 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRO: LLM Agent Optimization Through Rising Reward Trajectories
May 27, 2025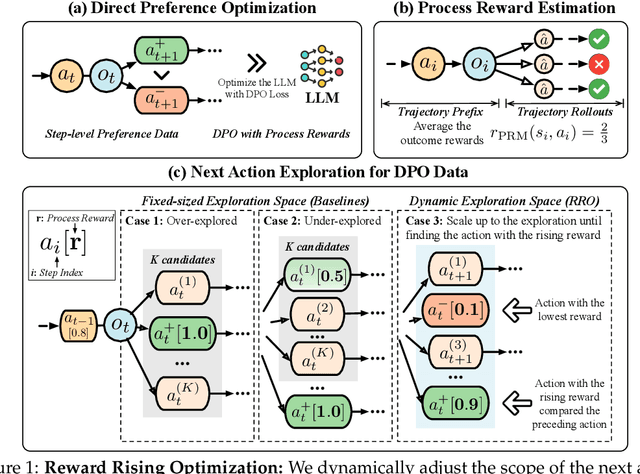
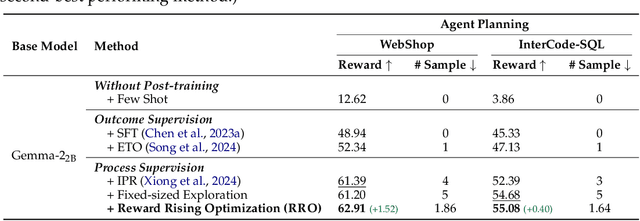
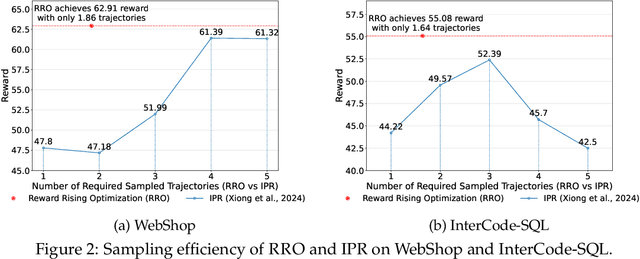

Large language models (LLMs) have exhibited extraordinary performance in a variety of tasks while it remains challenging for them to solve complex multi-step tasks as agents. In practice, agents sensitive to the outcome of certain key steps which makes them likely to fail the task because of a subtle mistake in the planning trajectory. Recent approaches resort to calibrating the reasoning process through reinforcement learning. They reward or penalize every reasoning step with process supervision, as known as Process Reward Models (PRMs). However, PRMs are difficult and costly to scale up with a large number of next action candidates since they require extensive computations to acquire the training data through the per-step trajectory exploration. To mitigate this issue, we focus on the relative reward trend across successive reasoning steps and propose maintaining an increasing reward in the collected trajectories for process supervision, which we term Reward Rising Optimization (RRO). Specifically, we incrementally augment the process supervision until identifying a step exhibiting positive reward differentials, i.e. rising rewards, relative to its preceding iteration. This method dynamically expands the search space for the next action candidates, efficiently capturing high-quality data. We provide mathematical groundings and empirical results on the WebShop and InterCode-SQL benchmarks, showing that our proposed RRO achieves superior performance while requiring much less exploration cost.
Cite Before You Speak: Enhancing Context-Response Grounding in E-commerce Conversational LLM-Agents
Mar 05, 2025With the advancement of conversational large language models (LLMs), several LLM-based Conversational Shopping Agents (CSA) have been developed to help customers answer questions and smooth their shopping journey in e-commerce domain. The primary objective in building a trustworthy CSA is to ensure the agent's responses are accurate and factually grounded, which is essential for building customer trust and encouraging continuous engagement. However, two challenges remain. First, LLMs produce hallucinated or unsupported claims. Such inaccuracies risk spreading misinformation and diminishing customer trust. Second, without providing knowledge source attribution in CSA response, customers struggle to verify LLM-generated information. To address these challenges, we present an easily productionized solution that enables a "citation experience" utilizing In-context Learning (ICL) and Multi-UX-Inference (MUI) to generate responses with citations to attribute its original sources without interfering other existing UX features. With proper UX design, these citation marks can be linked to the related product information and display the source to our customers. In this work, we also build auto-metrics and scalable benchmarks to holistically evaluate LLM's grounding and attribution capabilities. Our experiments demonstrate that incorporating this citation generation paradigm can substantially enhance the grounding of LLM responses by 13.83% on the real-world data. As such, our solution not only addresses the immediate challenges of LLM grounding issues but also adds transparency to conversational AI.
REAPER: Reasoning based Retrieval Planning for Complex RAG Systems
Jul 26, 2024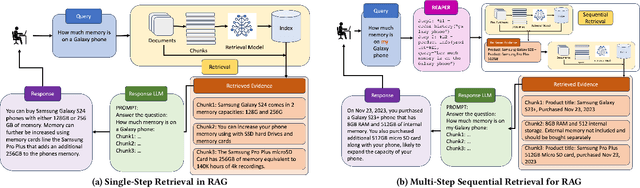
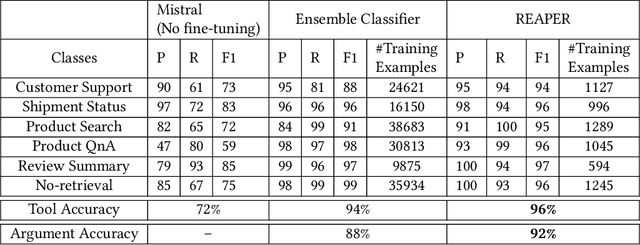


Complex dialog systems often use retrieved evidence to facilitate factual responses. Such RAG (Retrieval Augmented Generation) systems retrieve from massive heterogeneous data stores that are usually architected as multiple indexes or APIs instead of a single monolithic source. For a given query, relevant evidence needs to be retrieved from one or a small subset of possible retrieval sources. Complex queries can even require multi-step retrieval. For example, a conversational agent on a retail site answering customer questions about past orders will need to retrieve the appropriate customer order first and then the evidence relevant to the customer's question in the context of the ordered product. Most RAG Agents handle such Chain-of-Thought (CoT) tasks by interleaving reasoning and retrieval steps. However, each reasoning step directly adds to the latency of the system. For large models (>100B parameters) this latency cost is significant -- in the order of multiple seconds. Multi-agent systems may classify the query to a single Agent associated with a retrieval source, though this means that a (small) classification model dictates the performance of a large language model. In this work we present REAPER (REAsoning-based PlannER) - an LLM based planner to generate retrieval plans in conversational systems. We show significant gains in latency over Agent-based systems and are able to scale easily to new and unseen use cases as compared to classification-based planning. Though our method can be applied to any RAG system, we show our results in the context of Rufus -- Amazon's conversational shopping assistant.