 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model of One-Shot Generalization
Paper and Code
May 29, 2022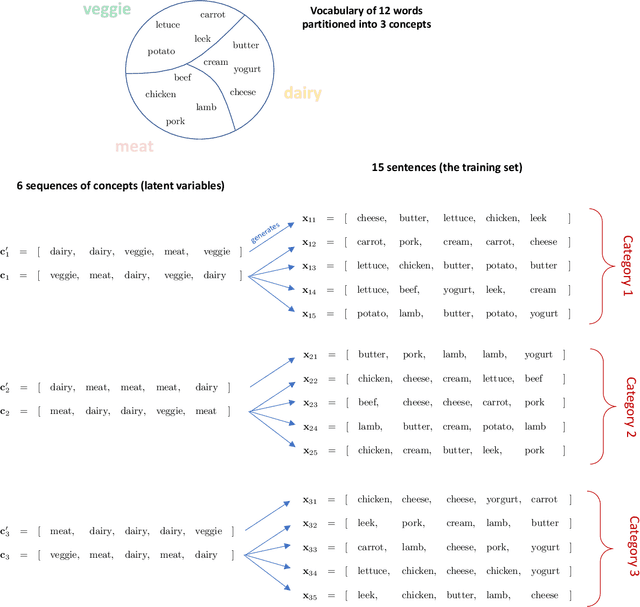

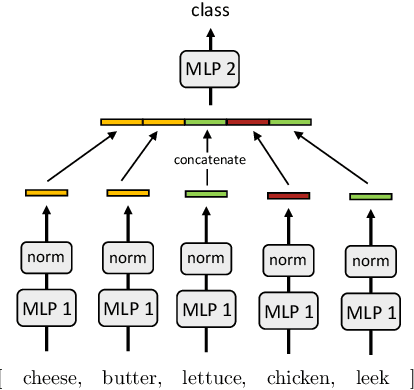
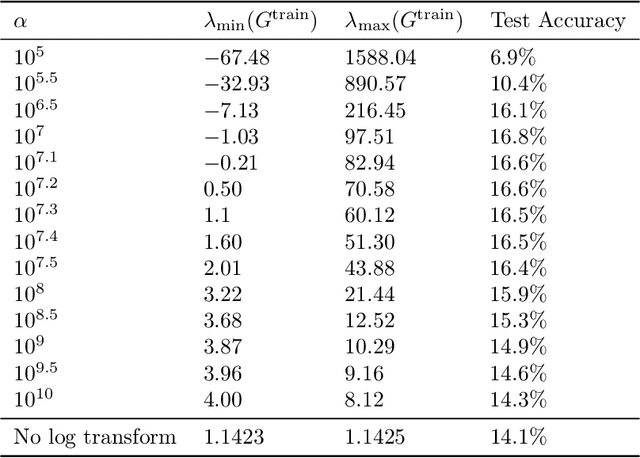
We provide a theoretical framework to study a phenomenon that we call one-shot generalization. This phenomenon refers to the ability of an algorithm to perform transfer learning within a single task, meaning that it correctly classifies a test point that has a single exemplar in the training set. We propose a simple data model and use it to study this phenomenon in two ways. First, we prove a non-asymptotic base-line -- kernel methods based on nearest-neighbor classification cannot perform one-shot generalization, independently of the choice of the kernel and the size of the training set. Second, we empirically show that the most direct neural network architecture for our data model performs one-shot generalization almost perfectly. This stark differential leads us to believe that the one-shot generalization mechanism is partially responsible for the empirical success of neural networks.