 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Can Infer Psychological Dispositions of Social Media Users
Sep 13, 2023

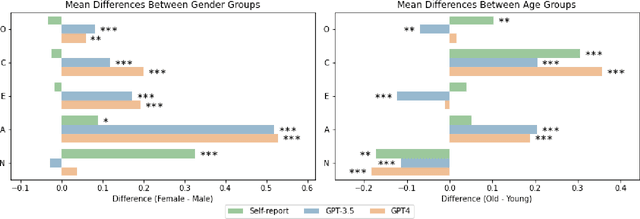

As Large Language Models (LLMs) demonstrate increasingly human-like abilities in various natural language processing (NLP) tasks that are bound to become integral to personalized technologies, understanding their capabilities and inherent biases is crucial. Our study investigates the potential of LLMs like ChatGPT to infer psychological dispositions of individuals from their digital footprints. Specifically, we assess the ability of GPT-3.5 and GPT-4 to derive the Big Five personality traits from users' Facebook status updates in a zero-shot learning scenario. Our results show an average correlation of r = .29 (range = [.22, .33]) between LLM-inferred and self-reported trait scores. Furthermore, our findings suggest biases in personality inferences with regard to gender and age: inferred scores demonstrated smaller errors for women and younger individuals on several traits, suggesting a potential systematic bias stemming from the underlying training data or differences in online self-expression.
Correcting Sociodemographic Selection Biases for Accurate Population Prediction from Social Media
Nov 10, 2019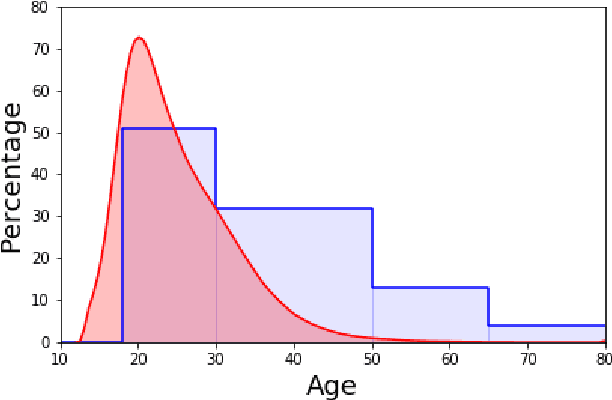
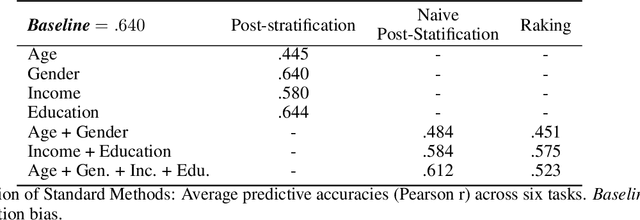
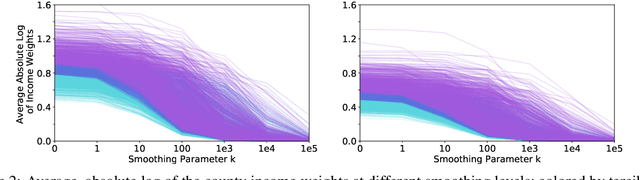
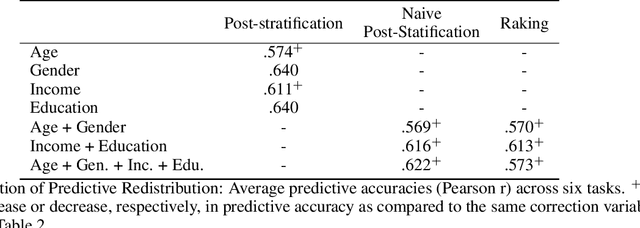
Social media is increasingly used for large-scale population predictions, such as estimating community health statistics. However, social media users are not typically a representative sample of the intended population --- a "selection bias". Across five tasks for predicting US county population health statistics from Twitter, we explore standard restratification techniques --- bias mitigation approaches that reweight people-specific variables according to how under-sampled their socio-demographic groups are. We found standard restratification provided no improvement and often degraded population prediction accuracy. The core reason for this seemed to be both shrunken and sparse estimates of each population's socio-demographics for which we thus develop and evaluate three methods to address: predictive redistribution to account for shrinking, as well as adaptive binning and informed smoothing to handle sparse socio-demographic estimates. We show each of our methods can significantly improve over the standard restratification approaches. Combining approaches, we find substantial improvements over non-restratified models as well, yielding a 35.4% increase in variance explained for predicting surveyed life satisfaction, and an 10.0% average increase across all tasks.
Latent Human Traits in the Language of Social Media: An Open-Vocabulary Approach
May 22, 2017
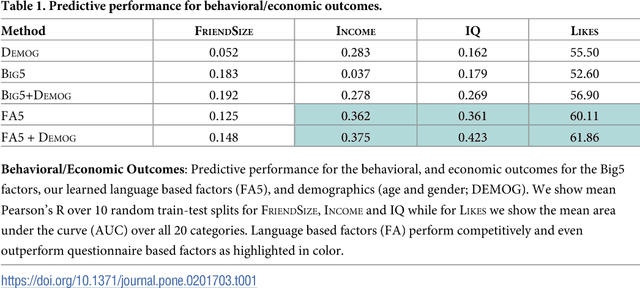
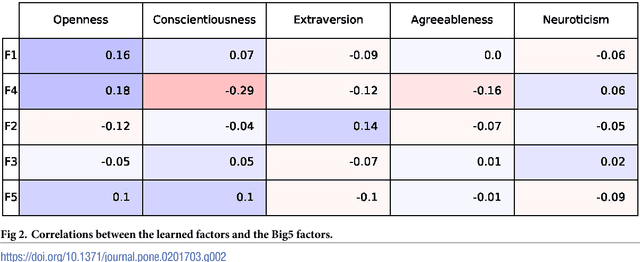

Over the past century, personality theory and research has successfully identified core sets of characteristics that consistently describe and explain fundamental differences in the way people think, feel and behave. Such characteristics were derived through theory, dictionary analyses, and survey research using explicit self-reports. The availability of social media data spanning millions of users now makes it possible to automatically derive characteristics from language use -- at large scale. Taking advantage of linguistic information available through Facebook, we study the process of inferring a new set of potential human traits based on unprompted language use. We subject these new traits to a comprehensive set of evaluations and compare them with a popular five factor model of personality. We find that our language-based trait construct is often more generalizable in that it often predicts non-questionnaire-based outcomes better than questionnaire-based traits (e.g. entities someone likes, income and intelligence quotient), while the factors remain nearly as stable as traditional factors. Our approach suggests a value in new constructs of personality derived from everyday human language use.