 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetamorphic Testing for Pose Estimation Systems
Feb 13, 2025Pose estimation systems are used in a variety of fields, from sports analytics to livestock care. Given their potential impact, it is paramount to systematically test their behaviour and potential for failure. This is a complex task due to the oracle problem and the high cost of manual labelling necessary to build ground truth keypoints. This problem is exacerbated by the fact that different applications require systems to focus on different subjects (e.g., human versus animal) or landmarks (e.g., only extremities versus whole body and face), which makes labelled test data rarely reusable. To combat these problems we propose MET-POSE, a metamorphic testing framework for pose estimation systems that bypasses the need for manual annotation while assessing the performance of these systems under different circumstances. MET-POSE thus allows users of pose estimation systems to assess the systems in conditions that more closely relate to their application without having to label an ad-hoc test dataset or rely only on available datasets, which may not be adapted to their application domain. While we define MET-POSE in general terms, we also present a non-exhaustive list of metamorphic rules that represent common challenges in computer vision applications, as well as a specific way to evaluate these rules. We then experimentally show the effectiveness of MET-POSE by applying it to Mediapipe Holistic, a state of the art human pose estimation system, with the FLIC and PHOENIX datasets. With these experiments, we outline numerous ways in which the outputs of MET-POSE can uncover faults in pose estimation systems at a similar or higher rate than classic testing using hand labelled data, and show that users can tailor the rule set they use to the faults and level of accuracy relevant to their application.
What's left can't be right -- The remaining positional incompetence of contrastive vision-language models
Nov 20, 2023Contrastive vision-language models like CLIP have been found to lack spatial understanding capabilities. In this paper we discuss the possible causes of this phenomenon by analysing both datasets and embedding space. By focusing on simple left-right positional relations, we show that this behaviour is entirely predictable, even with large-scale datasets, demonstrate that these relations can be taught using synthetic data and show that this approach can generalise well to natural images - improving the performance on left-right relations on Visual Genome Relations.
Towards the extraction of robust sign embeddings for low resource sign language recognition
Jun 30, 2023Isolated Sign Language Recognition (SLR) has mostly been applied on relatively large datasets containing signs executed slowly and clearly by a limited group of signers. In real-world scenarios, however, we are met with challenging visual conditions, coarticulated signing, small datasets, and the need for signer independent models. To tackle this difficult problem, we require a robust feature extractor to process the sign language videos. One could expect human pose estimators to be ideal candidates. However, due to a domain mismatch with their training sets and challenging poses in sign language, they lack robustness on sign language data and image based models often still outperform keypoint based models. Furthermore, whereas the common practice of transfer learning with image based models yields even higher accuracy, keypoint based models are typically trained from scratch on every SLR dataset. These factors limit their usefulness for SLR. From the existing literature, it is also not clear which, if any, pose estimator performs best for SLR. We compare the three most popular pose estimators for SLR: OpenPose, MMPose and MediaPipe. We show that through keypoint normalization, missing keypoint imputation, and learning a pose embedding, we can obtain significantly better results and enable transfer learning. We show that keypoint-based embeddings contain cross-lingual features: they can transfer between sign languages and achieve competitive performance even when fine-tuning only the classifier layer of an SLR model on a target sign language. We furthermore achieve better performance using fine-tuned transferred embeddings than models trained only on the target sign language. The application of these embeddings could prove particularly useful for low resource sign languages in the future.
MILP for the Multi-objective VM Reassignment Problem
Mar 18, 2021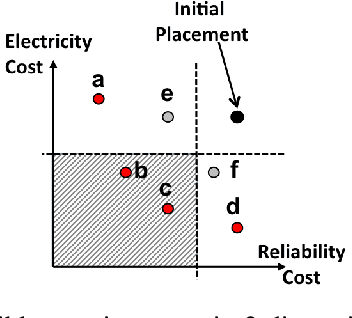
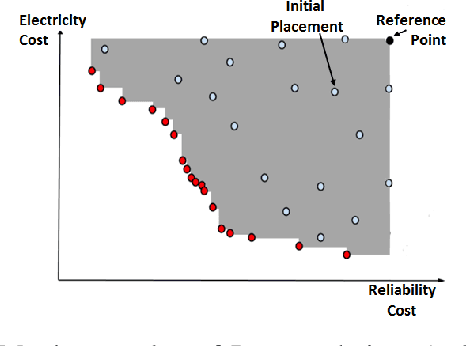
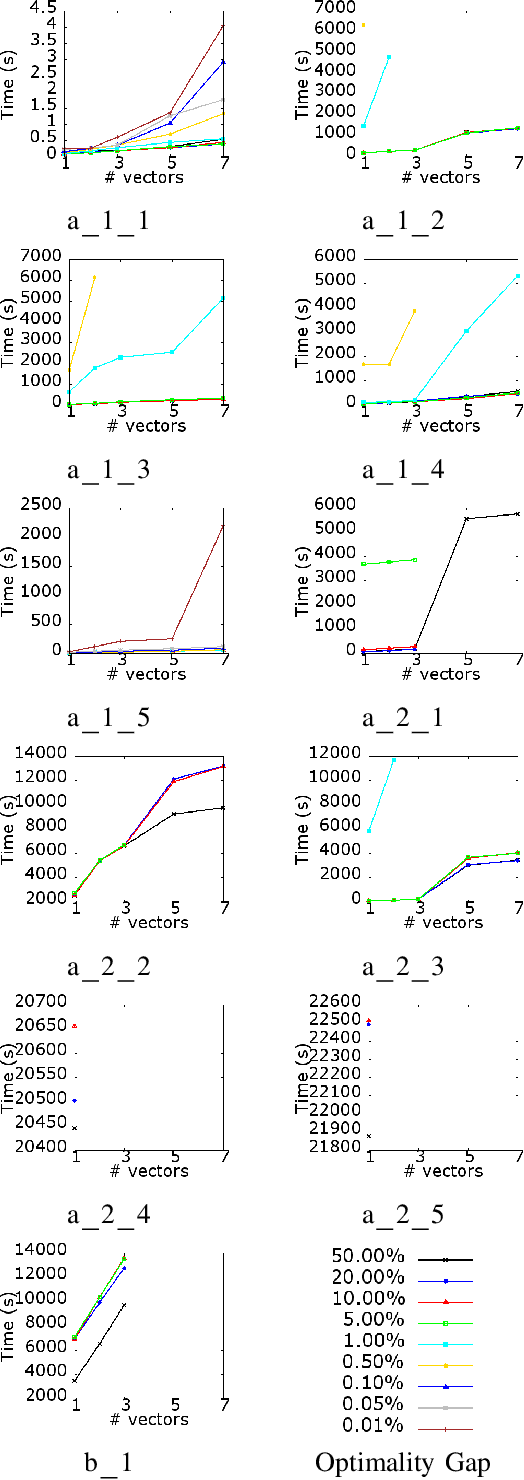

Machine Reassignment is a challenging problem for constraint programming (CP) and mixed-integer linear programming (MILP) approaches, especially given the size of data centres. The multi-objective version of the Machine Reassignment Problem is even more challenging and it seems unlikely for CP or MILP to obtain good results in this context. As a result, the first approaches to address this problem have been based on other optimisation methods, including metaheuristics. In this paper we study under which conditions a mixed-integer optimisation solver, such as IBM ILOG CPLEX, can be used for the Multi-objective Machine Reassignment Problem. We show that it is useful only for small or medium-scale data centres and with some relaxations, such as an optimality tolerance gap and a limited number of directions explored in the search space. Building on this study, we also investigate a hybrid approach, feeding a metaheuristic with the results of CPLEX, and we show that the gains are important in terms of quality of the set of Pareto solutions (+126.9% against the metaheuristic alone and +17.8% against CPLEX alone) and number of solutions (8.9 times more than CPLEX), while the processing time increases only by 6% in comparison to CPLEX for execution times larger than 100 seconds.
Learning Software Configuration Spaces: A Systematic Literature Review
Jun 07, 2019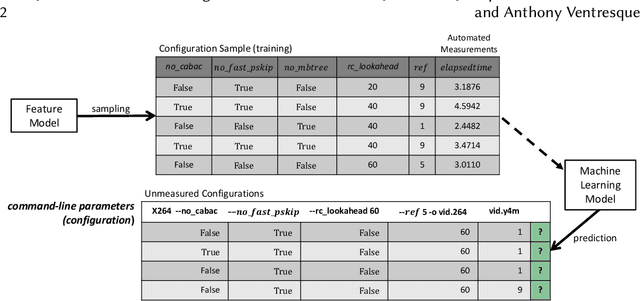

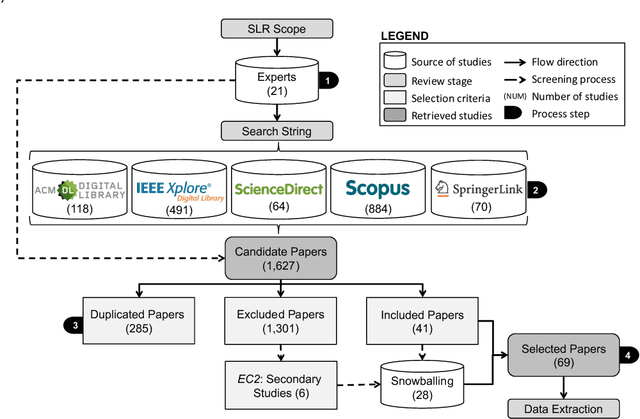
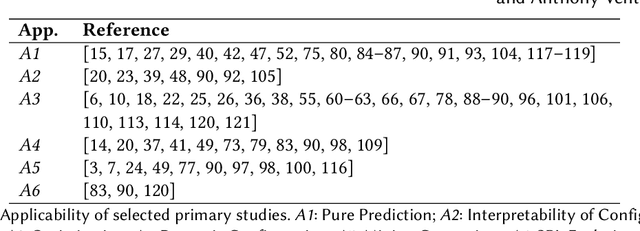
Most modern software systems (operating systems like Linux or Android, Web browsers like Firefox or Chrome, video encoders like ffmpeg, x264 or VLC, mobile and cloud applications, etc.) are highly-configurable. Hundreds of configuration options, features, or plugins can be combined, each potentially with distinct functionality and effects on execution time, security, energy consumption, etc. Due to the combinatorial explosion and the cost of executing software, it is quickly impossible to exhaustively explore the whole configuration space. Hence, numerous works have investigated the idea of learning it from a small sample of configurations' measurements. The pattern "sampling, measuring, learning" has emerged in the literature, with several practical interests for both software developers and end-users of configurable systems. In this survey, we report on the different application objectives (e.g., performance prediction, configuration optimization, constraint mining), use-cases, targeted software systems and application domains. We review the various strategies employed to gather a representative and cost-effective sample. We describe automated software techniques used to measure functional and non-functional properties of configurations. We classify machine learning algorithms and how they relate to the pursued application. Finally, we also describe how researchers evaluate the quality of the learning process. The findings from this systematic review show that the potential application objective is important; there are a vast number of case studies reported in the literature from the basis of several domains and software systems. Yet, the huge variant space of configurable systems is still challenging and calls to further investigate the synergies between artificial intelligence and software engineering.