 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAPER: Reasoning based Retrieval Planning for Complex RAG Systems
Jul 26, 2024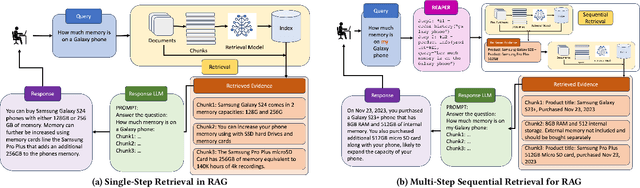
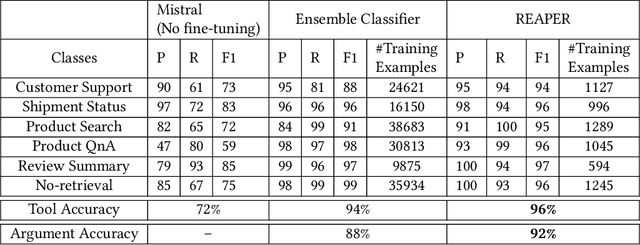


Complex dialog systems often use retrieved evidence to facilitate factual responses. Such RAG (Retrieval Augmented Generation) systems retrieve from massive heterogeneous data stores that are usually architected as multiple indexes or APIs instead of a single monolithic source. For a given query, relevant evidence needs to be retrieved from one or a small subset of possible retrieval sources. Complex queries can even require multi-step retrieval. For example, a conversational agent on a retail site answering customer questions about past orders will need to retrieve the appropriate customer order first and then the evidence relevant to the customer's question in the context of the ordered product. Most RAG Agents handle such Chain-of-Thought (CoT) tasks by interleaving reasoning and retrieval steps. However, each reasoning step directly adds to the latency of the system. For large models (>100B parameters) this latency cost is significant -- in the order of multiple seconds. Multi-agent systems may classify the query to a single Agent associated with a retrieval source, though this means that a (small) classification model dictates the performance of a large language model. In this work we present REAPER (REAsoning-based PlannER) - an LLM based planner to generate retrieval plans in conversational systems. We show significant gains in latency over Agent-based systems and are able to scale easily to new and unseen use cases as compared to classification-based planning. Though our method can be applied to any RAG system, we show our results in the context of Rufus -- Amazon's conversational shopping assistant.
Are LLMs the Master of All Trades? : Exploring Domain-Agnostic Reasoning Skills of LLMs
Mar 22, 2023The potential of large language models (LLMs) to reason like humans has been a highly contested topic in Machine Learning communities. However, the reasoning abilities of humans are multifaceted and can be seen in various forms, including analogical, spatial and moral reasoning, among others. This fact raises the question whether LLMs can perform equally well across all these different domains. This research work aims to investigate the performance of LLMs on different reasoning tasks by conducting experiments that directly use or draw inspirations from existing datasets on analogical and spatial reasoning. Additionally, to evaluate the ability of LLMs to reason like human, their performance is evaluted on more open-ended, natural language questions. My findings indicate that LLMs excel at analogical and moral reasoning, yet struggle to perform as proficiently on spatial reasoning tasks. I believe these experiments are crucial for informing the future development of LLMs, particularly in contexts that require diverse reasoning proficiencies. By shedding light on the reasoning abilities of LLMs, this study aims to push forward our understanding of how they can better emulate the cognitive abilities of humans.