 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent circuits as multi-path ensembles for modeling responses of early visual cortical neurons
Oct 02, 2021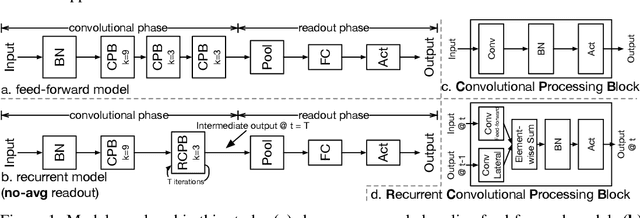

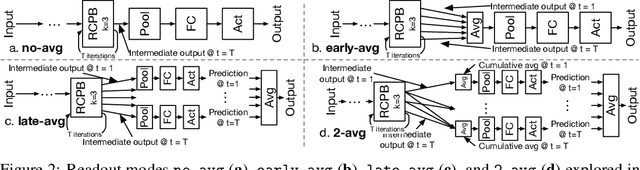
In this paper, we showed that adding within-layer recurrent connections to feed-forward neural network models could improve the performance of neural response prediction in early visual areas by up to 11 percent across different data sets and over tens of thousands of model configurations. To understand why recurrent models perform better, we propose that recurrent computation can be conceptualized as an ensemble of multiple feed-forward pathways of different lengths with shared parameters. By reformulating a recurrent model as a multi-path model and analyzing the recurrent model through its multi-path ensemble, we found that the recurrent model outperformed the corresponding feed-forward one due to the former's compact and implicit multi-path ensemble that allows approximating the complex function underlying recurrent biological circuits with efficiency. In addition, we found that the performance differences among recurrent models were highly correlated with the differences in their multi-path ensembles in terms of path lengths and path diversity; a balance of paths of different lengths in the ensemble was necessary for the model to achieve the best performance. Our studies shed light on the computational rationales and advantages of recurrent circuits for neural modeling and machine learning tasks in general.
A Neurally-Inspired Hierarchical Prediction Network for Spatiotemporal Sequence Learning and Prediction
Jan 25, 2019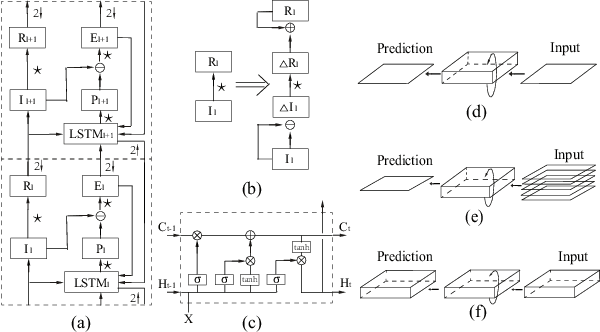
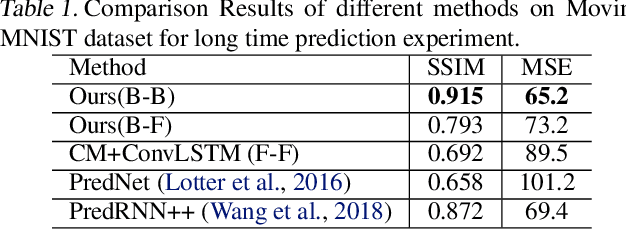
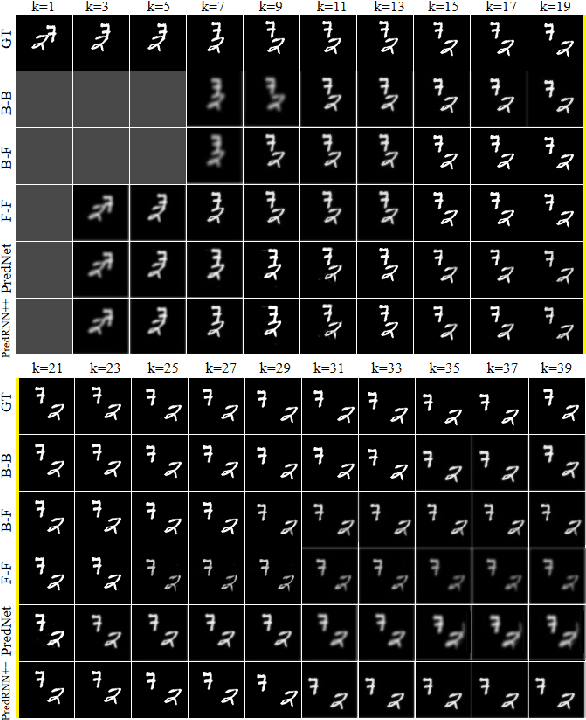

In this paper we developed a hierarchical network model, called Hierarchical Prediction Network (HPNet), to understand how spatiotemporal memories might be learned and encoded in the recurrent circuits in the visual cortical hierarchy for predicting future video frames. This neurally inspired model operates in the analysis-by-synthesis framework. It contains a feed-forward path that computes and encodes spatiotemporal features of successive complexity and a feedback path for the successive levels to project their interpretations to the level below. Within each level, the feed-forward path and the feedback path intersect in a recurrent gated circuit, instantiated in a LSTM module, to generate a prediction or explanation of the incoming signals. The network learns its internal model of the world by minimizing the errors of its prediction of the incoming signals at each level of the hierarchy. We found that hierarchical interaction in the network increases semantic clustering of global movement patterns in the population codes of the units along the hierarchy, even in the earliest module. This facilitates the learning of relationships among movement patterns, yielding state-of-the-art performance in long range video sequence predictions in the benchmark datasets. The network model automatically reproduces a variety of prediction suppression and familiarity suppression neurophysiological phenomena observed in the visual cortex, suggesting that hierarchical prediction might indeed be an important principle for representational learning in the visual cortex.
Explaining Neural Networks Semantically and Quantitatively
Dec 18, 2018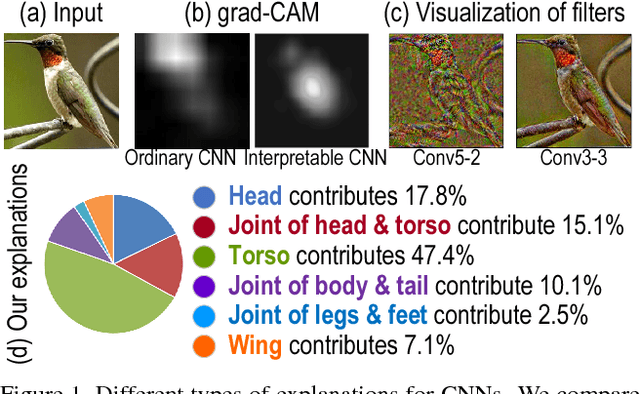



This paper presents a method to explain the knowledge encoded in a convolutional neural network (CNN) quantitatively and semantically. The analysis of the specific rationale of each prediction made by the CNN presents a key issue of understanding neural networks, but it is also of significant practical values in certain applications. In this study, we propose to distill knowledge from the CNN into an explainable additive model, so that we can use the explainable model to provide a quantitative explanation for the CNN prediction. We analyze the typical bias-interpreting problem of the explainable model and develop prior losses to guide the learning of the explainable additive model. Experimental results have demonstrated the effectiveness of our method.