 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAST-Enhanced or AST-Overloaded? The Surprising Impact of Hybrid Graph Representations on Code Clone Detection
Jun 17, 2025As one of the most detrimental code smells, code clones significantly increase software maintenance costs and heighten vulnerability risks, making their detection a critical challenge in software engineering. Abstract Syntax Trees (ASTs) dominate deep learning-based code clone detection due to their precise syntactic structure representation, but they inherently lack semantic depth. Recent studies address this by enriching AST-based representations with semantic graphs, such as Control Flow Graphs (CFGs) and Data Flow Graphs (DFGs). However, the effectiveness of various enriched AST-based representations and their compatibility with different graph-based machine learning techniques remains an open question, warranting further investigation to unlock their full potential in addressing the complexities of code clone detection. In this paper, we present a comprehensive empirical study to rigorously evaluate the effectiveness of AST-based hybrid graph representations in Graph Neural Network (GNN)-based code clone detection. We systematically compare various hybrid representations ((CFG, DFG, Flow-Augmented ASTs (FA-AST)) across multiple GNN architectures. Our experiments reveal that hybrid representations impact GNNs differently: while AST+CFG+DFG consistently enhances accuracy for convolution- and attention-based models (Graph Convolutional Networks (GCN), Graph Attention Networks (GAT)), FA-AST frequently introduces structural complexity that harms performance. Notably, GMN outperforms others even with standard AST representations, highlighting its superior cross-code similarity detection and reducing the need for enriched structures.
Assessing the Code Clone Detection Capability of Large Language Models
Jul 02, 2024This study aims to assess the performance of two advanced Large Language Models (LLMs), GPT-3.5 and GPT-4, in the task of code clone detection. The evaluation involves testing the models on a variety of code pairs of different clone types and levels of similarity, sourced from two datasets: BigCloneBench (human-made) and GPTCloneBench (LLM-generated). Findings from the study indicate that GPT-4 consistently surpasses GPT-3.5 across all clone types. A correlation was observed between the GPTs' accuracy at identifying code clones and code similarity, with both GPT models exhibiting low effectiveness in detecting the most complex Type-4 code clones. Additionally, GPT models demonstrate a higher performance identifying code clones in LLM-generated code compared to humans-generated code. However, they do not reach impressive accuracy. These results emphasize the imperative for ongoing enhancements in LLM capabilities, particularly in the recognition of code clones and in mitigating their predisposition towards self-generated code clones--which is likely to become an issue as software engineers are more numerous to leverage LLM-enabled code generation and code refactoring tools.
AudRandAug: Random Image Augmentations for Audio Classification
Sep 09, 2023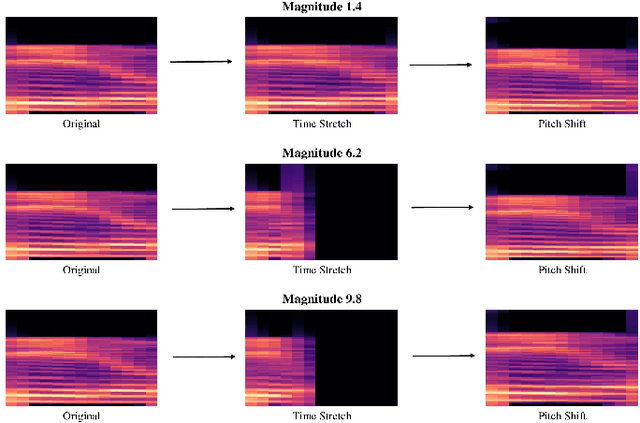

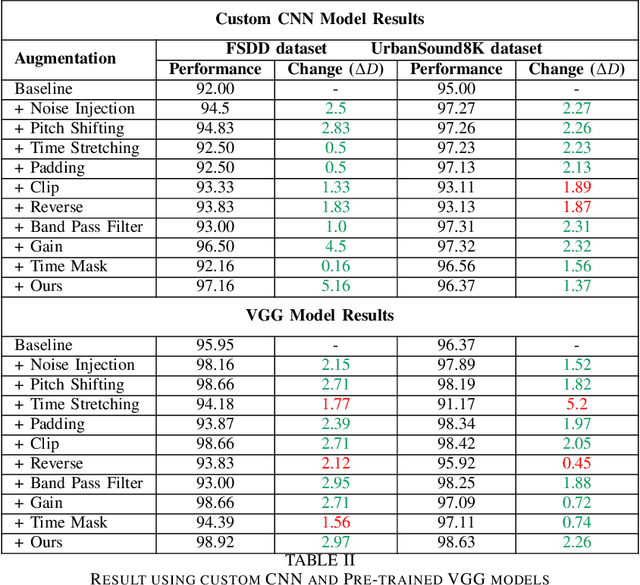
Data augmentation has proven to be effective in training neural networks. Recently, a method called RandAug was proposed, randomly selecting data augmentation techniques from a predefined search space. RandAug has demonstrated significant performance improvements for image-related tasks while imposing minimal computational overhead. However, no prior research has explored the application of RandAug specifically for audio data augmentation, which converts audio into an image-like pattern. To address this gap, we introduce AudRandAug, an adaptation of RandAug for audio data. AudRandAug selects data augmentation policies from a dedicated audio search space. To evaluate the effectiveness of AudRandAug, we conducted experiments using various models and datasets. Our findings indicate that AudRandAug outperforms other existing data augmentation methods regarding accuracy performance.
Investigating Multi-Feature Selection and Ensembling for Audio Classification
Jun 15, 2022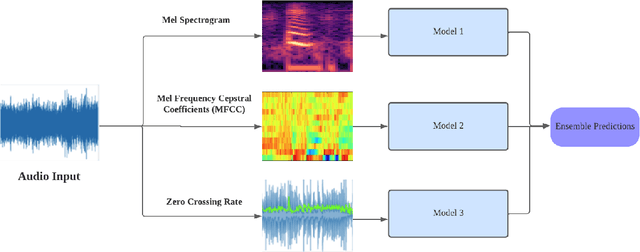
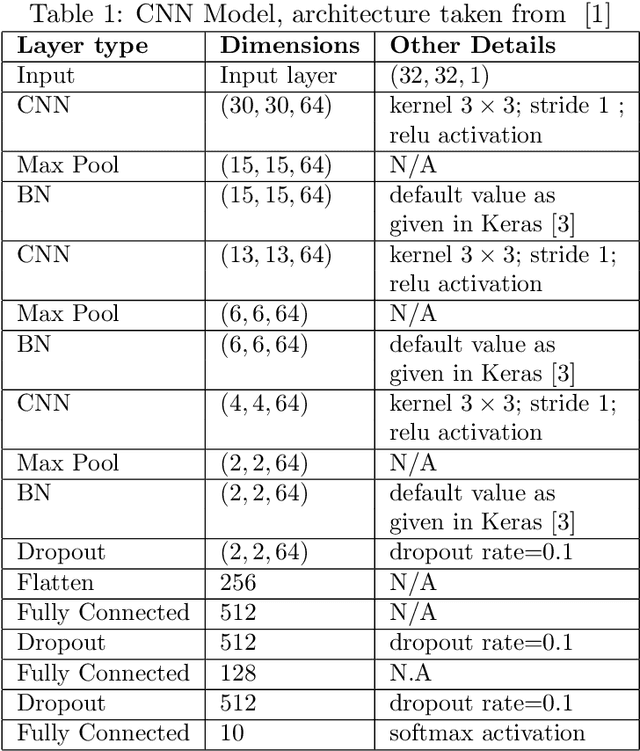
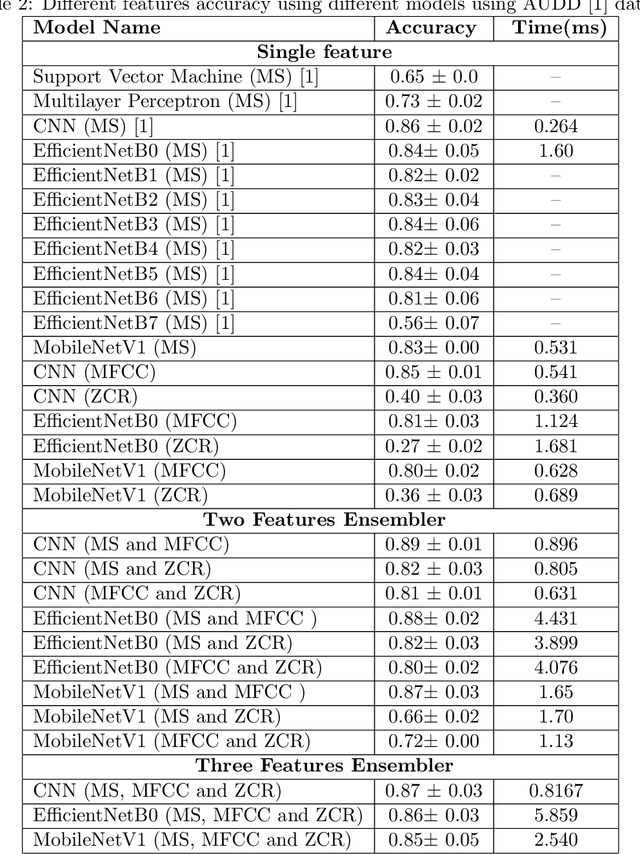
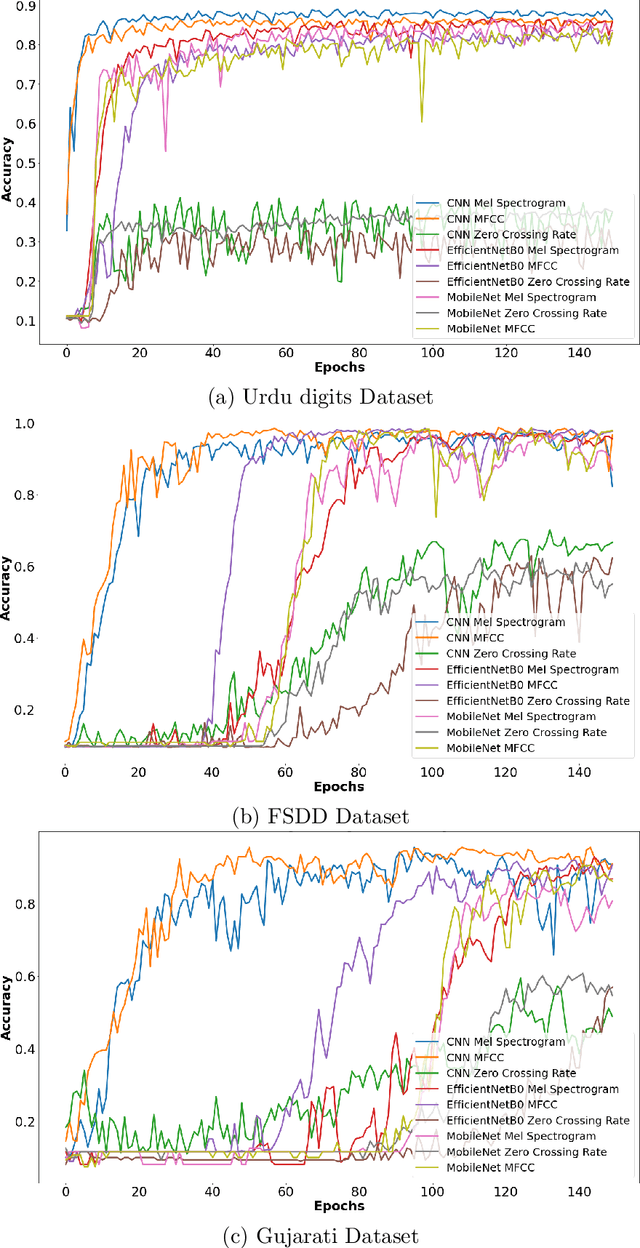
Deep Learning (DL) algorithms have shown impressive performance in diverse domains. Among them, audio has attracted many researchers over the last couple of decades due to some interesting patterns--particularly in classification of audio data. For better performance of audio classification, feature selection and combination play a key role as they have the potential to make or break the performance of any DL model. To investigate this role, we conduct an extensive evaluation of the performance of several cutting-edge DL models (i.e., Convolutional Neural Network, EfficientNet, MobileNet, Supper Vector Machine and Multi-Perceptron) with various state-of-the-art audio features (i.e., Mel Spectrogram, Mel Frequency Cepstral Coefficients, and Zero Crossing Rate) either independently or as a combination (i.e., through ensembling) on three different datasets (i.e., Free Spoken Digits Dataset, Audio Urdu Digits Dataset, and Audio Gujarati Digits Dataset). Overall, results suggest feature selection depends on both the dataset and the model. However, feature combinations should be restricted to the only features that already achieve good performances when used individually (i.e., mostly Mel Spectrogram, Mel Frequency Cepstral Coefficients). Such feature combination/ensembling enabled us to outperform the previous state-of-the-art results irrespective of our choice of DL model.
MILP for the Multi-objective VM Reassignment Problem
Mar 18, 2021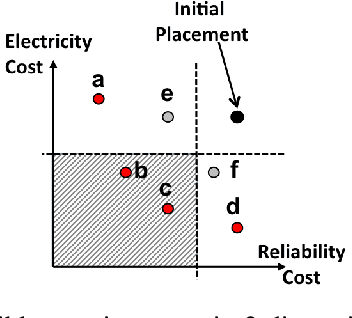
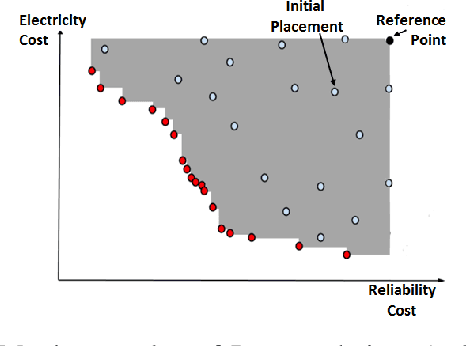
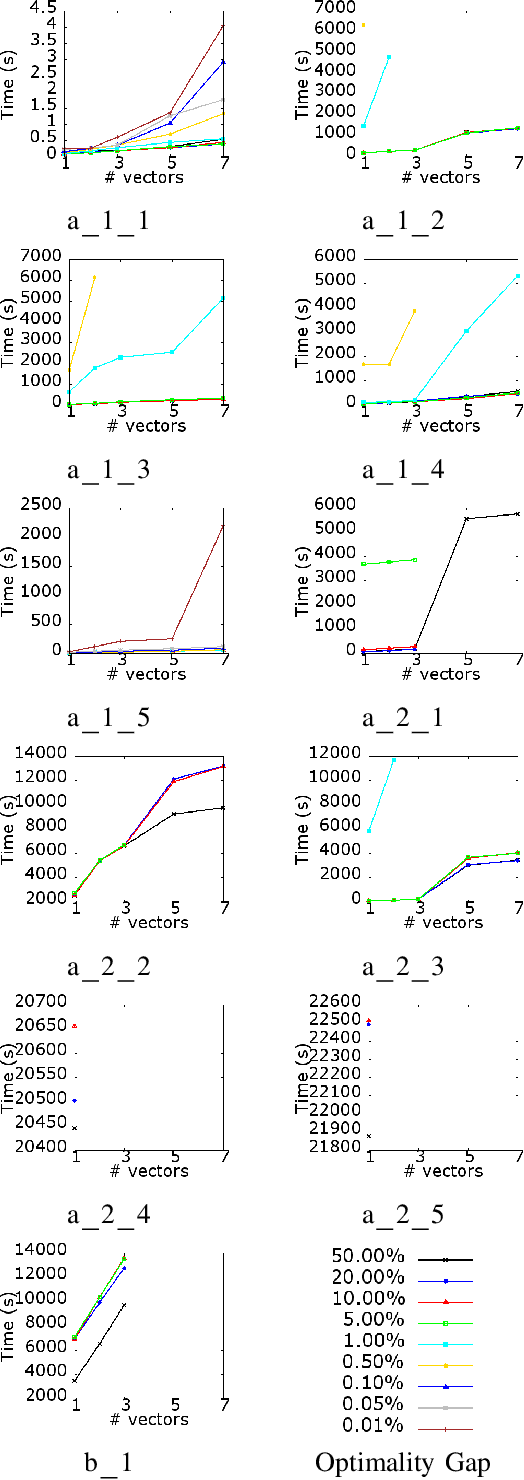

Machine Reassignment is a challenging problem for constraint programming (CP) and mixed-integer linear programming (MILP) approaches, especially given the size of data centres. The multi-objective version of the Machine Reassignment Problem is even more challenging and it seems unlikely for CP or MILP to obtain good results in this context. As a result, the first approaches to address this problem have been based on other optimisation methods, including metaheuristics. In this paper we study under which conditions a mixed-integer optimisation solver, such as IBM ILOG CPLEX, can be used for the Multi-objective Machine Reassignment Problem. We show that it is useful only for small or medium-scale data centres and with some relaxations, such as an optimality tolerance gap and a limited number of directions explored in the search space. Building on this study, we also investigate a hybrid approach, feeding a metaheuristic with the results of CPLEX, and we show that the gains are important in terms of quality of the set of Pareto solutions (+126.9% against the metaheuristic alone and +17.8% against CPLEX alone) and number of solutions (8.9 times more than CPLEX), while the processing time increases only by 6% in comparison to CPLEX for execution times larger than 100 seconds.