 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposable Crystals: Controllable Materials Discovery via Concept Learning
May 14, 2026De novo crystal generation, a central task in materials discovery, aims to generate crystals that are simultaneously valid, stable, unique, and novel. Existing methods mainly rely on black-box stochastic sampling, providing limited control over how generated structures move beyond the observed distribution. In this paper, we introduce a concept-based compositional framework for crystal generation. We train a vector-quantized variational autoencoder to automatically discover a shared set of reusable crystal concepts, which serve as building blocks for guided generation. These learned concepts naturally exhibit interpretability from both local atomic environments and global symmetry patterns, and generalize to crystals from different distributions. By recombining such concepts, our framework enables controllable exploration of novel crystals beyond the training distribution, rather than relying solely on unconstrained random sampling. To further improve composition efficiency, we introduce a composition generator and iteratively refine it using high-quality samples generated by the model itself. The resulting concept compositions are then used to condition downstream crystal generation. Numerical experiments on MP-20 and Alex-MP-20 show that compositing concepts separately increase base model up to 53.2% and 51.7% on V.S.U.N metric, with particular gains in novelty.
Crys-JEPA: Accelerating Crystal Discovery via Embedding Screening and Generative Refinement
May 14, 2026De novo crystal generation seeks to discover materials that are not merely realistic, but also stable and novel. However, most existing generative models are trained to maximize the likelihood of observed crystals, which encourages samples to stay close to known materials yet not necessarily align with the criteria that matter in discovery. Through an empirical investigation, we show that current crystal generative models are caught in a pronounced stability--novelty trade-off: moving toward the observed distribution preserves stability but limits novelty, whereas moving away from it quickly destroys stability. This suggests that the useful region for discovering crystals that are both stable and novel is extremely narrow. To escape the trade-off, we introduce Crys-JEPA, a joint embedding predictive architecture for crystals that learns an energy-aware latent space preserving formation-energy differences. In this space, stability assessment can be reformulated as an embedding-based comparison against accessible training crystals, reducing the reliance on expensive energy evaluation and task-specific external references. Building on Crys-JEPA, we further develop a screening-and-refinement pipeline that identifies promising generated crystals and reintroduces them to refine the generative model. On MP-20 and Alex-MP-20 datasets, we achieve improvements over baselines up to 81.4% and 82.6% on V.S.U.N metric, respectively.
Advancing Graph Convolutional Networks via General Spectral Wavelets
May 22, 2024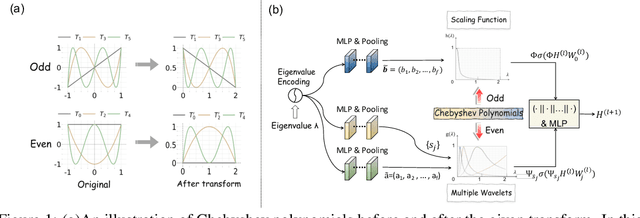

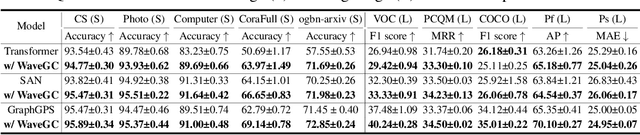
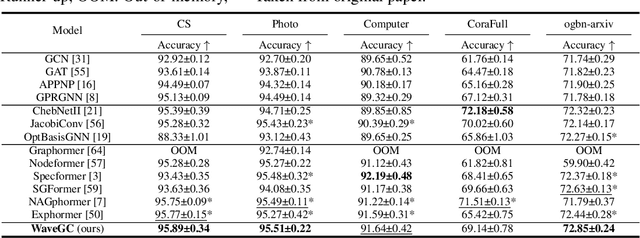
Spectral graph convolution, an important tool of data filtering on graphs, relies on two essential decisions; selecting spectral bases for signal transformation and parameterizing the kernel for frequency analysis. While recent techniques mainly focus on standard Fourier transform and vector-valued spectral functions, they fall short in flexibility to describe specific signal distribution for each node, and expressivity of spectral function. In this paper, we present a novel wavelet-based graph convolution network, namely WaveGC, which integrates multi-resolution spectral bases and a matrix-valued filter kernel. Theoretically, we establish that WaveGC can effectively capture and decouple short-range and long-range information, providing superior filtering flexibility, surpassing existing graph convolutional networks and graph Transformers (GTs). To instantiate WaveGC, we introduce a novel technique for learning general graph wavelets by separately combining odd and even terms of Chebyshev polynomials. This approach strictly satisfies wavelet admissibility criteria. Our numerical experiments showcase the capabilities of the new network. By replacing the Transformer part in existing architectures with WaveGC, we consistently observe improvements in both short-range and long-range tasks. This underscores the effectiveness of the proposed model in handling different scenarios. Our code is available at https://github.com/liun-online/WaveGC.
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
Feb 12, 2024



Given a graph with textual attributes, we enable users to `chat with their graph': that is, to ask questions about the graph using a conversational interface. In response to a user's questions, our method provides textual replies and highlights the relevant parts of the graph. While existing works integrate large language models (LLMs) and graph neural networks (GNNs) in various ways, they mostly focus on either conventional graph tasks (such as node, edge, and graph classification), or on answering simple graph queries on small or synthetic graphs. In contrast, we develop a flexible question-answering framework targeting real-world textual graphs, applicable to multiple applications including scene graph understanding, common sense reasoning, and knowledge graph reasoning. Toward this goal, we first develop our Graph Question Answering (GraphQA) benchmark with data collected from different tasks. Then, we propose our G-Retriever approach, which integrates the strengths of GNNs, LLMs, and Retrieval-Augmented Generation (RAG), and can be fine-tuned to enhance graph understanding via soft prompting. To resist hallucination and to allow for textual graphs that greatly exceed the LLM's context window size, G-Retriever performs RAG over a graph by formulating this task as a Prize-Collecting Steiner Tree optimization problem. Empirical evaluations show that our method outperforms baselines on textual graph tasks from multiple domains, scales well with larger graph sizes, and resists hallucination. (Our codes and datasets are available at: https://github.com/XiaoxinHe/G-Retriever.)
Navigating Complexity: Toward Lossless Graph Condensation via Expanding Window Matching
Feb 07, 2024Graph condensation aims to reduce the size of a large-scale graph dataset by synthesizing a compact counterpart without sacrificing the performance of Graph Neural Networks (GNNs) trained on it, which has shed light on reducing the computational cost for training GNNs. Nevertheless, existing methods often fall short of accurately replicating the original graph for certain datasets, thereby failing to achieve the objective of lossless condensation. To understand this phenomenon, we investigate the potential reasons and reveal that the previous state-of-the-art trajectory matching method provides biased and restricted supervision signals from the original graph when optimizing the condensed one. This significantly limits both the scale and efficacy of the condensed graph. In this paper, we make the first attempt toward \textit{lossless graph condensation} by bridging the previously neglected supervision signals. Specifically, we employ a curriculum learning strategy to train expert trajectories with more diverse supervision signals from the original graph, and then effectively transfer the information into the condensed graph with expanding window matching. Moreover, we design a loss function to further extract knowledge from the expert trajectories. Theoretical analysis justifies the design of our method and extensive experiments verify its superiority across different datasets. Code is released at https://github.com/NUS-HPC-AI-Lab/GEOM.
Through the Dual-Prism: A Spectral Perspective on Graph Data Augmentation for Graph Classification
Jan 22, 2024

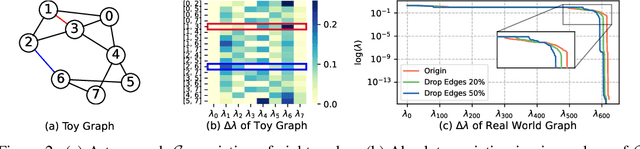

Graph Neural Networks (GNNs) have become the preferred tool to process graph data, with their efficacy being boosted through graph data augmentation techniques. Despite the evolution of augmentation methods, issues like graph property distortions and restricted structural changes persist. This leads to the question: Is it possible to develop more property-conserving and structure-sensitive augmentation methods? Through a spectral lens, we investigate the interplay between graph properties, their augmentation, and their spectral behavior, and found that keeping the low-frequency eigenvalues unchanged can preserve the critical properties at a large scale when generating augmented graphs. These observations inform our introduction of the Dual-Prism (DP) augmentation method, comprising DP-Noise and DP-Mask, which adeptly retains essential graph properties while diversifying augmented graphs. Extensive experiments validate the efficiency of our approach, providing a new and promising direction for graph data augmentation.
Graph Transformers for Large Graphs
Dec 18, 2023Transformers have recently emerged as powerful neural networks for graph learning, showcasing state-of-the-art performance on several graph property prediction tasks. However, these results have been limited to small-scale graphs, where the computational feasibility of the global attention mechanism is possible. The next goal is to scale up these architectures to handle very large graphs on the scale of millions or even billions of nodes. With large-scale graphs, global attention learning is proven impractical due to its quadratic complexity w.r.t. the number of nodes. On the other hand, neighborhood sampling techniques become essential to manage large graph sizes, yet finding the optimal trade-off between speed and accuracy with sampling techniques remains challenging. This work advances representation learning on single large-scale graphs with a focus on identifying model characteristics and critical design constraints for developing scalable graph transformer (GT) architectures. We argue such GT requires layers that can adeptly learn both local and global graph representations while swiftly sampling the graph topology. As such, a key innovation of this work lies in the creation of a fast neighborhood sampling technique coupled with a local attention mechanism that encompasses a 4-hop reception field, but achieved through just 2-hop operations. This local node embedding is then integrated with a global node embedding, acquired via another self-attention layer with an approximate global codebook, before finally sent through a downstream layer for node predictions. The proposed GT framework, named LargeGT, overcomes previous computational bottlenecks and is validated on three large-scale node classification benchmarks. We report a 3x speedup and 16.8% performance gain on ogbn-products and snap-patents, while we also scale LargeGT on ogbn-papers100M with a 5.9% performance improvement.
Explanations as Features: LLM-Based Features for Text-Attributed Graphs
May 31, 2023Representation learning on text-attributed graphs (TAGs) has become a critical research problem in recent years. A typical example of a TAG is a paper citation graph, where the text of each paper serves as node attributes. Most graph neural network (GNN) pipelines handle these text attributes by transforming them into shallow or hand-crafted features, such as skip-gram or bag-of-words features. Recent efforts have focused on enhancing these pipelines with language models. With the advent of powerful large language models (LLMs) such as GPT, which demonstrate an ability to reason and to utilize general knowledge, there is a growing need for techniques which combine the textual modelling abilities of LLMs with the structural learning capabilities of GNNs. Hence, in this work, we focus on leveraging LLMs to capture textual information as features, which can be used to boost GNN performance on downstream tasks. A key innovation is our use of \emph{explanations as features}: we prompt an LLM to perform zero-shot classification and to provide textual explanations for its decisions, and find that the resulting explanations can be transformed into useful and informative features to augment downstream GNNs. Through experiments we show that our enriched features improve the performance of a variety of GNN models across different datasets. Notably, we achieve top-1 performance on \texttt{ogbn-arxiv} by a significant margin over the closest baseline even with $2.88\times$ lower computation time, as well as top-1 performance on TAG versions of the widely used \texttt{PubMed} and \texttt{Cora} benchmarks~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/TAPE}}.
Feature Collapse
May 25, 2023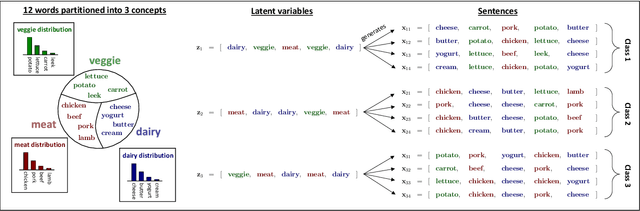
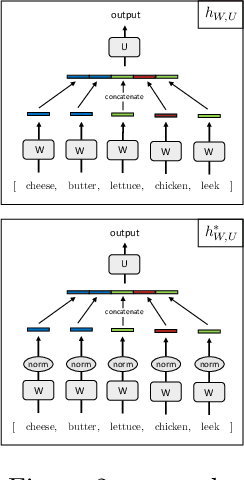
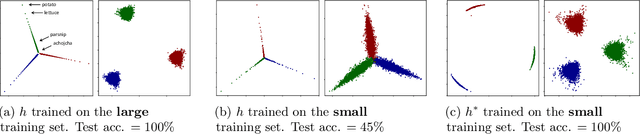
We formalize and study a phenomenon called feature collapse that makes precise the intuitive idea that entities playing a similar role in a learning task receive similar representations. As feature collapse requires a notion of task, we leverage a simple but prototypical NLP task to study it. We start by showing experimentally that feature collapse goes hand in hand with generalization. We then prove that, in the large sample limit, distinct words that play identical roles in this NLP task receive identical local feature representations in a neural network. This analysis reveals the crucial role that normalization mechanisms, such as LayerNorm, play in feature collapse and in generalization.
A Generalization of ViT/MLP-Mixer to Graphs
Dec 27, 2022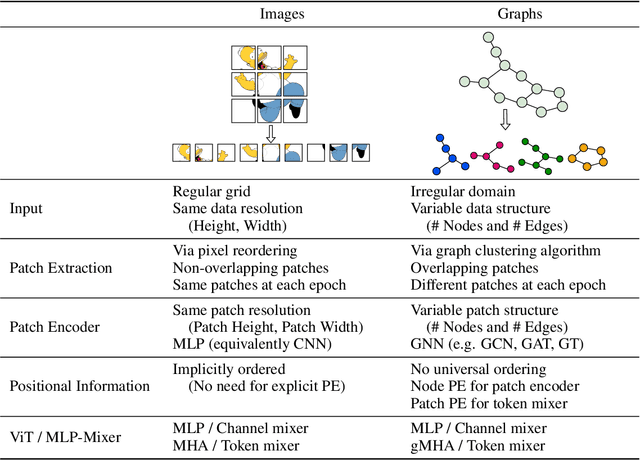
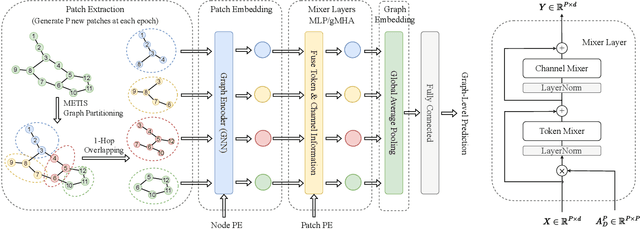
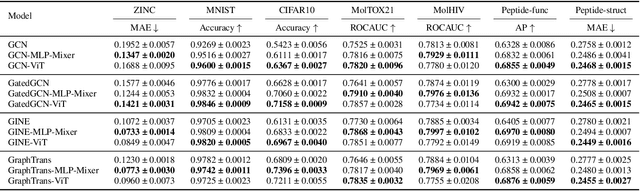
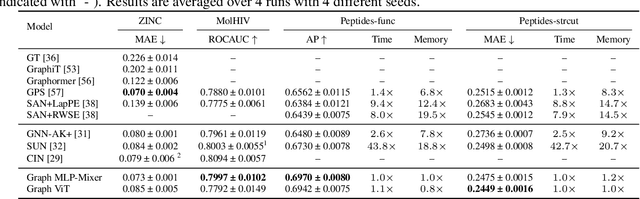
Graph Neural Networks (GNNs) have shown great potential in the field of graph representation learning. Standard GNNs define a local message-passing mechanism which propagates information over the whole graph domain by stacking multiple layers. This paradigm suffers from two major limitations, over-squashing and poor long-range dependencies, that can be solved using global attention but significantly increases the computational cost to quadratic complexity. In this work, we propose an alternative approach to overcome these structural limitations by leveraging the ViT/MLP-Mixer architectures introduced in computer vision. We introduce a new class of GNNs, called Graph MLP-Mixer, that holds three key properties. First, they capture long-range dependency and mitigate the issue of over-squashing as demonstrated on the Long Range Graph Benchmark (LRGB) and the TreeNeighbourMatch datasets. Second, they offer better speed and memory efficiency with a complexity linear to the number of nodes and edges, surpassing the related Graph Transformer and expressive GNN models. Third, they show high expressivity in terms of graph isomorphism as they can distinguish at least 3-WL non-isomorphic graphs. We test our architecture on 4 simulated datasets and 7 real-world benchmarks, and show highly competitive results on all of them.