 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neurally-Inspired Hierarchical Prediction Network for Spatiotemporal Sequence Learning and Prediction
Paper and Code
Jan 25, 2019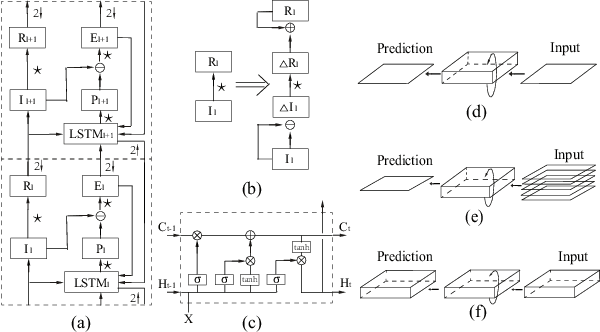
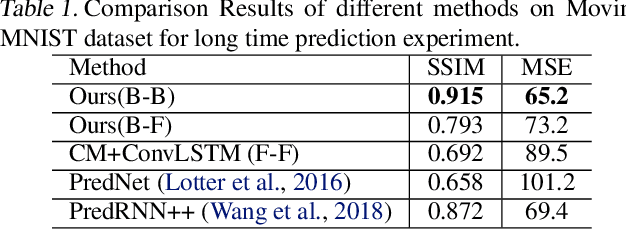
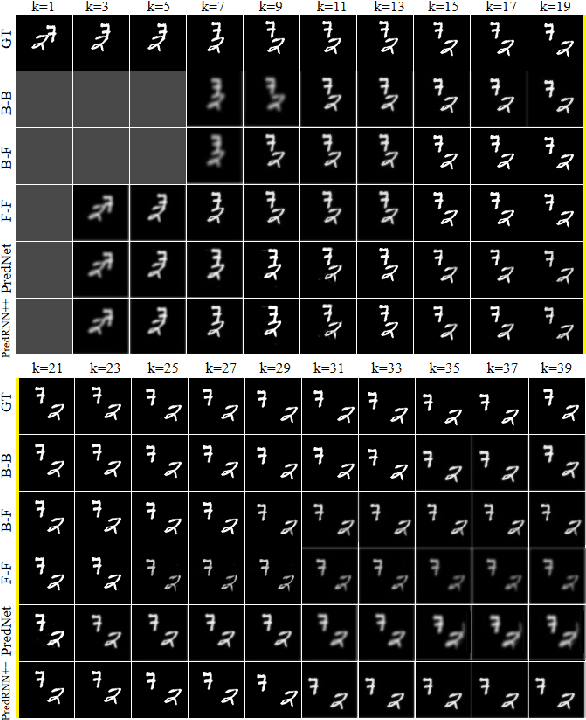

In this paper we developed a hierarchical network model, called Hierarchical Prediction Network (HPNet), to understand how spatiotemporal memories might be learned and encoded in the recurrent circuits in the visual cortical hierarchy for predicting future video frames. This neurally inspired model operates in the analysis-by-synthesis framework. It contains a feed-forward path that computes and encodes spatiotemporal features of successive complexity and a feedback path for the successive levels to project their interpretations to the level below. Within each level, the feed-forward path and the feedback path intersect in a recurrent gated circuit, instantiated in a LSTM module, to generate a prediction or explanation of the incoming signals. The network learns its internal model of the world by minimizing the errors of its prediction of the incoming signals at each level of the hierarchy. We found that hierarchical interaction in the network increases semantic clustering of global movement patterns in the population codes of the units along the hierarchy, even in the earliest module. This facilitates the learning of relationships among movement patterns, yielding state-of-the-art performance in long range video sequence predictions in the benchmark datasets. The network model automatically reproduces a variety of prediction suppression and familiarity suppression neurophysiological phenomena observed in the visual cortex, suggesting that hierarchical prediction might indeed be an important principle for representational learning in the visual cortex.