 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Artifacts: Towards Generalizable Synthetic Song Detection via Music-Intrinsic Features
Jun 15, 2026The rapid advancement of AI music generators highlights the urgent need for reliable Synthetic Song Detection (SSD). Existing SSD methods often rely on low-level artifacts or fixed feature assumptions, struggling to capture generator-agnostic cues. To address this, we propose Sofia (Synthetic-song detection framework via music features), a flexible framework that models music-intrinsic attributes via feature-specific experts and an adaptive Mixture-of-Experts (MoE) module. By configuring Sofia with representative Vocal, Audio-effect, Global structure features, and their combinations, we present their individual and complementary contributions. To comprehensively evaluate our framework, we further construct MUSIC8K, a challenging benchmark featuring lastest emerging generators and realistic audio perturbations. Experiments show that Sofia learns generator-agnostic representations from music-intrinsic features, improving the F1 score by 18.5 points over the strongest baseline on MUSIC8K-O while maintaining strong robustness.
Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline
Jan 18, 2026Recent advances in LLM-based multi-agent systems (MAS) show that workflows composed of multiple LLM agents with distinct roles, tools, and communication patterns can outperform single-LLM baselines on complex tasks. However, most frameworks are homogeneous, where all agents share the same base LLM and differ only in prompts, tools, and positions in the workflow. This raises the question of whether such workflows can be simulated by a single agent through multi-turn conversations. We investigate this across seven benchmarks spanning coding, mathematics, general question answering, domain-specific reasoning, and real-world planning and tool use. Our results show that a single agent can reach the performance of homogeneous workflows with an efficiency advantage from KV cache reuse, and can even match the performance of an automatically optimized heterogeneous workflow. Building on this finding, we propose \textbf{OneFlow}, an algorithm that automatically tailors workflows for single-agent execution, reducing inference costs compared to existing automatic multi-agent design frameworks without trading off accuracy. These results position the single-LLM implementation of multi-agent workflows as a strong baseline for MAS research. We also note that single-LLM methods cannot capture heterogeneous workflows due to the lack of KV cache sharing across different LLMs, highlighting future opportunities in developing \textit{truly} heterogeneous multi-agent systems.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
Beyond Believability: Accurate Human Behavior Simulation with Fine-Tuned LLMs
Mar 27, 2025Recent research shows that LLMs can simulate ``believable'' human behaviors to power LLM agents via prompt-only methods. In this work, we focus on evaluating and improving LLM's objective ``accuracy'' rather than the subjective ``believability'' in the web action generation task, leveraging a large-scale, real-world dataset collected from online shopping human actions. We present the first comprehensive quantitative evaluation of state-of-the-art LLMs (e.g., DeepSeek-R1, Llama, and Claude) on the task of web action generation. Our results show that fine-tuning LLMs on real-world behavioral data substantially improves their ability to generate actions compared to prompt-only methods. Furthermore, incorporating synthesized reasoning traces into model training leads to additional performance gains, demonstrating the value of explicit rationale in behavior modeling. This work establishes a new benchmark for evaluating LLMs in behavior simulation and offers actionable insights into how real-world action data and reasoning augmentation can enhance the fidelity of LLM agents.
Learning from Noisy Labels with Contrastive Co-Transformer
Mar 04, 2025



Deep learning with noisy labels is an interesting challenge in weakly supervised learning. Despite their significant learning capacity, CNNs have a tendency to overfit in the presence of samples with noisy labels. Alleviating this issue, the well known Co-Training framework is used as a fundamental basis for our work. In this paper, we introduce a Contrastive Co-Transformer framework, which is simple and fast, yet able to improve the performance by a large margin compared to the state-of-the-art approaches. We argue the robustness of transformers when dealing with label noise. Our Contrastive Co-Transformer approach is able to utilize all samples in the dataset, irrespective of whether they are clean or noisy. Transformers are trained by a combination of contrastive loss and classification loss. Extensive experimental results on corrupted data from six standard benchmark datasets including Clothing1M, demonstrate that our Contrastive Co-Transformer is superior to existing state-of-the-art methods.
Stepwise Perplexity-Guided Refinement for Efficient Chain-of-Thought Reasoning in Large Language Models
Feb 18, 2025Chain-of-Thought (CoT) reasoning, which breaks down complex tasks into intermediate reasoning steps, has significantly enhanced the performance of large language models (LLMs) on challenging tasks. However, the detailed reasoning process in CoT often incurs long generation times and high computational costs, partly due to the inclusion of unnecessary steps. To address this, we propose a method to identify critical reasoning steps using perplexity as a measure of their importance: a step is deemed critical if its removal causes a significant increase in perplexity. Our method enables models to focus solely on generating these critical steps. This can be achieved through two approaches: refining demonstration examples in few-shot CoT or fine-tuning the model using selected examples that include only critical steps. Comprehensive experiments validate the effectiveness of our method, which achieves a better balance between the reasoning accuracy and efficiency of CoT.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
A Survey of Calibration Process for Black-Box LLMs
Dec 17, 2024



Large Language Models (LLMs) demonstrate remarkable performance in semantic understanding and generation, yet accurately assessing their output reliability remains a significant challenge. While numerous studies have explored calibration techniques, they primarily focus on White-Box LLMs with accessible parameters. Black-Box LLMs, despite their superior performance, pose heightened requirements for calibration techniques due to their API-only interaction constraints. Although recent researches have achieved breakthroughs in black-box LLMs calibration, a systematic survey of these methodologies is still lacking. To bridge this gap, we presents the first comprehensive survey on calibration techniques for black-box LLMs. We first define the Calibration Process of LLMs as comprising two interrelated key steps: Confidence Estimation and Calibration. Second, we conduct a systematic review of applicable methods within black-box settings, and provide insights on the unique challenges and connections in implementing these key steps. Furthermore, we explore typical applications of Calibration Process in black-box LLMs and outline promising future research directions, providing new perspectives for enhancing reliability and human-machine alignment. This is our GitHub link: https://github.com/LiangruXie/Calibration-Process-in-Black-Box-LLMs
Towards Patronizing and Condescending Language in Chinese Videos: A Multimodal Dataset and Detector
Sep 10, 2024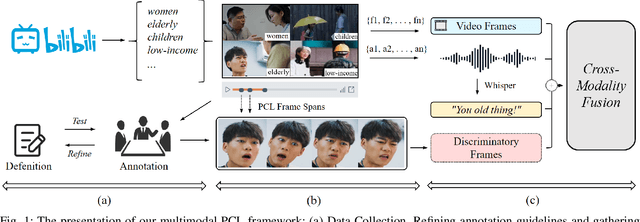
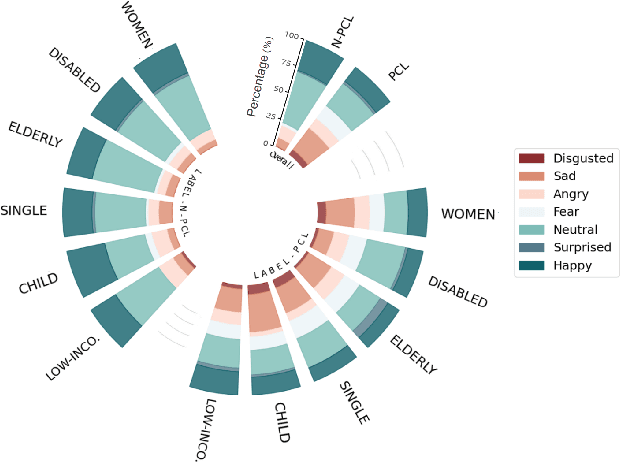
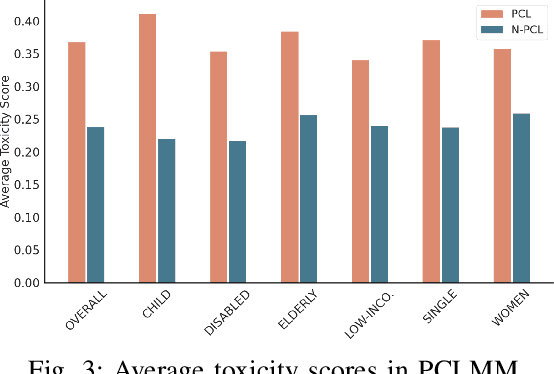
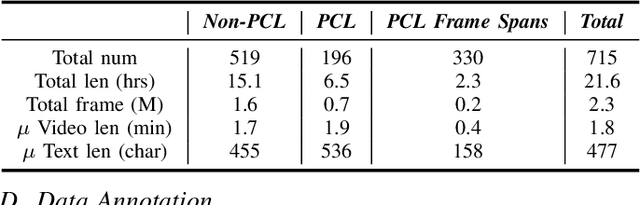
Patronizing and Condescending Language (PCL) is a form of discriminatory toxic speech targeting vulnerable groups, threatening both online and offline safety. While toxic speech research has mainly focused on overt toxicity, such as hate speech, microaggressions in the form of PCL remain underexplored. Additionally, dominant groups' discriminatory facial expressions and attitudes toward vulnerable communities can be more impactful than verbal cues, yet these frame features are often overlooked. In this paper, we introduce the PCLMM dataset, the first Chinese multimodal dataset for PCL, consisting of 715 annotated videos from Bilibili, with high-quality PCL facial frame spans. We also propose the MultiPCL detector, featuring a facial expression detection module for PCL recognition, demonstrating the effectiveness of modality complementarity in this challenging task. Our work makes an important contribution to advancing microaggression detection within the domain of toxic speech.
Distinguish Any Fake Videos: Unleashing the Power of Large-scale Data and Motion Features
May 24, 2024


The development of AI-Generated Content (AIGC) has empowered the creation of remarkably realistic AI-generated videos, such as those involving Sora. However, the widespread adoption of these models raises concerns regarding potential misuse, including face video scams and copyright disputes. Addressing these concerns requires the development of robust tools capable of accurately determining video authenticity. The main challenges lie in the dataset and neural classifier for training. Current datasets lack a varied and comprehensive repository of real and generated content for effective discrimination. In this paper, we first introduce an extensive video dataset designed specifically for AI-Generated Video Detection (GenVidDet). It includes over 2.66 M instances of both real and generated videos, varying in categories, frames per second, resolutions, and lengths. The comprehensiveness of GenVidDet enables the training of a generalizable video detector. We also present the Dual-Branch 3D Transformer (DuB3D), an innovative and effective method for distinguishing between real and generated videos, enhanced by incorporating motion information alongside visual appearance. DuB3D utilizes a dual-branch architecture that adaptively leverages and fuses raw spatio-temporal data and optical flow. We systematically explore the critical factors affecting detection performance, achieving the optimal configuration for DuB3D. Trained on GenVidDet, DuB3D can distinguish between real and generated video content with 96.77% accuracy, and strong generalization capability even for unseen types.