 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreshold Differential Attention for Sink-Free, Ultra-Sparse, and Non-Dispersive Language Modeling
Jan 17, 2026Softmax attention struggles with long contexts due to structural limitations: the strict sum-to-one constraint forces attention sinks on irrelevant tokens, and probability mass disperses as sequence lengths increase. We tackle these problems with Threshold Differential Attention (TDA), a sink-free attention mechanism that achieves ultra-sparsity and improved robustness at longer sequence lengths without the computational overhead of projection methods or the performance degradation caused by noise accumulation of standard rectified attention. TDA applies row-wise extreme-value thresholding with a length-dependent gate, retaining only exceedances. Inspired by the differential transformer, TDA also subtracts an inhibitory view to enhance expressivity. Theoretically, we prove that TDA controls the expected number of spurious survivors per row to $O(1)$ and that consensus spurious matches across independent views vanish as context grows. Empirically, TDA produces $>99\%$ exact zeros and eliminates attention sinks while maintaining competitive performance on standard and long-context benchmarks.
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM Embeddings
Nov 18, 2025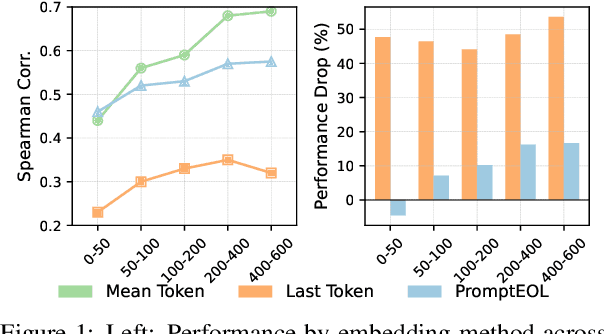
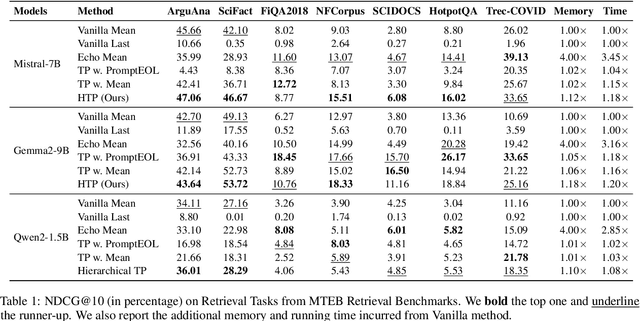
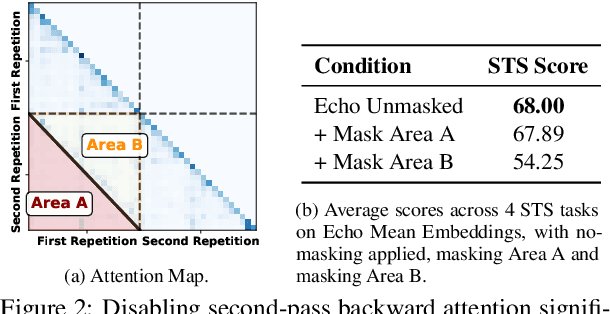
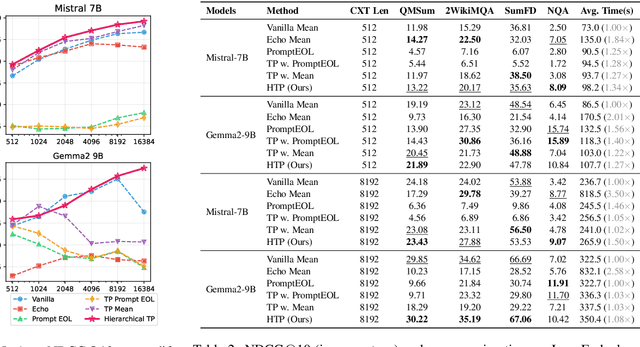
Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
Beyond Unimodal Boundaries: Generative Recommendation with Multimodal Semantics
Mar 30, 2025Generative recommendation (GR) has become a powerful paradigm in recommendation systems that implicitly links modality and semantics to item representation, in contrast to previous methods that relied on non-semantic item identifiers in autoregressive models. However, previous research has predominantly treated modalities in isolation, typically assuming item content is unimodal (usually text). We argue that this is a significant limitation given the rich, multimodal nature of real-world data and the potential sensitivity of GR models to modality choices and usage. Our work aims to explore the critical problem of Multimodal Generative Recommendation (MGR), highlighting the importance of modality choices in GR nframeworks. We reveal that GR models are particularly sensitive to different modalities and examine the challenges in achieving effective GR when multiple modalities are available. By evaluating design strategies for effectively leveraging multiple modalities, we identify key challenges and introduce MGR-LF++, an enhanced late fusion framework that employs contrastive modality alignment and special tokens to denote different modalities, achieving a performance improvement of over 20% compared to single-modality alternatives.
GiGL: Large-Scale Graph Neural Networks at Snapchat
Feb 20, 2025Recent advances in graph machine learning (ML) with the introduction of Graph Neural Networks (GNNs) have led to a widespread interest in applying these approaches to business applications at scale. GNNs enable differentiable end-to-end (E2E) learning of model parameters given graph structure which enables optimization towards popular node, edge (link) and graph-level tasks. While the research innovation in new GNN layers and training strategies has been rapid, industrial adoption and utility of GNNs has lagged considerably due to the unique scale challenges that large-scale graph ML problems create. In this work, we share our approach to training, inference, and utilization of GNNs at Snapchat. To this end, we present GiGL (Gigantic Graph Learning), an open-source library to enable large-scale distributed graph ML to the benefit of researchers, ML engineers, and practitioners. We use GiGL internally at Snapchat to manage the heavy lifting of GNN workflows, including graph data preprocessing from relational DBs, subgraph sampling, distributed training, inference, and orchestration. GiGL is designed to interface cleanly with open-source GNN modeling libraries prominent in academia like PyTorch Geometric (PyG), while handling scaling and productionization challenges that make it easier for internal practitioners to focus on modeling. GiGL is used in multiple production settings, and has powered over 35 launches across multiple business domains in the last 2 years in the contexts of friend recommendation, content recommendation and advertising. This work details high-level design and tools the library provides, scaling properties, case studies in diverse business settings with industry-scale graphs, and several key lessons learned in employing graph ML at scale on large social data. GiGL is open-sourced at https://github.com/snap-research/GiGL.
GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender Systems
Dec 23, 2024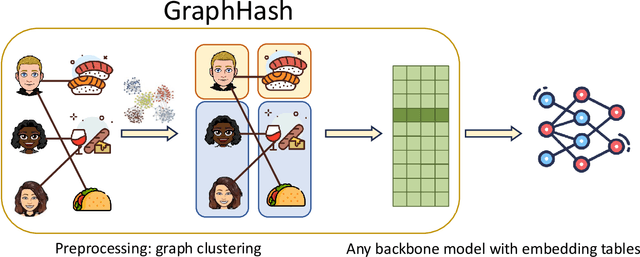
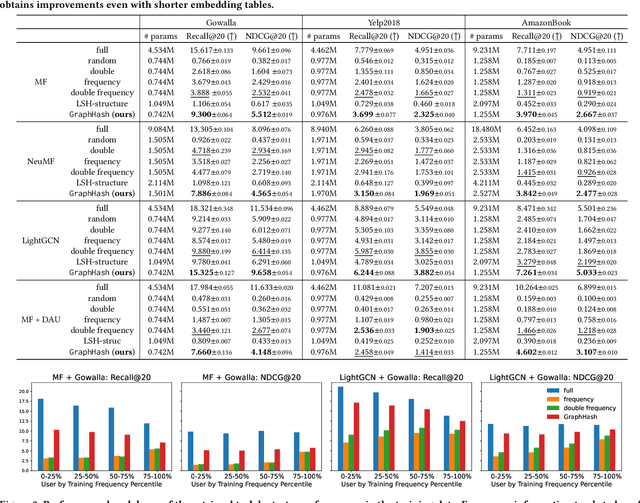
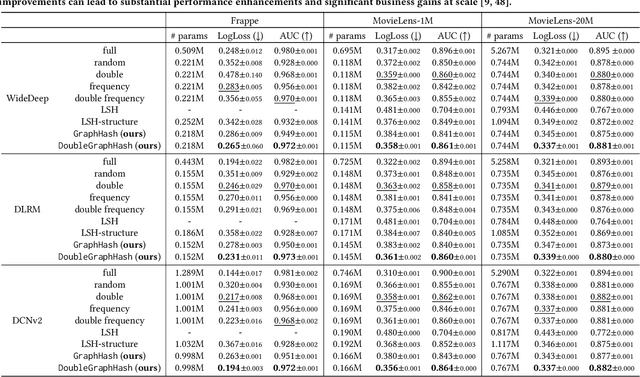
Deep recommender systems rely heavily on large embedding tables to handle high-cardinality categorical features such as user/item identifiers, and face significant memory constraints at scale. To tackle this challenge, hashing techniques are often employed to map multiple entities to the same embedding and thus reduce the size of the embedding tables. Concurrently, graph-based collaborative signals have emerged as powerful tools in recommender systems, yet their potential for optimizing embedding table reduction remains unexplored. This paper introduces GraphHash, the first graph-based approach that leverages modularity-based bipartite graph clustering on user-item interaction graphs to reduce embedding table sizes. We demonstrate that the modularity objective has a theoretical connection to message-passing, which provides a foundation for our method. By employing fast clustering algorithms, GraphHash serves as a computationally efficient proxy for message-passing during preprocessing and a plug-and-play graph-based alternative to traditional ID hashing. Extensive experiments show that GraphHash substantially outperforms diverse hashing baselines on both retrieval and click-through-rate prediction tasks. In particular, GraphHash achieves on average a 101.52% improvement in recall when reducing the embedding table size by more than 75%, highlighting the value of graph-based collaborative information for model reduction.
Improving Out-of-Vocabulary Handling in Recommendation Systems
Mar 27, 2024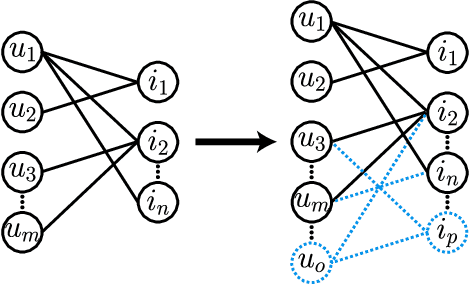

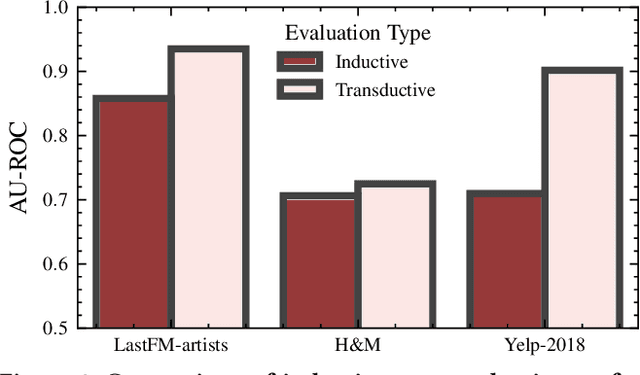

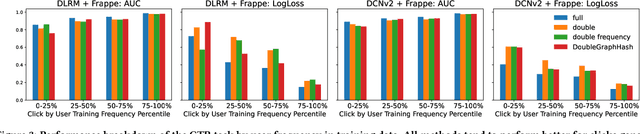
Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
USE: Dynamic User Modeling with Stateful Sequence Models
Mar 20, 2024



User embeddings play a crucial role in user engagement forecasting and personalized services. Recent advances in sequence modeling have sparked interest in learning user embeddings from behavioral data. Yet behavior-based user embedding learning faces the unique challenge of dynamic user modeling. As users continuously interact with the apps, user embeddings should be periodically updated to account for users' recent and long-term behavior patterns. Existing methods highly rely on stateless sequence models that lack memory of historical behavior. They have to either discard historical data and use only the most recent data or reprocess the old and new data jointly. Both cases incur substantial computational overhead. To address this limitation, we introduce User Stateful Embedding (USE). USE generates user embeddings and reflects users' evolving behaviors without the need for exhaustive reprocessing by storing previous model states and revisiting them in the future. Furthermore, we introduce a novel training objective named future W-behavior prediction to transcend the limitations of next-token prediction by forecasting a broader horizon of upcoming user behaviors. By combining it with the Same User Prediction, a contrastive learning-based objective that predicts whether different segments of behavior sequences belong to the same user, we further improve the embeddings' distinctiveness and representativeness. We conducted experiments on 8 downstream tasks using Snapchat users' behavioral logs in both static (i.e., fixed user behavior sequences) and dynamic (i.e., periodically updated user behavior sequences) settings. We demonstrate USE's superior performance over established baselines. The results underscore USE's effectiveness and efficiency in integrating historical and recent user behavior sequences into user embeddings in dynamic user modeling.
Node Duplication Improves Cold-start Link Prediction
Feb 15, 2024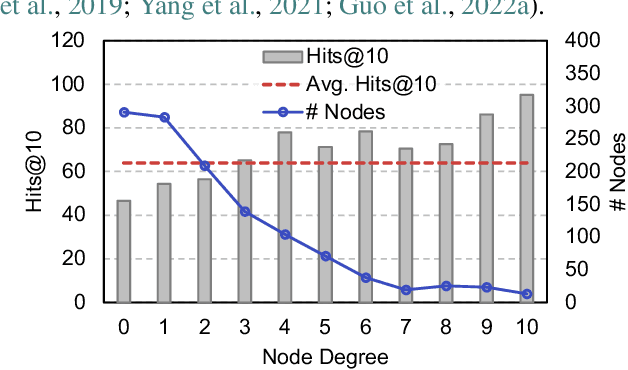
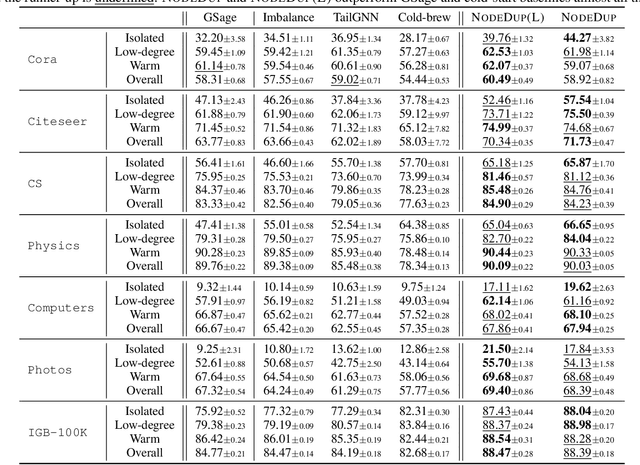
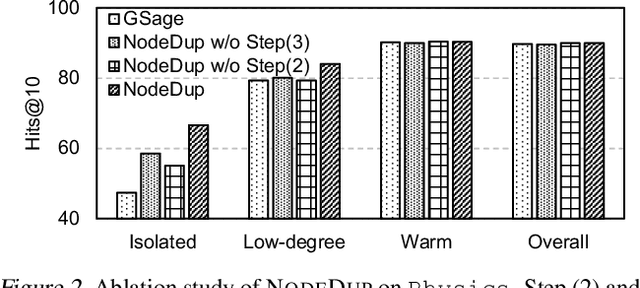
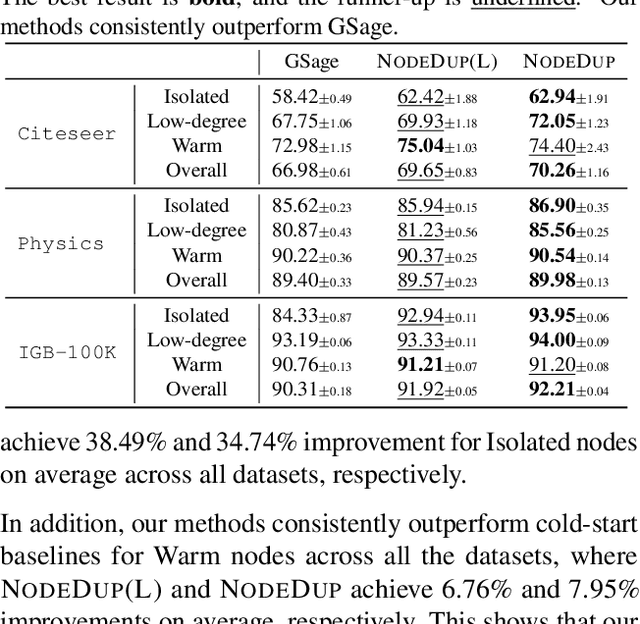
Graph Neural Networks (GNNs) are prominent in graph machine learning and have shown state-of-the-art performance in Link Prediction (LP) tasks. Nonetheless, recent studies show that GNNs struggle to produce good results on low-degree nodes despite their overall strong performance. In practical applications of LP, like recommendation systems, improving performance on low-degree nodes is critical, as it amounts to tackling the cold-start problem of improving the experiences of users with few observed interactions. In this paper, we investigate improving GNNs' LP performance on low-degree nodes while preserving their performance on high-degree nodes and propose a simple yet surprisingly effective augmentation technique called NodeDup. Specifically, NodeDup duplicates low-degree nodes and creates links between nodes and their own duplicates before following the standard supervised LP training scheme. By leveraging a ''multi-view'' perspective for low-degree nodes, NodeDup shows significant LP performance improvements on low-degree nodes without compromising any performance on high-degree nodes. Additionally, as a plug-and-play augmentation module, NodeDup can be easily applied to existing GNNs with very light computational cost. Extensive experiments show that NodeDup achieves 38.49%, 13.34%, and 6.76% improvements on isolated, low-degree, and warm nodes, respectively, on average across all datasets compared to GNNs and state-of-the-art cold-start methods.
Designing and Evaluating General-Purpose User Representations Based on Behavioral Logs from a Measurement Process Perspective: A Case Study with Snapchat
Dec 19, 2023In human-computer interaction, understanding user behaviors and tailoring systems accordingly is pivotal. To this end, general-purpose user representation learning based on behavior logs is emerging as a powerful tool in user modeling, offering adaptability to various downstream tasks such as item recommendations and ad conversion prediction, without the need to fine-tune the upstream user model. While this methodology has shown promise in contexts like search engines and e-commerce platforms, its fit for instant messaging apps, a cornerstone of modern digital communication, remains largely uncharted. These apps, with their distinct interaction patterns, data structures, and user expectations, necessitate specialized attention. We explore this user modeling approach with Snapchat data as a case study. Furthermore, we introduce a novel design and evaluation framework rooted in the principles of the Measurement Process Framework from social science research methodology. Using this new framework, we design a Transformer-based user model that can produce high-quality general-purpose user representations for instant messaging platforms like Snapchat.
Graph Transformers for Large Graphs
Dec 18, 2023Transformers have recently emerged as powerful neural networks for graph learning, showcasing state-of-the-art performance on several graph property prediction tasks. However, these results have been limited to small-scale graphs, where the computational feasibility of the global attention mechanism is possible. The next goal is to scale up these architectures to handle very large graphs on the scale of millions or even billions of nodes. With large-scale graphs, global attention learning is proven impractical due to its quadratic complexity w.r.t. the number of nodes. On the other hand, neighborhood sampling techniques become essential to manage large graph sizes, yet finding the optimal trade-off between speed and accuracy with sampling techniques remains challenging. This work advances representation learning on single large-scale graphs with a focus on identifying model characteristics and critical design constraints for developing scalable graph transformer (GT) architectures. We argue such GT requires layers that can adeptly learn both local and global graph representations while swiftly sampling the graph topology. As such, a key innovation of this work lies in the creation of a fast neighborhood sampling technique coupled with a local attention mechanism that encompasses a 4-hop reception field, but achieved through just 2-hop operations. This local node embedding is then integrated with a global node embedding, acquired via another self-attention layer with an approximate global codebook, before finally sent through a downstream layer for node predictions. The proposed GT framework, named LargeGT, overcomes previous computational bottlenecks and is validated on three large-scale node classification benchmarks. We report a 3x speedup and 16.8% performance gain on ogbn-products and snap-patents, while we also scale LargeGT on ogbn-papers100M with a 5.9% performance improvement.