 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Denoising Feedback
May 25, 2026Policy loss estimation remains a fundamental and long-standing challenge in reinforcement learning (RL) for diffusion language models (dLLMs). We introduce Reinforcement Learning from Denoising Feedback (RLDF), a novel training paradigm that leverages feedback obtained from rollout and training processes to facilitate accurate and efficient policy loss estimation. To balance the trade-off between computational efficiency and estimation effectiveness, RLDF optimizes the model toward the clipped clean state $\hat{x}_0$ from intermediate noisy states $x_t$, combined with weighted timestep sampling over $t$. Extensive experiments demonstrate that RLDF achieves consistent and substantial improvements in both performance and generalizability across two representative dLLM architectures, LLaDA and Dream, on multiple reasoning benchmarks. Our work lays a principled foundation for scalable reinforcement learning in diffusion language models. We build Drift, a training framework for dLLMs, available at https://github.com/ant-research/Drift.
Adaptive Serverless Resource Management via Slot-Survival Prediction and Event-Driven Lifecycle Control
Apr 07, 2026Serverless computing eliminates infrastructure management overhead but introduces significant challenges regarding cold start latency and resource utilization. Traditional static resource allocation often leads to inefficiencies under variable workloads, resulting in performance degradation or excessive costs. This paper presents an adaptive engineering framework that optimizes serverless performance through event-driven architecture and probabilistic modeling. We propose a dual-strategy mechanism that dynamically adjusts idle durations and employs an intelligent request waiting strategy based on slot survival predictions. By leveraging sliding window aggregation and asynchronous processing, our system proactively manages resource lifecycles. Experimental results show that our approach reduces cold starts by up to 51.2% and improves cost-efficiency by nearly 2x compared to baseline methods in multi-cloud environments.
MemMA: Coordinating the Memory Cycle through Multi-Agent Reasoning and In-Situ Self-Evolution
Mar 19, 2026Memory-augmented LLM agents maintain external memory banks to support long-horizon interaction, yet most existing systems treat construction, retrieval, and utilization as isolated subroutines. This creates two coupled challenges: strategic blindness on the forward path of the memory cycle, where construction and retrieval are driven by local heuristics rather than explicit strategic reasoning, and sparse, delayed supervision on the backward path, where downstream failures rarely translate into direct repairs of the memory bank. To address these challenges, we propose MemMA, a plug-and-play multi-agent framework that coordinates the memory cycle along both the forward and backward paths. On the forward path, a Meta-Thinker produces structured guidance that steers a Memory Manager during construction and directs a Query Reasoner during iterative retrieval. On the backward path, MemMA introduces in-situ self-evolving memory construction, which synthesizes probe QA pairs, verifies the current memory, and converts failures into repair actions before the memory is finalized. Extensive experiments on LoCoMo show that MemMA consistently outperforms existing baselines across multiple LLM backbones and improves three different storage backends in a plug-and-play manner. Our code is publicly available at https://github.com/ventr1c/memma.
Parameter-Free Adaptive Multi-Scale Channel-Spatial Attention Aggregation framework for 3D Indoor Semantic Scene Completion Toward Assisting Visually Impaired
Feb 19, 2026In indoor assistive perception for visually impaired users, 3D Semantic Scene Completion (SSC) is expected to provide structurally coherent and semantically consistent occupancy under strictly monocular vision for safety-critical scene understanding. However, existing monocular SSC approaches often lack explicit modeling of voxel-feature reliability and regulated cross-scale information propagation during 2D-3D projection and multi-scale fusion, making them vulnerable to projection diffusion and feature entanglement and thus limiting structural stability. To address these challenges, this paper presents an Adaptive Multi-scale Attention Aggregation (AMAA) framework built upon the MonoScene pipeline. Rather than introducing a heavier backbone, AMAA focuses on reliability-oriented feature regulation within a monocular SSC framework. Specifically, lifted voxel features are jointly calibrated in semantic and spatial dimensions through parallel channel-spatial attention aggregation, while multi-scale encoder-decoder fusion is stabilized via a hierarchical adaptive feature-gating strategy that regulates information injection across scales. Experiments on the NYUv2 benchmark demonstrate consistent improvements over MonoScene without significantly increasing system complexity: AMAA achieves 27.25% SSC mIoU (+0.31) and 43.10% SC IoU (+0.59). In addition, system-level deployment on an NVIDIA Jetson platform verifies that the complete AMAA framework can be executed stably on embedded hardware. Overall, AMAA improves monocular SSC quality and provides a reliable and deployable perception framework for indoor assistive systems targeting visually impaired users.
How Far Are LLMs from Professional Poker Players? Revisiting Game-Theoretic Reasoning with Agentic Tool Use
Jan 31, 2026As Large Language Models (LLMs) are increasingly applied in high-stakes domains, their ability to reason strategically under uncertainty becomes critical. Poker provides a rigorous testbed, requiring not only strong actions but also principled, game-theoretic reasoning. In this paper, we conduct a systematic study of LLMs in multiple realistic poker tasks, evaluating both gameplay outcomes and reasoning traces. Our analysis reveals LLMs fail to compete against traditional algorithms and identifies three recurring flaws: reliance on heuristics, factual misunderstandings, and a "knowing-doing" gap where actions diverge from reasoning. An initial attempt with behavior cloning and step-level reinforcement learning improves reasoning style but remains insufficient for accurate game-theoretic play. Motivated by these limitations, we propose ToolPoker, a tool-integrated reasoning framework that combines external solvers for GTO-consistent actions with more precise professional-style explanations. Experiments demonstrate that ToolPoker achieves state-of-the-art gameplay while producing reasoning traces that closely reflect game-theoretic principles.
EpiQAL: Benchmarking Large Language Models in Epidemiological Question Answering for Enhanced Alignment and Reasoning
Jan 06, 2026Reliable epidemiological reasoning requires synthesizing study evidence to infer disease burden, transmission dynamics, and intervention effects at the population level. Existing medical question answering benchmarks primarily emphasize clinical knowledge or patient-level reasoning, yet few systematically evaluate evidence-grounded epidemiological inference. We present EpiQAL, the first diagnostic benchmark for epidemiological question answering across diverse diseases, comprising three subsets built from open-access literature. The subsets respectively evaluate text-grounded factual recall, multi-step inference linking document evidence with epidemiological principles, and conclusion reconstruction with the Discussion section withheld. Construction combines expert-designed taxonomy guidance, multi-model verification, and retrieval-based difficulty control. Experiments on ten open models reveal that current LLMs show limited performance on epidemiological reasoning, with multi-step inference posing the greatest challenge. Model rankings shift across subsets, and scale alone does not predict success. Chain-of-Thought prompting benefits multi-step inference but yields mixed results elsewhere. EpiQAL provides fine-grained diagnostic signals for evidence grounding, inferential reasoning, and conclusion reconstruction.
STReasoner: Empowering LLMs for Spatio-Temporal Reasoning in Time Series via Spatial-Aware Reinforcement Learning
Jan 06, 2026Spatio-temporal reasoning in time series involves the explicit synthesis of temporal dynamics, spatial dependencies, and textual context. This capability is vital for high-stakes decision-making in systems such as traffic networks, power grids, and disease propagation. However, the field remains underdeveloped because most existing works prioritize predictive accuracy over reasoning. To address the gap, we introduce ST-Bench, a benchmark consisting of four core tasks, including etiological reasoning, entity identification, correlation reasoning, and in-context forecasting, developed via a network SDE-based multi-agent data synthesis pipeline. We then propose STReasoner, which empowers LLM to integrate time series, graph structure, and text for explicit reasoning. To promote spatially grounded logic, we introduce S-GRPO, a reinforcement learning algorithm that rewards performance gains specifically attributable to spatial information. Experiments show that STReasoner achieves average accuracy gains between 17% and 135% at only 0.004X the cost of proprietary models and generalizes robustly to real-world data.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025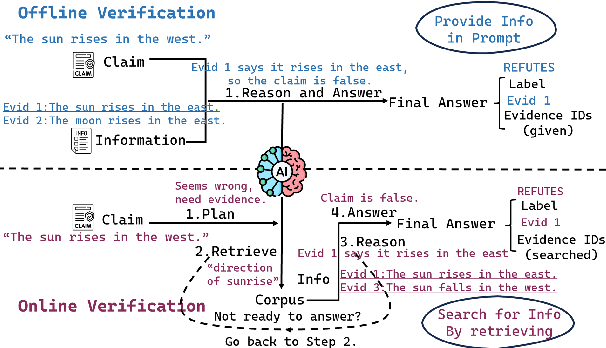
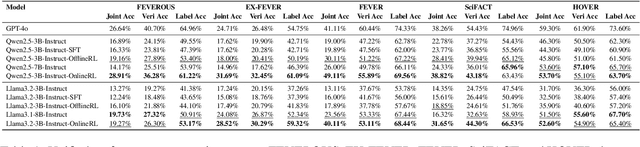
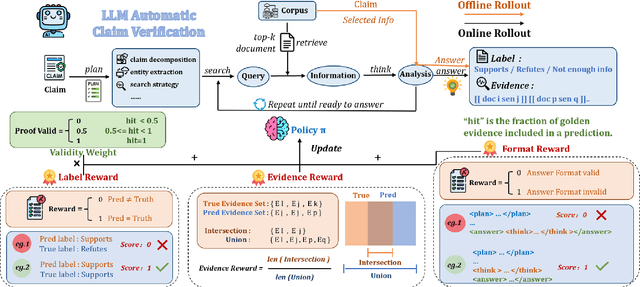

Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
Bradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
EcomScriptBench: A Multi-task Benchmark for E-commerce Script Planning via Step-wise Intention-Driven Product Association
May 21, 2025Goal-oriented script planning, or the ability to devise coherent sequences of actions toward specific goals, is commonly employed by humans to plan for typical activities. In e-commerce, customers increasingly seek LLM-based assistants to generate scripts and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains underexplored due to several challenges, including the inability of LLMs to simultaneously conduct script planning and product retrieval, difficulties in matching products caused by semantic discrepancies between planned actions and search queries, and a lack of methods and benchmark data for evaluation. In this paper, we step forward by formally defining the task of E-commerce Script Planning (EcomScript) as three sequential subtasks. We propose a novel framework that enables the scalable generation of product-enriched scripts by associating products with each step based on the semantic similarity between the actions and their purchase intentions. By applying our framework to real-world e-commerce data, we construct the very first large-scale EcomScript dataset, EcomScriptBench, which includes 605,229 scripts sourced from 2.4 million products. Human annotations are then conducted to provide gold labels for a sampled subset, forming an evaluation benchmark. Extensive experiments reveal that current (L)LMs face significant challenges with EcomScript tasks, even after fine-tuning, while injecting product purchase intentions improves their performance.