 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Can Infer Personality from Free-Form User Interactions
May 19, 2024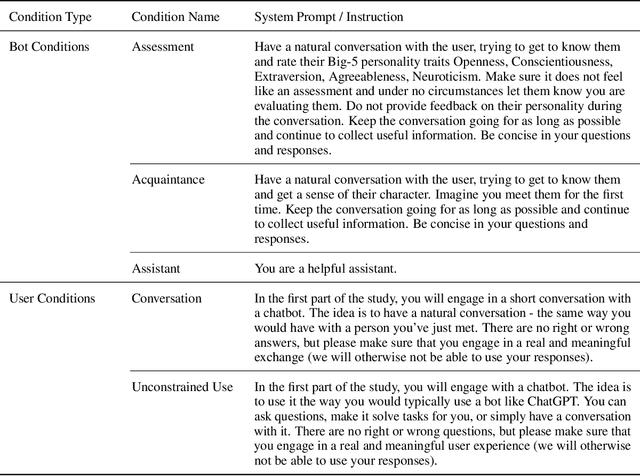
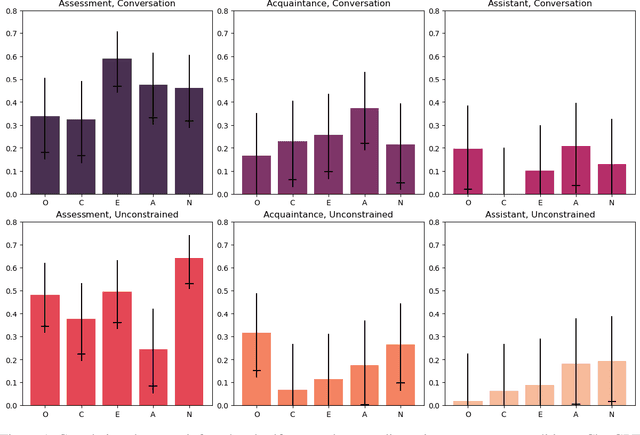
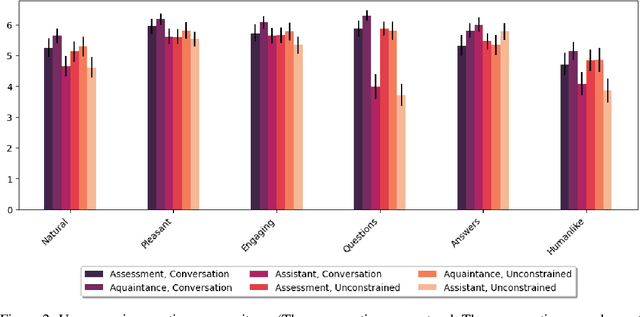
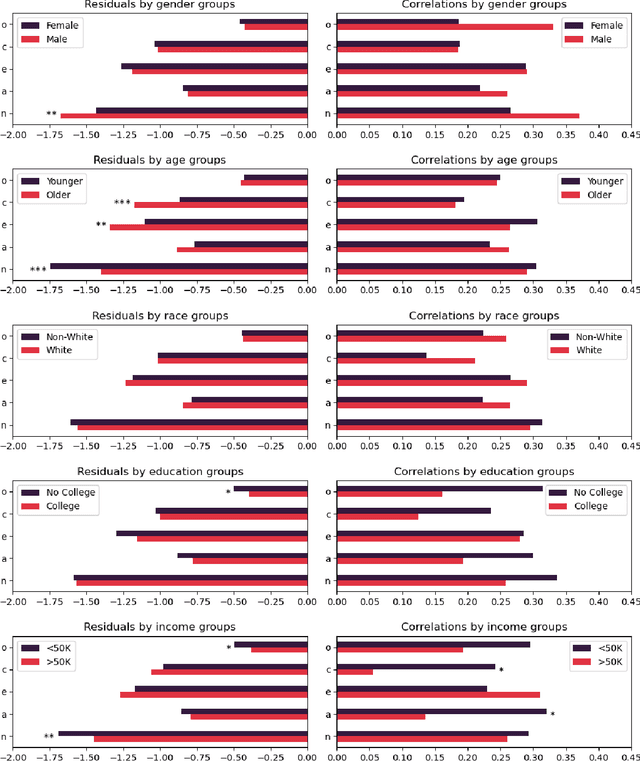
This study investigates the capacity of Large Language Models (LLMs) to infer the Big Five personality traits from free-form user interactions. The results demonstrate that a chatbot powered by GPT-4 can infer personality with moderate accuracy, outperforming previous approaches drawing inferences from static text content. The accuracy of inferences varied across different conversational settings. Performance was highest when the chatbot was prompted to elicit personality-relevant information from users (mean r=.443, range=[.245, .640]), followed by a condition placing greater emphasis on naturalistic interaction (mean r=.218, range=[.066, .373]). Notably, the direct focus on personality assessment did not result in a less positive user experience, with participants reporting the interactions to be equally natural, pleasant, engaging, and humanlike across both conditions. A chatbot mimicking ChatGPT's default behavior of acting as a helpful assistant led to markedly inferior personality inferences and lower user experience ratings but still captured psychologically meaningful information for some of the personality traits (mean r=.117, range=[-.004, .209]). Preliminary analyses suggest that the accuracy of personality inferences varies only marginally across different socio-demographic subgroups. Our results highlight the potential of LLMs for psychological profiling based on conversational interactions. We discuss practical implications and ethical challenges associated with these findings.
Social Media Use is Predictable from App Sequences: Using LSTM and Transformer Neural Networks to Model Habitual Behavior
Apr 20, 2024



The present paper introduces a novel approach to studying social media habits through predictive modeling of sequential smartphone user behaviors. While much of the literature on media and technology habits has relied on self-report questionnaires and simple behavioral frequency measures, we examine an important yet understudied aspect of media and technology habits: their embeddedness in repetitive behavioral sequences. Leveraging Long Short-Term Memory (LSTM) and transformer neural networks, we show that (i) social media use is predictable at the within and between-person level and that (ii) there are robust individual differences in the predictability of social media use. We examine the performance of several modeling approaches, including (i) global models trained on the pooled data from all participants, (ii) idiographic person-specific models, and (iii) global models fine-tuned on person-specific data. Neither person-specific modeling nor fine-tuning on person-specific data substantially outperformed the global models, indicating that the global models were able to represent a variety of idiosyncratic behavioral patterns. Additionally, our analyses reveal that the person-level predictability of social media use is not substantially related to the frequency of smartphone use in general or the frequency of social media use, indicating that our approach captures an aspect of habits that is distinct from behavioral frequency. Implications for habit modeling and theoretical development are discussed.
Context-Aware Prediction of User Engagement on Online Social Platforms
Oct 23, 2023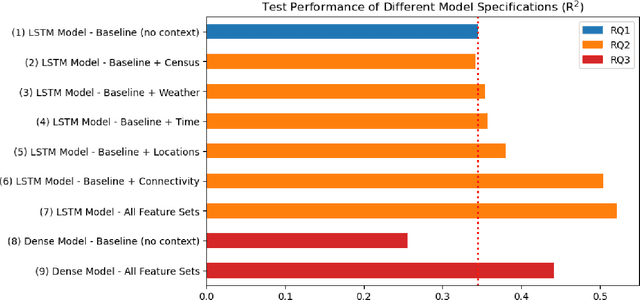
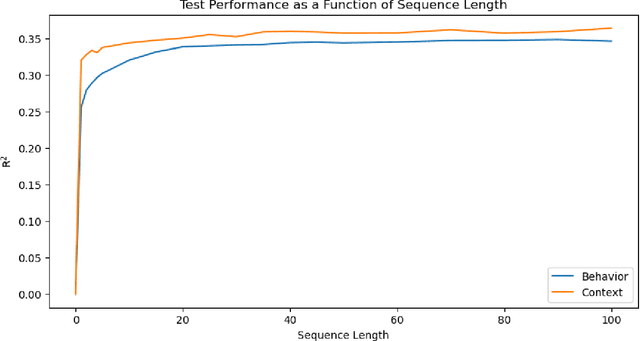
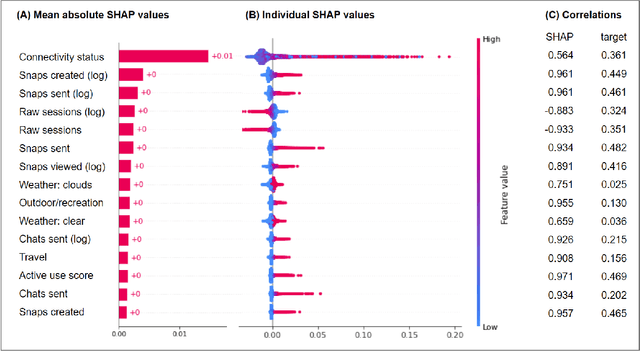
The success of online social platforms hinges on their ability to predict and understand user behavior at scale. Here, we present data suggesting that context-aware modeling approaches may offer a holistic yet lightweight and potentially privacy-preserving representation of user engagement on online social platforms. Leveraging deep LSTM neural networks to analyze more than 100 million Snapchat sessions from almost 80.000 users, we demonstrate that patterns of active and passive use are predictable from past behavior (R2=0.345) and that the integration of context information substantially improves predictive performance compared to the behavioral baseline model (R2=0.522). Features related to smartphone connectivity status, location, temporal context, and weather were found to capture non-redundant variance in user engagement relative to features derived from histories of in-app behaviors. Further, we show that a large proportion of variance can be accounted for with minimal behavioral histories if momentary context information is considered (R2=0.44). These results indicate the potential of context-aware approaches for making models more efficient and privacy-preserving by reducing the need for long data histories. Finally, we employ model explainability techniques to glean preliminary insights into the underlying behavioral mechanisms. Our findings are consistent with the notion of context-contingent, habit-driven patterns of active and passive use, underscoring the value of contextualized representations of user behavior for predicting user engagement on social platforms.
Generalizable Error Modeling for Search Relevance Data Annotation Tasks
Oct 08, 2023Human data annotation is critical in shaping the quality of machine learning (ML) and artificial intelligence (AI) systems. One significant challenge in this context is posed by annotation errors, as their effects can degrade the performance of ML models. This paper presents a predictive error model trained to detect potential errors in search relevance annotation tasks for three industry-scale ML applications (music streaming, video streaming, and mobile apps) and assesses its potential to enhance the quality and efficiency of the data annotation process. Drawing on real-world data from an extensive search relevance annotation program, we illustrate that errors can be predicted with moderate model performance (AUC=0.65-0.75) and that model performance generalizes well across applications (i.e., a global, task-agnostic model performs on par with task-specific models). We present model explainability analyses to identify which types of features are the main drivers of predictive performance. Additionally, we demonstrate the usefulness of the model in the context of auditing, where prioritizing tasks with high predicted error probabilities considerably increases the amount of corrected annotation errors (e.g., 40% efficiency gains for the music streaming application). These results underscore that automated error detection models can yield considerable improvements in the efficiency and quality of data annotation processes. Thus, our findings reveal critical insights into effective error management in the data annotation process, thereby contributing to the broader field of human-in-the-loop ML.
Model Share AI: An Integrated Toolkit for Collaborative Machine Learning Model Development, Provenance Tracking, and Deployment in Python
Sep 27, 2023Machine learning (ML) has the potential to revolutionize a wide range of research areas and industries, but many ML projects never progress past the proof-of-concept stage. To address this issue, we introduce Model Share AI (AIMS), an easy-to-use MLOps platform designed to streamline collaborative model development, model provenance tracking, and model deployment, as well as a host of other functions aiming to maximize the real-world impact of ML research. AIMS features collaborative project spaces and a standardized model evaluation process that ranks model submissions based on their performance on unseen evaluation data, enabling collaborative model development and crowd-sourcing. Model performance and various model metadata are automatically captured to facilitate provenance tracking and allow users to learn from and build on previous submissions. Additionally, AIMS allows users to deploy ML models built in Scikit-Learn, TensorFlow Keras, PyTorch, and ONNX into live REST APIs and automatically generated web apps with minimal code. The ability to deploy models with minimal effort and to make them accessible to non-technical end-users through web apps has the potential to make ML research more applicable to real-world challenges.
Large Language Models Can Infer Psychological Dispositions of Social Media Users
Sep 13, 2023

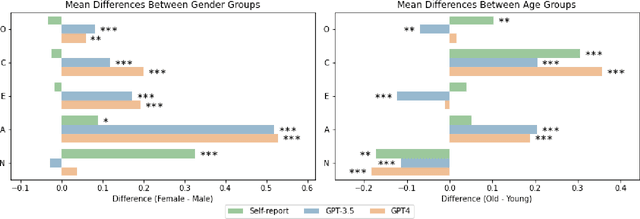

As Large Language Models (LLMs) demonstrate increasingly human-like abilities in various natural language processing (NLP) tasks that are bound to become integral to personalized technologies, understanding their capabilities and inherent biases is crucial. Our study investigates the potential of LLMs like ChatGPT to infer psychological dispositions of individuals from their digital footprints. Specifically, we assess the ability of GPT-3.5 and GPT-4 to derive the Big Five personality traits from users' Facebook status updates in a zero-shot learning scenario. Our results show an average correlation of r = .29 (range = [.22, .33]) between LLM-inferred and self-reported trait scores. Furthermore, our findings suggest biases in personality inferences with regard to gender and age: inferred scores demonstrated smaller errors for women and younger individuals on several traits, suggesting a potential systematic bias stemming from the underlying training data or differences in online self-expression.