 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Collapse
May 25, 2023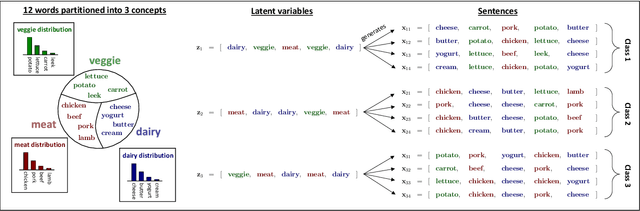
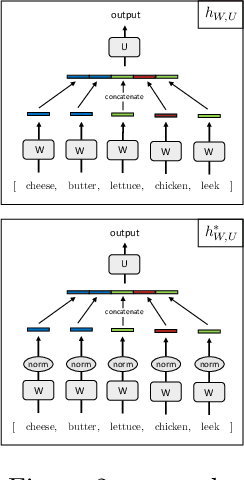
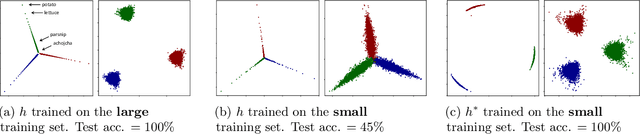
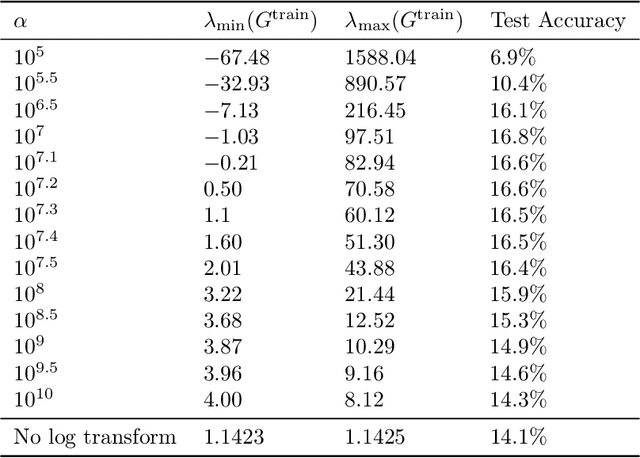
We formalize and study a phenomenon called feature collapse that makes precise the intuitive idea that entities playing a similar role in a learning task receive similar representations. As feature collapse requires a notion of task, we leverage a simple but prototypical NLP task to study it. We start by showing experimentally that feature collapse goes hand in hand with generalization. We then prove that, in the large sample limit, distinct words that play identical roles in this NLP task receive identical local feature representations in a neural network. This analysis reveals the crucial role that normalization mechanisms, such as LayerNorm, play in feature collapse and in generalization.
A Model of One-Shot Generalization
May 29, 2022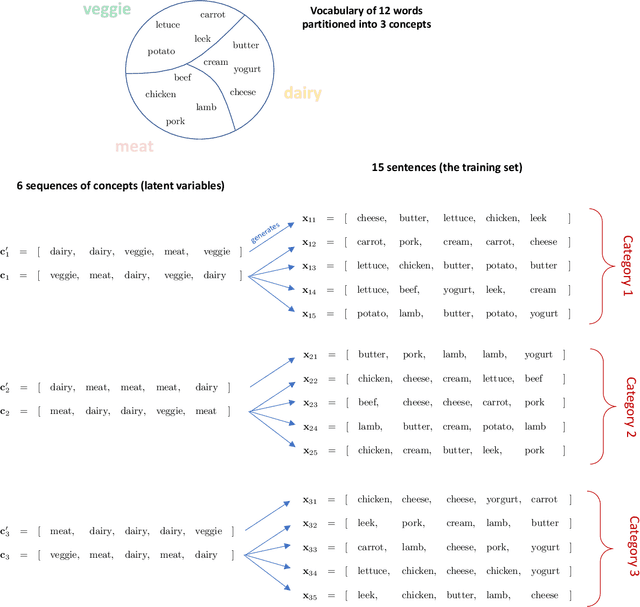

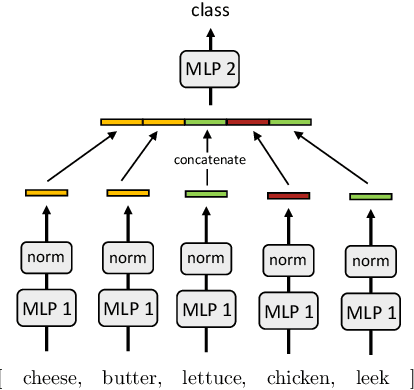
We provide a theoretical framework to study a phenomenon that we call one-shot generalization. This phenomenon refers to the ability of an algorithm to perform transfer learning within a single task, meaning that it correctly classifies a test point that has a single exemplar in the training set. We propose a simple data model and use it to study this phenomenon in two ways. First, we prove a non-asymptotic base-line -- kernel methods based on nearest-neighbor classification cannot perform one-shot generalization, independently of the choice of the kernel and the size of the training set. Second, we empirically show that the most direct neural network architecture for our data model performs one-shot generalization almost perfectly. This stark differential leads us to believe that the one-shot generalization mechanism is partially responsible for the empirical success of neural networks.
Multiclass Total Variation Clustering
Jun 05, 2013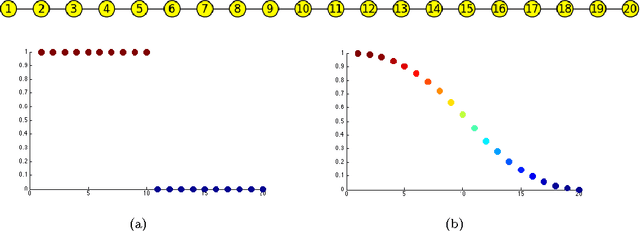
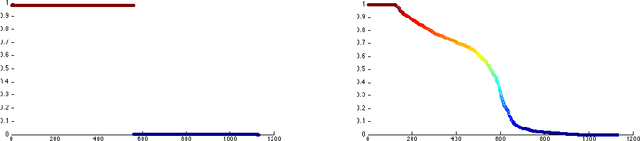
Ideas from the image processing literature have recently motivated a new set of clustering algorithms that rely on the concept of total variation. While these algorithms perform well for bi-partitioning tasks, their recursive extensions yield unimpressive results for multiclass clustering tasks. This paper presents a general framework for multiclass total variation clustering that does not rely on recursion. The results greatly outperform previous total variation algorithms and compare well with state-of-the-art NMF approaches.