 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Concepts and their Function in a Large Language Model
Apr 09, 2026Large language models (LLMs) sometimes appear to exhibit emotional reactions. We investigate why this is the case in Claude Sonnet 4.5 and explore implications for alignment-relevant behavior. We find internal representations of emotion concepts, which encode the broad concept of a particular emotion and generalize across contexts and behaviors it might be linked to. These representations track the operative emotion concept at a given token position in a conversation, activating in accordance with that emotion's relevance to processing the present context and predicting upcoming text. Our key finding is that these representations causally influence the LLM's outputs, including Claude's preferences and its rate of exhibiting misaligned behaviors such as reward hacking, blackmail, and sycophancy. We refer to this phenomenon as the LLM exhibiting functional emotions: patterns of expression and behavior modeled after humans under the influence of an emotion, which are mediated by underlying abstract representations of emotion concepts. Functional emotions may work quite differently from human emotions, and do not imply that LLMs have any subjective experience of emotions, but appear to be important for understanding the model's behavior.
Neurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
Jan 19, 2026Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.
LoX: Low-Rank Extrapolation Robustifies LLM Safety Against Fine-tuning
Jun 18, 2025Large Language Models (LLMs) have become indispensable in real-world applications. However, their widespread adoption raises significant safety concerns, particularly in responding to socially harmful questions. Despite substantial efforts to improve model safety through alignment, aligned models can still have their safety protections undermined by subsequent fine-tuning - even when the additional training data appears benign. In this paper, we empirically demonstrate that this vulnerability stems from the sensitivity of safety-critical low-rank subspaces in LLM parameters to fine-tuning. Building on this insight, we propose a novel training-free method, termed Low-Rank Extrapolation (LoX), to enhance safety robustness by extrapolating the safety subspace of an aligned LLM. Our experimental results confirm the effectiveness of LoX, demonstrating significant improvements in robustness against both benign and malicious fine-tuning attacks while preserving the model's adaptability to new tasks. For instance, LoX leads to 11% to 54% absolute reductions in attack success rates (ASR) facing benign or malicious fine-tuning attacks. By investigating the ASR landscape of parameters, we attribute the success of LoX to that the extrapolation moves LLM parameters to a flatter zone, thereby less sensitive to perturbations. The code is available at github.com/VITA-Group/LoX.
Learning Along the Arrow of Time: Hyperbolic Geometry for Backward-Compatible Representation Learning
Jun 06, 2025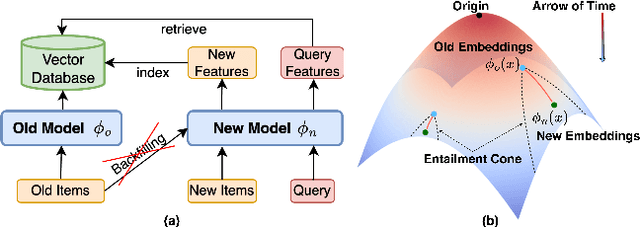
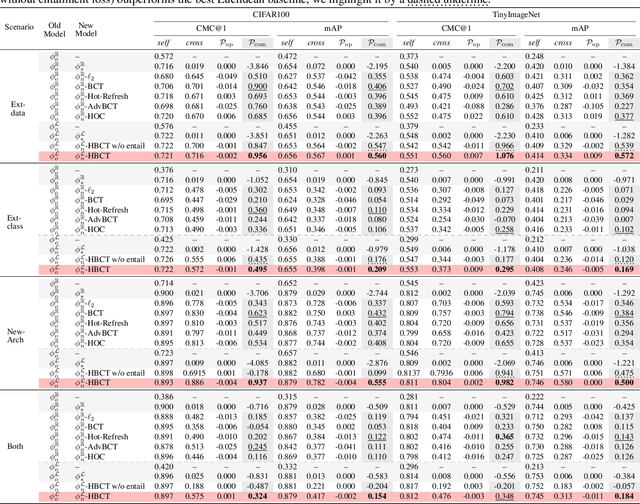
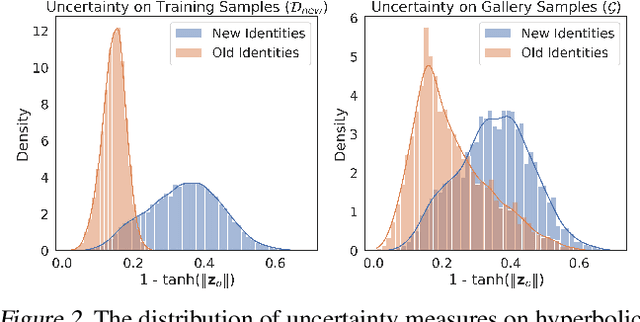
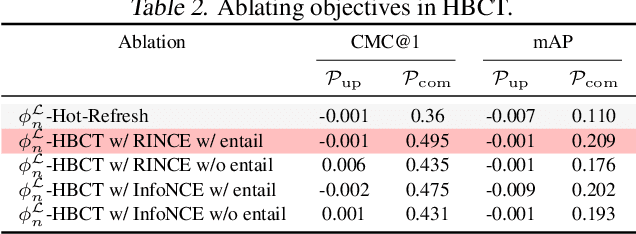
Backward compatible representation learning enables updated models to integrate seamlessly with existing ones, avoiding to reprocess stored data. Despite recent advances, existing compatibility approaches in Euclidean space neglect the uncertainty in the old embedding model and force the new model to reconstruct outdated representations regardless of their quality, thereby hindering the learning process of the new model. In this paper, we propose to switch perspectives to hyperbolic geometry, where we treat time as a natural axis for capturing a model's confidence and evolution. By lifting embeddings into hyperbolic space and constraining updated embeddings to lie within the entailment cone of the old ones, we maintain generational consistency across models while accounting for uncertainties in the representations. To further enhance compatibility, we introduce a robust contrastive alignment loss that dynamically adjusts alignment weights based on the uncertainty of the old embeddings. Experiments validate the superiority of the proposed method in achieving compatibility, paving the way for more resilient and adaptable machine learning systems.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
May 26, 2025The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.
More is Less: The Pitfalls of Multi-Model Synthetic Preference Data in DPO Safety Alignment
Apr 03, 2025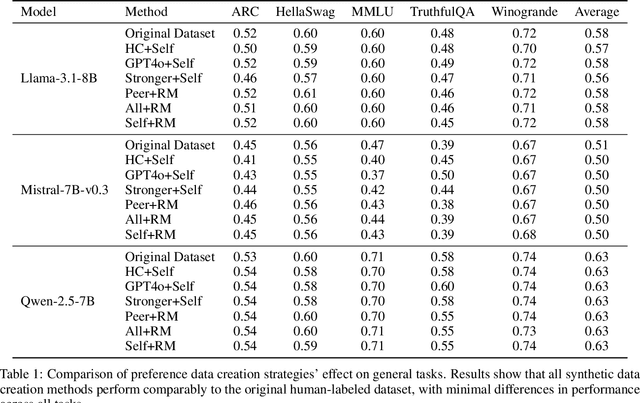
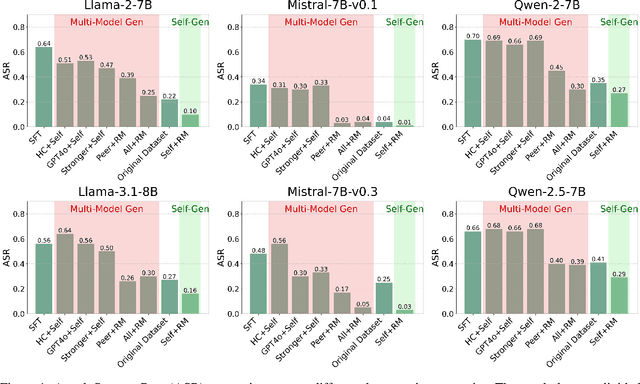
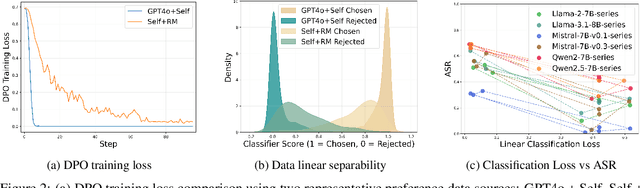

Aligning large language models (LLMs) with human values is an increasingly critical step in post-training. Direct Preference Optimization (DPO) has emerged as a simple, yet effective alternative to reinforcement learning from human feedback (RLHF). Synthetic preference data with its low cost and high quality enable effective alignment through single- or multi-model generated preference data. Our study reveals a striking, safety-specific phenomenon associated with DPO alignment: Although multi-model generated data enhances performance on general tasks (ARC, Hellaswag, MMLU, TruthfulQA, Winogrande) by providing diverse responses, it also tends to facilitate reward hacking during training. This can lead to a high attack success rate (ASR) when models encounter jailbreaking prompts. The issue is particularly pronounced when employing stronger models like GPT-4o or larger models in the same family to generate chosen responses paired with target model self-generated rejected responses, resulting in dramatically poorer safety outcomes. Furthermore, with respect to safety, using solely self-generated responses (single-model generation) for both chosen and rejected pairs significantly outperforms configurations that incorporate responses from stronger models, whether used directly as chosen data or as part of a multi-model response pool. We demonstrate that multi-model preference data exhibits high linear separability between chosen and rejected responses, which allows models to exploit superficial cues rather than internalizing robust safety constraints. Our experiments, conducted on models from the Llama, Mistral, and Qwen families, consistently validate these findings.
Extracting and Understanding the Superficial Knowledge in Alignment
Feb 07, 2025



Alignment of large language models (LLMs) with human values and preferences, often achieved through fine-tuning based on human feedback, is essential for ensuring safe and responsible AI behaviors. However, the process typically requires substantial data and computation resources. Recent studies have revealed that alignment might be attainable at lower costs through simpler methods, such as in-context learning. This leads to the question: Is alignment predominantly superficial? In this paper, we delve into this question and provide a quantitative analysis. We formalize the concept of superficial knowledge, defining it as knowledge that can be acquired through easily token restyling, without affecting the model's ability to capture underlying causal relationships between tokens. We propose a method to extract and isolate superficial knowledge from aligned models, focusing on the shallow modifications to the final token selection process. By comparing models augmented only with superficial knowledge to fully aligned models, we quantify the superficial portion of alignment. Our findings reveal that while superficial knowledge constitutes a significant portion of alignment, particularly in safety and detoxification tasks, it is not the whole story. Tasks requiring reasoning and contextual understanding still rely on deeper knowledge. Additionally, we demonstrate two practical advantages of isolated superficial knowledge: (1) it can be transferred between models, enabling efficient offsite alignment of larger models using extracted superficial knowledge from smaller models, and (2) it is recoverable, allowing for the restoration of alignment in compromised models without sacrificing performance.
GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender Systems
Dec 23, 2024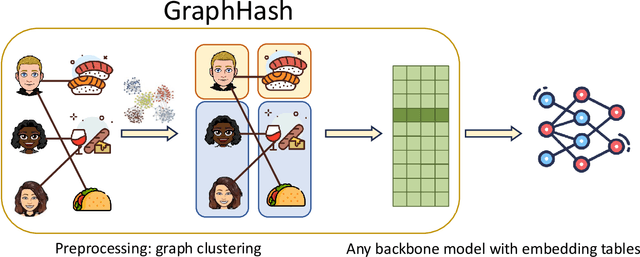
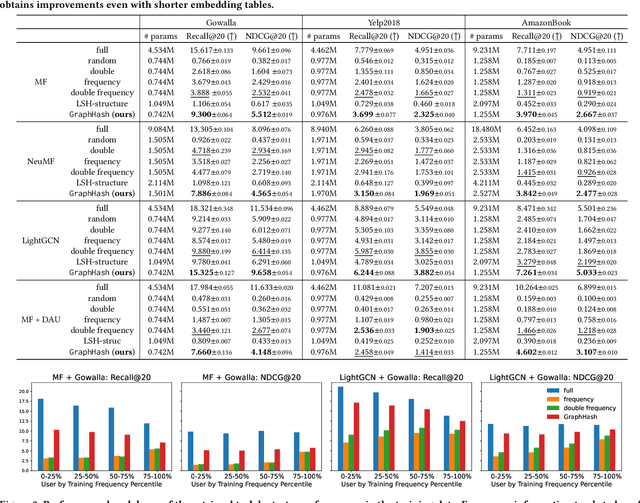
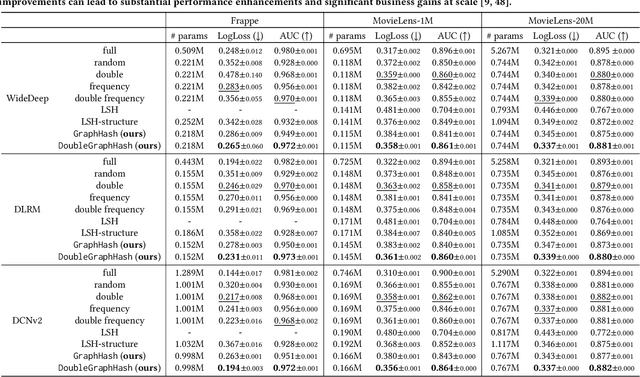
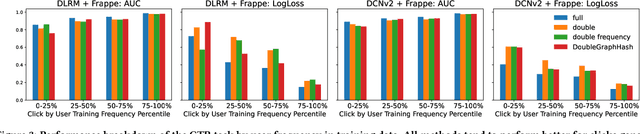
Deep recommender systems rely heavily on large embedding tables to handle high-cardinality categorical features such as user/item identifiers, and face significant memory constraints at scale. To tackle this challenge, hashing techniques are often employed to map multiple entities to the same embedding and thus reduce the size of the embedding tables. Concurrently, graph-based collaborative signals have emerged as powerful tools in recommender systems, yet their potential for optimizing embedding table reduction remains unexplored. This paper introduces GraphHash, the first graph-based approach that leverages modularity-based bipartite graph clustering on user-item interaction graphs to reduce embedding table sizes. We demonstrate that the modularity objective has a theoretical connection to message-passing, which provides a foundation for our method. By employing fast clustering algorithms, GraphHash serves as a computationally efficient proxy for message-passing during preprocessing and a plug-and-play graph-based alternative to traditional ID hashing. Extensive experiments show that GraphHash substantially outperforms diverse hashing baselines on both retrieval and click-through-rate prediction tasks. In particular, GraphHash achieves on average a 101.52% improvement in recall when reducing the embedding table size by more than 75%, highlighting the value of graph-based collaborative information for model reduction.
Enhancing Item Tokenization for Generative Recommendation through Self-Improvement
Dec 22, 2024



Generative recommendation systems, driven by large language models (LLMs), present an innovative approach to predicting user preferences by modeling items as token sequences and generating recommendations in a generative manner. A critical challenge in this approach is the effective tokenization of items, ensuring that they are represented in a form compatible with LLMs. Current item tokenization methods include using text descriptions, numerical strings, or sequences of discrete tokens. While text-based representations integrate seamlessly with LLM tokenization, they are often too lengthy, leading to inefficiencies and complicating accurate generation. Numerical strings, while concise, lack semantic depth and fail to capture meaningful item relationships. Tokenizing items as sequences of newly defined tokens has gained traction, but it often requires external models or algorithms for token assignment. These external processes may not align with the LLM's internal pretrained tokenization schema, leading to inconsistencies and reduced model performance. To address these limitations, we propose a self-improving item tokenization method that allows the LLM to refine its own item tokenizations during training process. Our approach starts with item tokenizations generated by any external model and periodically adjusts these tokenizations based on the LLM's learned patterns. Such alignment process ensures consistency between the tokenization and the LLM's internal understanding of the items, leading to more accurate recommendations. Furthermore, our method is simple to implement and can be integrated as a plug-and-play enhancement into existing generative recommendation systems. Experimental results on multiple datasets and using various initial tokenization strategies demonstrate the effectiveness of our method, with an average improvement of 8\% in recommendation performance.
Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding
Mar 05, 2024



This paper aims to overcome the "lost-in-the-middle" challenge of large language models (LLMs). While recent advancements have successfully enabled LLMs to perform stable language modeling with up to 4 million tokens, the persistent difficulty faced by most LLMs in identifying relevant information situated in the middle of the context has not been adequately tackled. To address this problem, this paper introduces Multi-scale Positional Encoding (Ms-PoE) which is a simple yet effective plug-and-play approach to enhance the capacity of LLMs to handle the relevant information located in the middle of the context, without fine-tuning or introducing any additional overhead. Ms-PoE leverages the position indice rescaling to relieve the long-term decay effect introduced by RoPE, while meticulously assigning distinct scaling ratios to different attention heads to preserve essential knowledge learned during the pre-training step, forming a multi-scale context fusion from short to long distance. Extensive experiments with a wide range of LLMs demonstrate the efficacy of our approach. Notably, Ms-PoE achieves an average accuracy gain of up to 3.8 on the Zero-SCROLLS benchmark over the original LLMs. Code are available at https://github.com/VITA-Group/Ms-PoE.