 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of Imagery Reasoning in Frontier LLM Models
Mar 25, 2026Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, yet they struggle with spatial tasks that require mental simulation, such as mental rotation. This paper investigates whether equipping an LLM with an external ``Imagery Module'' -- a tool capable of rendering and rotating 3D models -- can bridge this gap, functioning as a ``cognitive prosthetic.'' We conducted experiments using a dual-module architecture in which a reasoning module (an MLLM) interacts with an imagery module on 3D model rotation tasks. Performance was lower than expected, with accuracy reaching at most 62.5%. Further investigation suggests that even when the burden of maintaining and manipulating a holistic 3D state is outsourced, the system still fails. This reveals that current frontier models lack the foundational visual-spatial primitives required to interface with imagery. Specifically, they lack: (1) the low-level sensitivity to extract spatial signals such as (a) depth, (b) motion, and (c) short-horizon dynamic prediction; and (2) the capacity to reason contemplatively over images, dynamically shifting visual focus and balancing imagery with symbolic and associative information.
LoX: Low-Rank Extrapolation Robustifies LLM Safety Against Fine-tuning
Jun 18, 2025Large Language Models (LLMs) have become indispensable in real-world applications. However, their widespread adoption raises significant safety concerns, particularly in responding to socially harmful questions. Despite substantial efforts to improve model safety through alignment, aligned models can still have their safety protections undermined by subsequent fine-tuning - even when the additional training data appears benign. In this paper, we empirically demonstrate that this vulnerability stems from the sensitivity of safety-critical low-rank subspaces in LLM parameters to fine-tuning. Building on this insight, we propose a novel training-free method, termed Low-Rank Extrapolation (LoX), to enhance safety robustness by extrapolating the safety subspace of an aligned LLM. Our experimental results confirm the effectiveness of LoX, demonstrating significant improvements in robustness against both benign and malicious fine-tuning attacks while preserving the model's adaptability to new tasks. For instance, LoX leads to 11% to 54% absolute reductions in attack success rates (ASR) facing benign or malicious fine-tuning attacks. By investigating the ASR landscape of parameters, we attribute the success of LoX to that the extrapolation moves LLM parameters to a flatter zone, thereby less sensitive to perturbations. The code is available at github.com/VITA-Group/LoX.
Fine-Tuning Video-Text Contrastive Model for Primate Behavior Retrieval from Unlabeled Raw Videos
May 08, 2025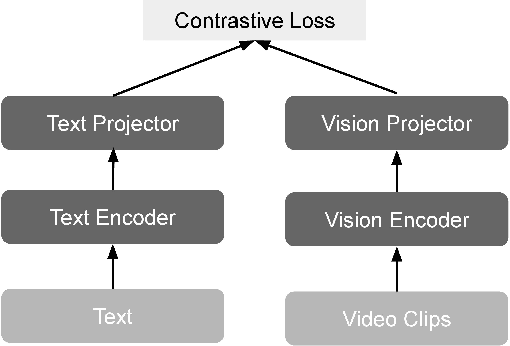



Video recordings of nonhuman primates in their natural habitat are a common source for studying their behavior in the wild. We fine-tune pre-trained video-text foundational models for the specific domain of capuchin monkeys, with the goal of developing useful computational models to help researchers to retrieve useful clips from videos. We focus on the challenging problem of training a model based solely on raw, unlabeled video footage, using weak audio descriptions sometimes provided by field collaborators. We leverage recent advances in Multimodal Large Language Models (MLLMs) and Vision-Language Models (VLMs) to address the extremely noisy nature of both video and audio content. Specifically, we propose a two-folded approach: an agentic data treatment pipeline and a fine-tuning process. The data processing pipeline automatically extracts clean and semantically aligned video-text pairs from the raw videos, which are subsequently used to fine-tune a pre-trained Microsoft's X-CLIP model through Low-Rank Adaptation (LoRA). We obtained an uplift in $Hits@5$ of $167\%$ for the 16 frames model and an uplift of $114\%$ for the 8 frame model on our domain data. Moreover, based on $NDCG@K$ results, our model is able to rank well most of the considered behaviors, while the tested raw pre-trained models are not able to rank them at all. The code will be made available upon acceptance.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
Efficient Video-Based ALPR System Using YOLO and Visual Rhythm
Jan 08, 2025

Automatic License Plate Recognition (ALPR) involves extracting vehicle license plate information from image or a video capture. These systems have gained popularity due to the wide availability of low-cost surveillance cameras and advances in Deep Learning. Typically, video-based ALPR systems rely on multiple frames to detect the vehicle and recognize the license plates. Therefore, we propose a system capable of extracting exactly one frame per vehicle and recognizing its license plate characters from this singular image using an Optical Character Recognition (OCR) model. Early experiments show that this methodology is viable.
Efficient License Plate Recognition in Videos Using Visual Rhythm and Accumulative Line Analysis
Jan 08, 2025



Video-based Automatic License Plate Recognition (ALPR) involves extracting vehicle license plate text information from video captures. Traditional systems typically rely heavily on high-end computing resources and utilize multiple frames to recognize license plates, leading to increased computational overhead. In this paper, we propose two methods capable of efficiently extracting exactly one frame per vehicle and recognizing its license plate characters from this single image, thus significantly reducing computational demands. The first method uses Visual Rhythm (VR) to generate time-spatial images from videos, while the second employs Accumulative Line Analysis (ALA), a novel algorithm based on single-line video processing for real-time operation. Both methods leverage YOLO for license plate detection within the frame and a Convolutional Neural Network (CNN) for Optical Character Recognition (OCR) to extract textual information. Experiments on real videos demonstrate that the proposed methods achieve results comparable to traditional frame-by-frame approaches, with processing speeds three times faster.
Combining YOLO and Visual Rhythm for Vehicle Counting
Jan 08, 2025



Video-based vehicle detection and counting play a critical role in managing transport infrastructure. Traditional image-based counting methods usually involve two main steps: initial detection and subsequent tracking, which are applied to all video frames, leading to a significant increase in computational complexity. To address this issue, this work presents an alternative and more efficient method for vehicle detection and counting. The proposed approach eliminates the need for a tracking step and focuses solely on detecting vehicles in key video frames, thereby increasing its efficiency. To achieve this, we developed a system that combines YOLO, for vehicle detection, with Visual Rhythm, a way to create time-spatial images that allows us to focus on frames that contain useful information. Additionally, this method can be used for counting in any application involving unidirectional moving targets to be detected and identified. Experimental analysis using real videos shows that the proposed method achieves mean counting accuracy around 99.15% over a set of videos, with a processing speed three times faster than tracking based approaches.
Self-supervised Learning for Astronomical Image Classification
Apr 23, 2020


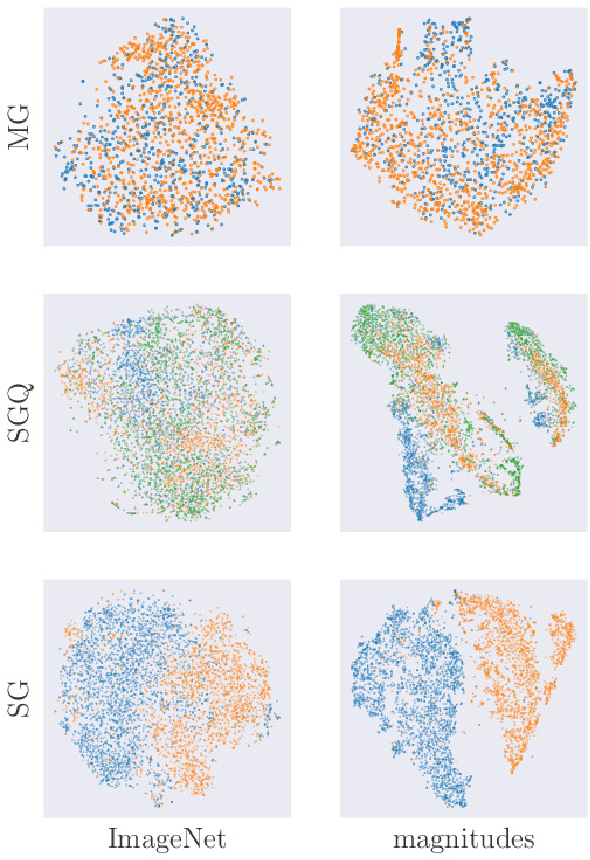
In Astronomy, a huge amount of image data is generated daily by photometric surveys, which scan the sky to collect data from stars, galaxies and other celestial objects. In this paper, we propose a technique to leverage unlabeled astronomical images to pre-train deep convolutional neural networks, in order to learn a domain-specific feature extractor which improves the results of machine learning techniques in setups with small amounts of labeled data available. We show that our technique produces results which are in many cases better than using ImageNet pre-training.
Greenery Segmentation In Urban Images By Deep Learning
Dec 12, 2019
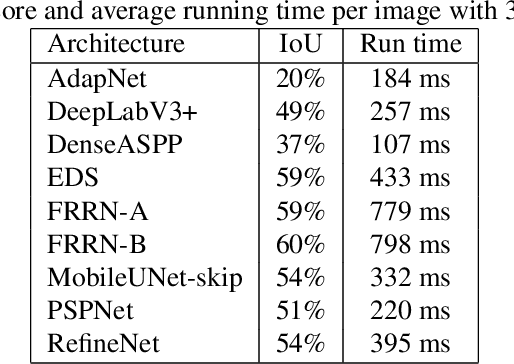
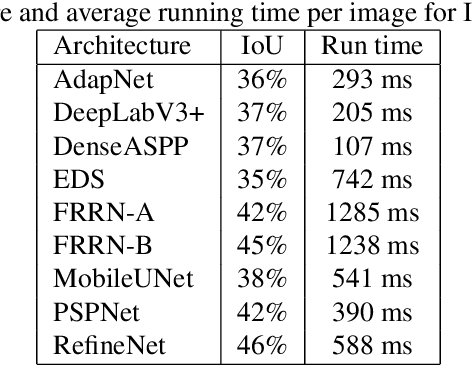

Vegetation is a relevant feature in the urban scenery and its awareness can be measured in an image by the Green View Index (GVI). Previous approaches to estimate the GVI were based upon heuristics image processing approaches and recently by deep learning networks (DLN). By leveraging some recent DLN architectures tuned to the image segmentation problem and exploiting a weighting strategy in the loss function (LF) we improved previously reported results in similar datasets.
Deep Learning Multidimensional Projections
Feb 21, 2019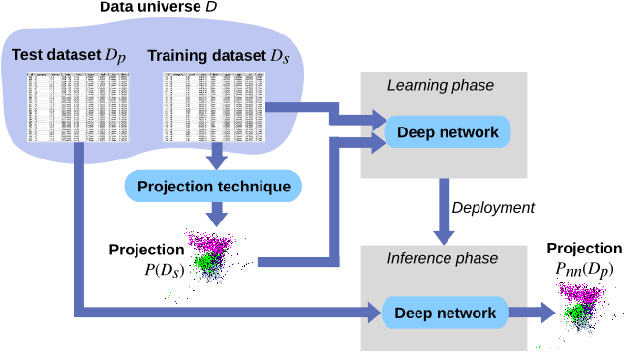
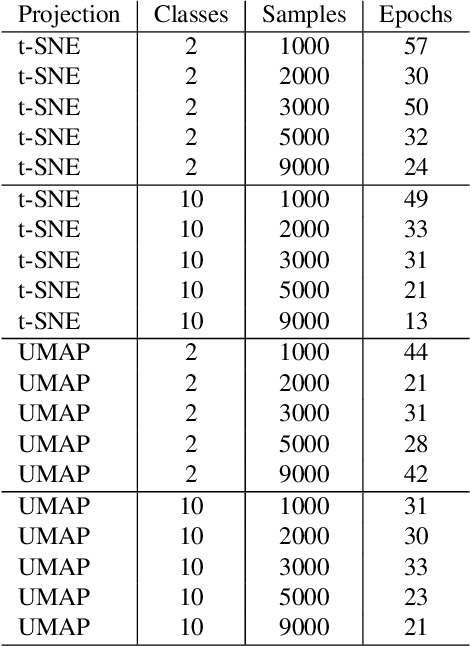
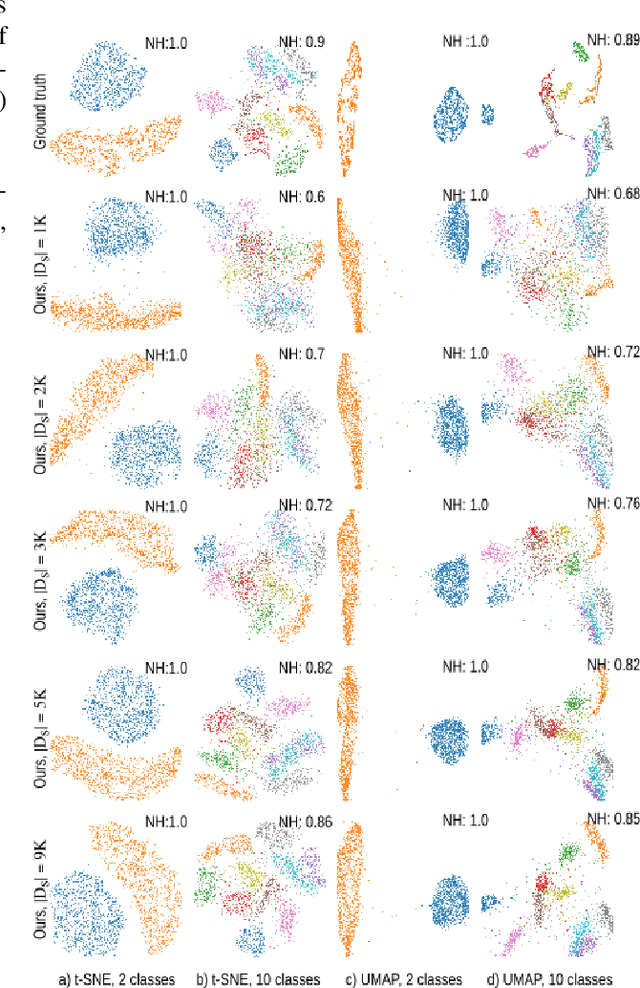

Dimensionality reduction methods, also known as projections, are frequently used for exploring multidimensional data in machine learning, data science, and information visualization. Among these, t-SNE and its variants have become very popular for their ability to visually separate distinct data clusters. However, such methods are computationally expensive for large datasets, suffer from stability problems, and cannot directly handle out-of-sample data. We propose a learning approach to construct such projections. We train a deep neural network based on a collection of samples from a given data universe, and their corresponding projections, and next use the network to infer projections of data from the same, or similar, universes. Our approach generates projections with similar characteristics as the learned ones, is computationally two to three orders of magnitude faster than SNE-class methods, has no complex-to-set user parameters, handles out-of-sample data in a stable manner, and can be used to learn any projection technique. We demonstrate our proposal on several real-world high dimensional datasets from machine learning.