 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrys-JEPA: Accelerating Crystal Discovery via Embedding Screening and Generative Refinement
May 14, 2026De novo crystal generation seeks to discover materials that are not merely realistic, but also stable and novel. However, most existing generative models are trained to maximize the likelihood of observed crystals, which encourages samples to stay close to known materials yet not necessarily align with the criteria that matter in discovery. Through an empirical investigation, we show that current crystal generative models are caught in a pronounced stability--novelty trade-off: moving toward the observed distribution preserves stability but limits novelty, whereas moving away from it quickly destroys stability. This suggests that the useful region for discovering crystals that are both stable and novel is extremely narrow. To escape the trade-off, we introduce Crys-JEPA, a joint embedding predictive architecture for crystals that learns an energy-aware latent space preserving formation-energy differences. In this space, stability assessment can be reformulated as an embedding-based comparison against accessible training crystals, reducing the reliance on expensive energy evaluation and task-specific external references. Building on Crys-JEPA, we further develop a screening-and-refinement pipeline that identifies promising generated crystals and reintroduces them to refine the generative model. On MP-20 and Alex-MP-20 datasets, we achieve improvements over baselines up to 81.4% and 82.6% on V.S.U.N metric, respectively.
Composable Crystals: Controllable Materials Discovery via Concept Learning
May 14, 2026De novo crystal generation, a central task in materials discovery, aims to generate crystals that are simultaneously valid, stable, unique, and novel. Existing methods mainly rely on black-box stochastic sampling, providing limited control over how generated structures move beyond the observed distribution. In this paper, we introduce a concept-based compositional framework for crystal generation. We train a vector-quantized variational autoencoder to automatically discover a shared set of reusable crystal concepts, which serve as building blocks for guided generation. These learned concepts naturally exhibit interpretability from both local atomic environments and global symmetry patterns, and generalize to crystals from different distributions. By recombining such concepts, our framework enables controllable exploration of novel crystals beyond the training distribution, rather than relying solely on unconstrained random sampling. To further improve composition efficiency, we introduce a composition generator and iteratively refine it using high-quality samples generated by the model itself. The resulting concept compositions are then used to condition downstream crystal generation. Numerical experiments on MP-20 and Alex-MP-20 show that compositing concepts separately increase base model up to 53.2% and 51.7% on V.S.U.N metric, with particular gains in novelty.
Metamorphic Testing for Pose Estimation Systems
Feb 13, 2025Pose estimation systems are used in a variety of fields, from sports analytics to livestock care. Given their potential impact, it is paramount to systematically test their behaviour and potential for failure. This is a complex task due to the oracle problem and the high cost of manual labelling necessary to build ground truth keypoints. This problem is exacerbated by the fact that different applications require systems to focus on different subjects (e.g., human versus animal) or landmarks (e.g., only extremities versus whole body and face), which makes labelled test data rarely reusable. To combat these problems we propose MET-POSE, a metamorphic testing framework for pose estimation systems that bypasses the need for manual annotation while assessing the performance of these systems under different circumstances. MET-POSE thus allows users of pose estimation systems to assess the systems in conditions that more closely relate to their application without having to label an ad-hoc test dataset or rely only on available datasets, which may not be adapted to their application domain. While we define MET-POSE in general terms, we also present a non-exhaustive list of metamorphic rules that represent common challenges in computer vision applications, as well as a specific way to evaluate these rules. We then experimentally show the effectiveness of MET-POSE by applying it to Mediapipe Holistic, a state of the art human pose estimation system, with the FLIC and PHOENIX datasets. With these experiments, we outline numerous ways in which the outputs of MET-POSE can uncover faults in pose estimation systems at a similar or higher rate than classic testing using hand labelled data, and show that users can tailor the rule set they use to the faults and level of accuracy relevant to their application.
Generative diffusion models from a PDE perspective
Jan 28, 2025Diffusion models have become the de facto framework for generating new datasets. The core of these models lies in the ability to reverse a diffusion process in time. The goal of this manuscript is to explain, from a PDE perspective, how this method works and how to derive the PDE governing the reverse dynamics as well as to study its solution analytically. By linking forward and reverse dynamics, we show that the reverse process's distribution has its support contained within the original distribution. Consequently, diffusion methods, in their analytical formulation, do not inherently regularize the original distribution, and thus, there is no generalization principle. This raises a question: where does generalization arise, given that in practice it does occur? Moreover, we derive an explicit solution to the reverse process's SDE under the assumption that the starting point of the forward process is fixed. This provides a new derivation that links two popular approaches to generative diffusion models: stable diffusion (discrete dynamics) and the score-based approach (continuous dynamics). Finally, we explore the case where the original distribution consists of a finite set of data points. In this scenario, the reverse dynamics are explicit (i.e., the loss function has a clear minimizer), and solving the dynamics fails to generate new samples: the dynamics converge to the original samples. In a sense, solving the minimization problem exactly is "too good for its own good" (i.e., an overfitting regime).
Advancing Graph Convolutional Networks via General Spectral Wavelets
May 22, 2024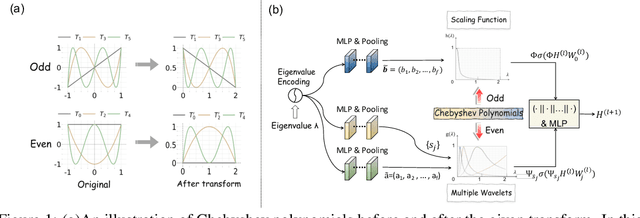

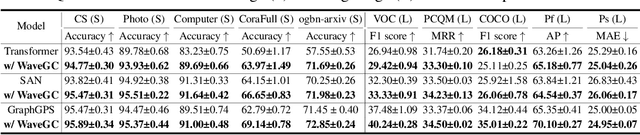
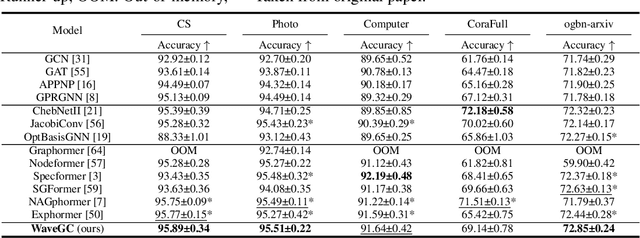
Spectral graph convolution, an important tool of data filtering on graphs, relies on two essential decisions; selecting spectral bases for signal transformation and parameterizing the kernel for frequency analysis. While recent techniques mainly focus on standard Fourier transform and vector-valued spectral functions, they fall short in flexibility to describe specific signal distribution for each node, and expressivity of spectral function. In this paper, we present a novel wavelet-based graph convolution network, namely WaveGC, which integrates multi-resolution spectral bases and a matrix-valued filter kernel. Theoretically, we establish that WaveGC can effectively capture and decouple short-range and long-range information, providing superior filtering flexibility, surpassing existing graph convolutional networks and graph Transformers (GTs). To instantiate WaveGC, we introduce a novel technique for learning general graph wavelets by separately combining odd and even terms of Chebyshev polynomials. This approach strictly satisfies wavelet admissibility criteria. Our numerical experiments showcase the capabilities of the new network. By replacing the Transformer part in existing architectures with WaveGC, we consistently observe improvements in both short-range and long-range tasks. This underscores the effectiveness of the proposed model in handling different scenarios. Our code is available at https://github.com/liun-online/WaveGC.
Train Ego-Path Detection on Railway Tracks Using End-to-End Deep Learning
Mar 19, 2024



This paper introduces the task of "train ego-path detection", a refined approach to railway track detection designed for intelligent onboard vision systems. Whereas existing research lacks precision and often considers all tracks within the visual field uniformly, our proposed task specifically aims to identify the train's immediate path, or "ego-path", within potentially complex and dynamic railway environments. Building on this, we extend the RailSem19 dataset with ego-path annotations, facilitating further research in this direction. At the heart of our study lies TEP-Net, an end-to-end deep learning framework tailored for ego-path detection, featuring a configurable model architecture, a dynamic data augmentation strategy, and a domain-specific loss function. Leveraging a regression-based approach, TEP-Net outperforms SOTA: while addressing the track detection problem in a more nuanced way than previously, our model achieves 97.5% IoU on the test set and is faster than all existing methods. Further comparative analysis highlights the relevance of the conceptual choices behind TEP-Net, demonstrating its inherent propensity for robustness across diverse environmental conditions and operational dynamics. This work opens promising avenues for the development of intelligent driver assistance systems and autonomous train operations, paving the way toward safer and more efficient railway transportation.
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
Feb 12, 2024



Given a graph with textual attributes, we enable users to `chat with their graph': that is, to ask questions about the graph using a conversational interface. In response to a user's questions, our method provides textual replies and highlights the relevant parts of the graph. While existing works integrate large language models (LLMs) and graph neural networks (GNNs) in various ways, they mostly focus on either conventional graph tasks (such as node, edge, and graph classification), or on answering simple graph queries on small or synthetic graphs. In contrast, we develop a flexible question-answering framework targeting real-world textual graphs, applicable to multiple applications including scene graph understanding, common sense reasoning, and knowledge graph reasoning. Toward this goal, we first develop our Graph Question Answering (GraphQA) benchmark with data collected from different tasks. Then, we propose our G-Retriever approach, which integrates the strengths of GNNs, LLMs, and Retrieval-Augmented Generation (RAG), and can be fine-tuned to enhance graph understanding via soft prompting. To resist hallucination and to allow for textual graphs that greatly exceed the LLM's context window size, G-Retriever performs RAG over a graph by formulating this task as a Prize-Collecting Steiner Tree optimization problem. Empirical evaluations show that our method outperforms baselines on textual graph tasks from multiple domains, scales well with larger graph sizes, and resists hallucination. (Our codes and datasets are available at: https://github.com/XiaoxinHe/G-Retriever.)
Explanations as Features: LLM-Based Features for Text-Attributed Graphs
May 31, 2023Representation learning on text-attributed graphs (TAGs) has become a critical research problem in recent years. A typical example of a TAG is a paper citation graph, where the text of each paper serves as node attributes. Most graph neural network (GNN) pipelines handle these text attributes by transforming them into shallow or hand-crafted features, such as skip-gram or bag-of-words features. Recent efforts have focused on enhancing these pipelines with language models. With the advent of powerful large language models (LLMs) such as GPT, which demonstrate an ability to reason and to utilize general knowledge, there is a growing need for techniques which combine the textual modelling abilities of LLMs with the structural learning capabilities of GNNs. Hence, in this work, we focus on leveraging LLMs to capture textual information as features, which can be used to boost GNN performance on downstream tasks. A key innovation is our use of \emph{explanations as features}: we prompt an LLM to perform zero-shot classification and to provide textual explanations for its decisions, and find that the resulting explanations can be transformed into useful and informative features to augment downstream GNNs. Through experiments we show that our enriched features improve the performance of a variety of GNN models across different datasets. Notably, we achieve top-1 performance on \texttt{ogbn-arxiv} by a significant margin over the closest baseline even with $2.88\times$ lower computation time, as well as top-1 performance on TAG versions of the widely used \texttt{PubMed} and \texttt{Cora} benchmarks~\footnote{Our codes and datasets are available at: \url{https://github.com/XiaoxinHe/TAPE}}.
Feature Collapse
May 25, 2023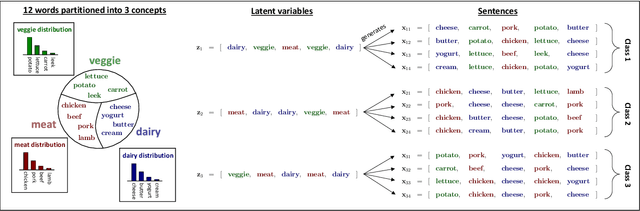
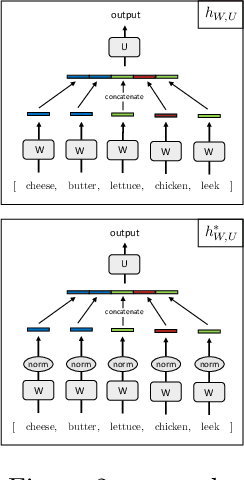
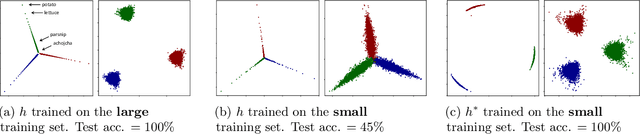
We formalize and study a phenomenon called feature collapse that makes precise the intuitive idea that entities playing a similar role in a learning task receive similar representations. As feature collapse requires a notion of task, we leverage a simple but prototypical NLP task to study it. We start by showing experimentally that feature collapse goes hand in hand with generalization. We then prove that, in the large sample limit, distinct words that play identical roles in this NLP task receive identical local feature representations in a neural network. This analysis reveals the crucial role that normalization mechanisms, such as LayerNorm, play in feature collapse and in generalization.
A Generalization of ViT/MLP-Mixer to Graphs
Dec 27, 2022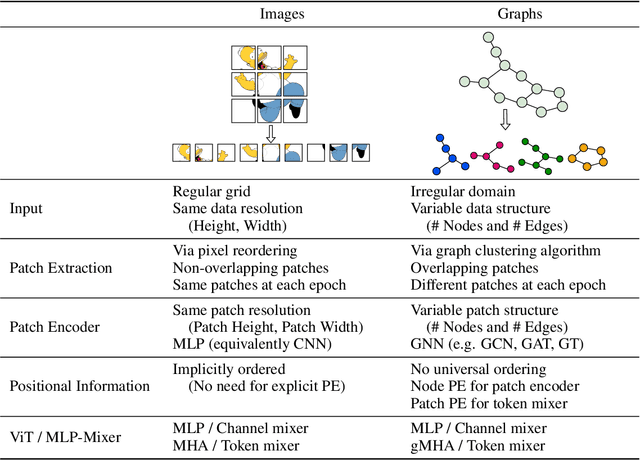
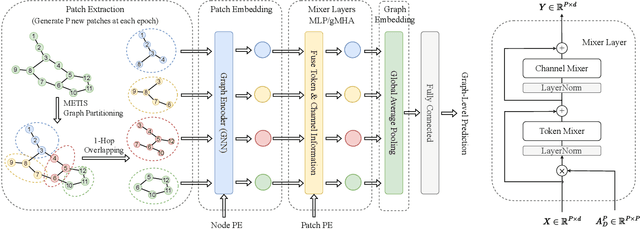
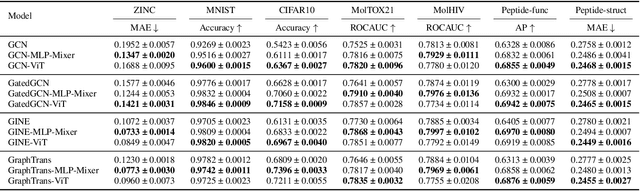
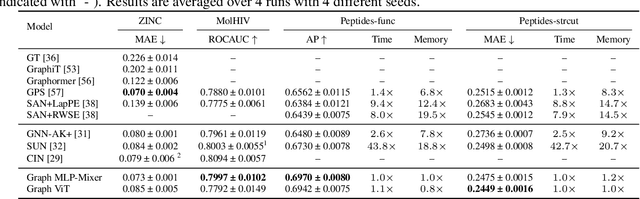
Graph Neural Networks (GNNs) have shown great potential in the field of graph representation learning. Standard GNNs define a local message-passing mechanism which propagates information over the whole graph domain by stacking multiple layers. This paradigm suffers from two major limitations, over-squashing and poor long-range dependencies, that can be solved using global attention but significantly increases the computational cost to quadratic complexity. In this work, we propose an alternative approach to overcome these structural limitations by leveraging the ViT/MLP-Mixer architectures introduced in computer vision. We introduce a new class of GNNs, called Graph MLP-Mixer, that holds three key properties. First, they capture long-range dependency and mitigate the issue of over-squashing as demonstrated on the Long Range Graph Benchmark (LRGB) and the TreeNeighbourMatch datasets. Second, they offer better speed and memory efficiency with a complexity linear to the number of nodes and edges, surpassing the related Graph Transformer and expressive GNN models. Third, they show high expressivity in terms of graph isomorphism as they can distinguish at least 3-WL non-isomorphic graphs. We test our architecture on 4 simulated datasets and 7 real-world benchmarks, and show highly competitive results on all of them.