 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking Knowledge to Care: Knowledge Graph-Augmented Medical Follow-Up Question Generation
Mar 01, 2026Clinical diagnosis is time-consuming, requiring intensive interactions between patients and medical professionals. While large language models (LLMs) could ease the pre-diagnostic workload, their limited domain knowledge hinders effective medical question generation. We introduce a Knowledge Graph-augmented LLM with active in-context learning to generate relevant and important follow-up questions, KG-Followup, serving as a critical module for the pre-diagnostic assessment. The structured medical domain knowledge graph serves as a seamless patch-up to provide professional domain expertise upon which the LLM can reason. Experiments demonstrate that KG-Followup outperforms state-of-the-art methods by 5% - 8% on relevant benchmarks in recall.
Exploring Query Understanding for Amazon Product Search
Aug 05, 2024



Online shopping platforms, such as Amazon, offer services to billions of people worldwide. Unlike web search or other search engines, product search engines have their unique characteristics, primarily featuring short queries which are mostly a combination of product attributes and structured product search space. The uniqueness of product search underscores the crucial importance of the query understanding component. However, there are limited studies focusing on exploring this impact within real-world product search engines. In this work, we aim to bridge this gap by conducting a comprehensive study and sharing our year-long journey investigating how the query understanding service impacts Amazon Product Search. Firstly, we explore how query understanding-based ranking features influence the ranking process. Next, we delve into how the query understanding system contributes to understanding the performance of a ranking model. Building on the insights gained from our study on the evaluation of the query understanding-based ranking model, we propose a query understanding-based multi-task learning framework for ranking. We present our studies and investigations using the real-world system on Amazon Search.
REAPER: Reasoning based Retrieval Planning for Complex RAG Systems
Jul 26, 2024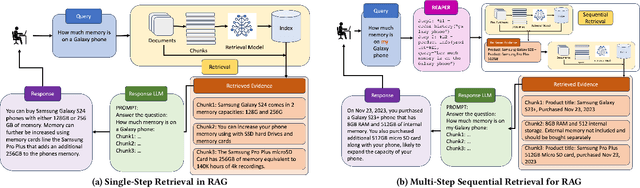
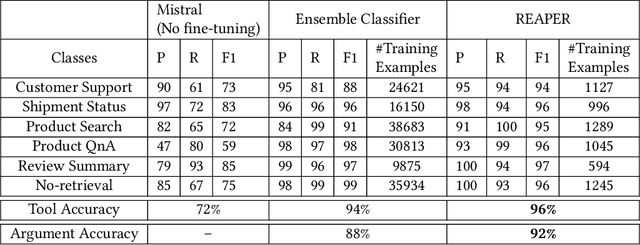


Complex dialog systems often use retrieved evidence to facilitate factual responses. Such RAG (Retrieval Augmented Generation) systems retrieve from massive heterogeneous data stores that are usually architected as multiple indexes or APIs instead of a single monolithic source. For a given query, relevant evidence needs to be retrieved from one or a small subset of possible retrieval sources. Complex queries can even require multi-step retrieval. For example, a conversational agent on a retail site answering customer questions about past orders will need to retrieve the appropriate customer order first and then the evidence relevant to the customer's question in the context of the ordered product. Most RAG Agents handle such Chain-of-Thought (CoT) tasks by interleaving reasoning and retrieval steps. However, each reasoning step directly adds to the latency of the system. For large models (>100B parameters) this latency cost is significant -- in the order of multiple seconds. Multi-agent systems may classify the query to a single Agent associated with a retrieval source, though this means that a (small) classification model dictates the performance of a large language model. In this work we present REAPER (REAsoning-based PlannER) - an LLM based planner to generate retrieval plans in conversational systems. We show significant gains in latency over Agent-based systems and are able to scale easily to new and unseen use cases as compared to classification-based planning. Though our method can be applied to any RAG system, we show our results in the context of Rufus -- Amazon's conversational shopping assistant.