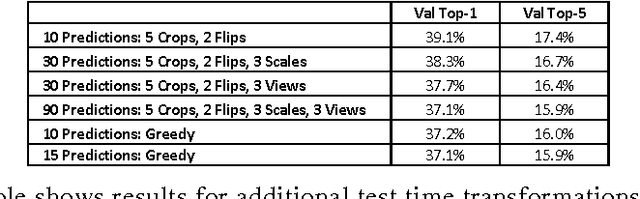
We investigate multiple techniques to improve upon the current state of the art deep convolutional neural network based image classification pipeline. The techiques include adding more image transformations to training data, adding more transformations to generate additional predictions at test time and using complementary models applied to higher resolution images. This paper summarizes our entry in the Imagenet Large Scale Visual Recognition Challenge 2013. Our system achieved a top 5 classification error rate of 13.55% using no external data which is over a 20% relative improvement on the previous year's winner.