 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition in Contemporary Dance Performances Using Laban Movement Analysis
Apr 29, 2025



This paper presents a novel framework for emotion recognition in contemporary dance by improving existing Laban Movement Analysis (LMA) feature descriptors and introducing robust, novel descriptors that capture both quantitative and qualitative aspects of the movement. Our approach extracts expressive characteristics from 3D keypoints data of professional dancers performing contemporary dance under various emotional states, and trains multiple classifiers, including Random Forests and Support Vector Machines. Additionally, we provide in-depth explanation of features and their impact on model predictions using explainable machine learning methods. Overall, our study improves emotion recognition in contemporary dance and offers promising applications in performance analysis, dance training, and human--computer interaction, with a highest accuracy of 96.85\%.
Dance Style Recognition Using Laban Movement Analysis
Apr 29, 2025



The growing interest in automated movement analysis has presented new challenges in recognition of complex human activities including dance. This study focuses on dance style recognition using features extracted using Laban Movement Analysis. Previous studies for dance style recognition often focus on cross-frame movement analysis, which limits the ability to capture temporal context and dynamic transitions between movements. This gap highlights the need for a method that can add temporal context to LMA features. For this, we introduce a novel pipeline which combines 3D pose estimation, 3D human mesh reconstruction, and floor aware body modeling to effectively extract LMA features. To address the temporal limitation, we propose a sliding window approach that captures movement evolution across time in features. These features are then used to train various machine learning methods for classification, and their explainability explainable AI methods to evaluate the contribution of each feature to classification performance. Our proposed method achieves a highest classification accuracy of 99.18\% which shows that the addition of temporal context significantly improves dance style recognition performance.
A Comprehensive Survey on Image Signal Processing Approaches for Low-Illumination Image Enhancement
Feb 09, 2025The usage of digital content (photos and videos) in a variety of applications has increased due to the popularity of multimedia devices. These uses include advertising campaigns, educational resources, and social networking platforms. There is an increasing need for high-quality graphic information as people become more visually focused. However, captured images frequently have poor visibility and a high amount of noise due to the limitations of image-capturing devices and lighting conditions. Improving the visual quality of images taken in low illumination is the aim of low-illumination image enhancement. This problem is addressed by traditional image enhancement techniques, which alter noise, brightness, and contrast. Deep learning-based methods, however, have dominated recently made advances in this area. These methods have effectively reduced noise while preserving important information, showing promising results in the improvement of low-illumination images. An extensive summary of image signal processing methods for enhancing low-illumination images is provided in this paper. Three categories are classified in the review for approaches: hybrid techniques, deep learning-based methods, and traditional approaches. Conventional techniques include denoising, automated white balancing, and noise reduction. Convolutional neural networks (CNNs) are used in deep learningbased techniques to recognize and extract characteristics from low-light images. To get better results, hybrid approaches combine deep learning-based methodologies with more conventional methods. The review also discusses the advantages and limitations of each approach and provides insights into future research directions in this field.
AudRandAug: Random Image Augmentations for Audio Classification
Sep 09, 2023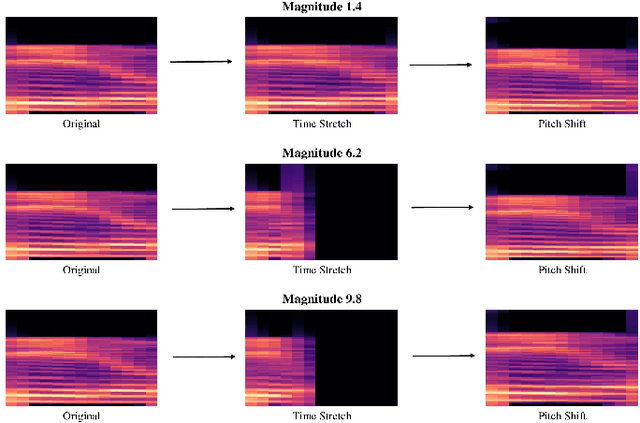

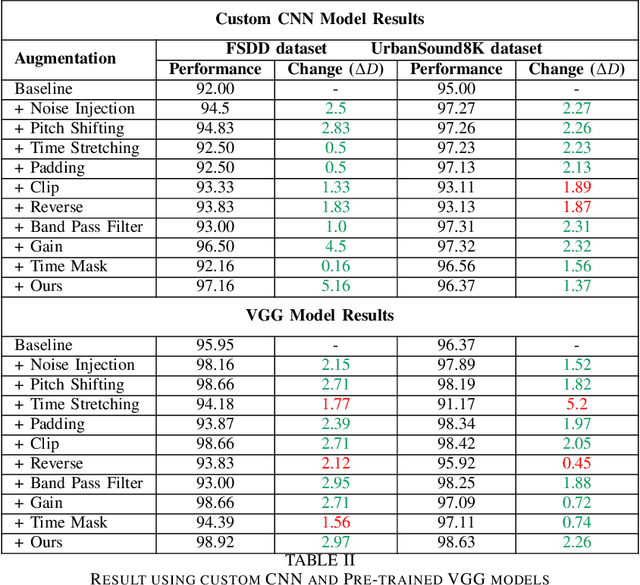
Data augmentation has proven to be effective in training neural networks. Recently, a method called RandAug was proposed, randomly selecting data augmentation techniques from a predefined search space. RandAug has demonstrated significant performance improvements for image-related tasks while imposing minimal computational overhead. However, no prior research has explored the application of RandAug specifically for audio data augmentation, which converts audio into an image-like pattern. To address this gap, we introduce AudRandAug, an adaptation of RandAug for audio data. AudRandAug selects data augmentation policies from a dedicated audio search space. To evaluate the effectiveness of AudRandAug, we conducted experiments using various models and datasets. Our findings indicate that AudRandAug outperforms other existing data augmentation methods regarding accuracy performance.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 14, 2023



Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Data Dimension Reduction makes ML Algorithms efficient
Nov 17, 2022



Data dimension reduction (DDR) is all about mapping data from high dimensions to low dimensions, various techniques of DDR are being used for image dimension reduction like Random Projections, Principal Component Analysis (PCA), the Variance approach, LSA-Transform, the Combined and Direct approaches, and the New Random Approach. Auto-encoders (AE) are used to learn end-to-end mapping. In this paper, we demonstrate that pre-processing not only speeds up the algorithms but also improves accuracy in both supervised and unsupervised learning. In pre-processing of DDR, first PCA based DDR is used for supervised learning, then we explore AE based DDR for unsupervised learning. In PCA based DDR, we first compare supervised learning algorithms accuracy and time before and after applying PCA. Similarly, in AE based DDR, we compare unsupervised learning algorithm accuracy and time before and after AE representation learning. Supervised learning algorithms including support-vector machines (SVM), Decision Tree with GINI index, Decision Tree with entropy and Stochastic Gradient Descent classifier (SGDC) and unsupervised learning algorithm including K-means clustering, are used for classification purpose. We used two datasets MNIST and FashionMNIST Our experiment shows that there is massive improvement in accuracy and time reduction after pre-processing in both supervised and unsupervised learning.
Advanced Audio Aid for Blind People
Nov 17, 2022



One of the most important senses in human life is vision, without it life is totally filled with darkness. According to WHO globally millions of people are visually impaired estimated there are 285 million, of whom some millions are blind. Unfortunately, there are around 2.4 million people are blind in our beloved country Pakistan. Human are a crucial part of society and the blind community is a main part of society. The technologies are grown so far to make the life of humans easier more comfortable and more reliable for. However, this disability of the blind community would reduce their chance of using such innovative products. Therefore, the visually impaired community believe that they are burden to other societies and they do not capture in normal activities separates the blind people from society and because of this believe did not participate in the normally tasks of society . The visual impair people mainly face most of the problems in this real-time The aim of this work is to turn the real time world into an audio world by telling blind person about the objects in their way and can read printed text. This will enable blind persons to identify the things and read the text without any external help just by using the object detection and reading system in real time. Objective of this work: i) Object detection ii) Read printed text, using state-of-the-art (SOTA) technology.
Investigating Multi-Feature Selection and Ensembling for Audio Classification
Jun 15, 2022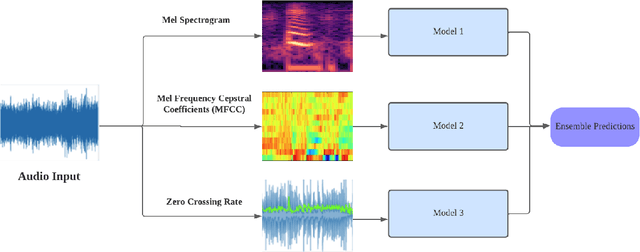
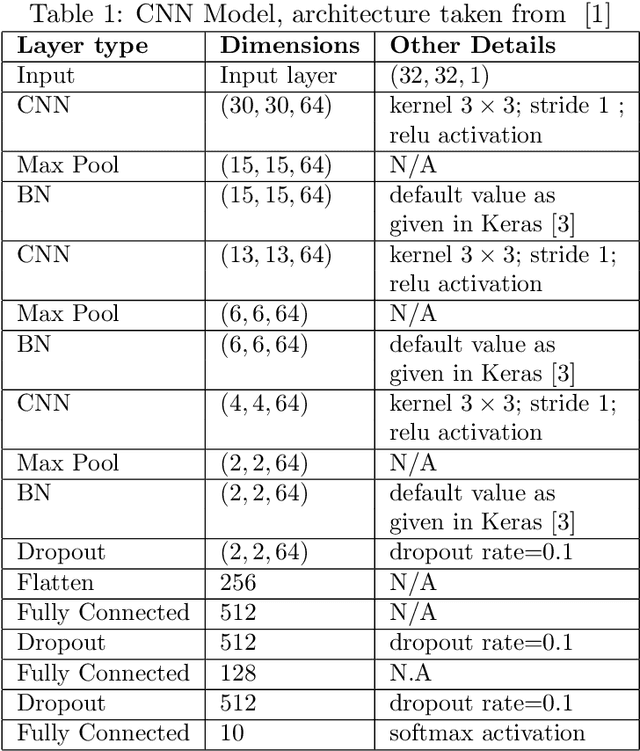
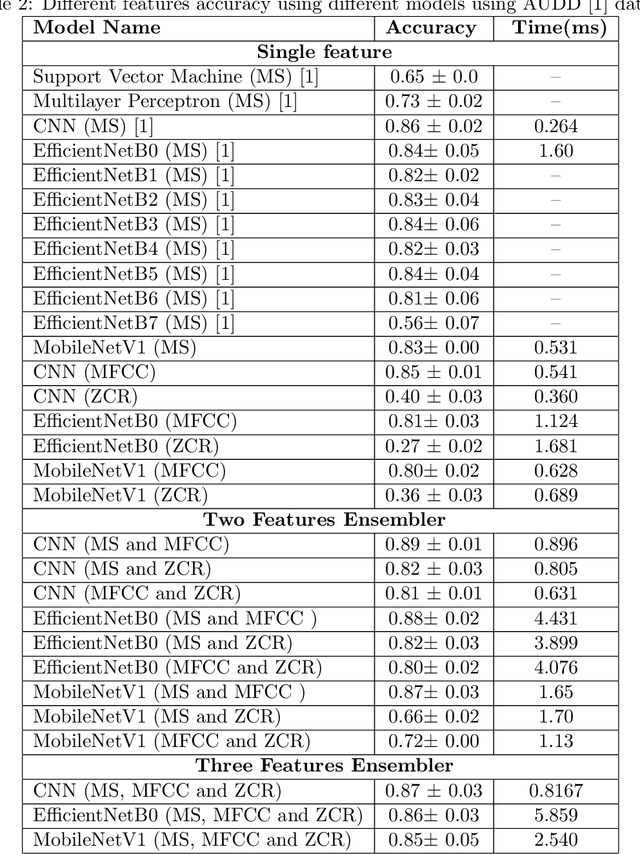
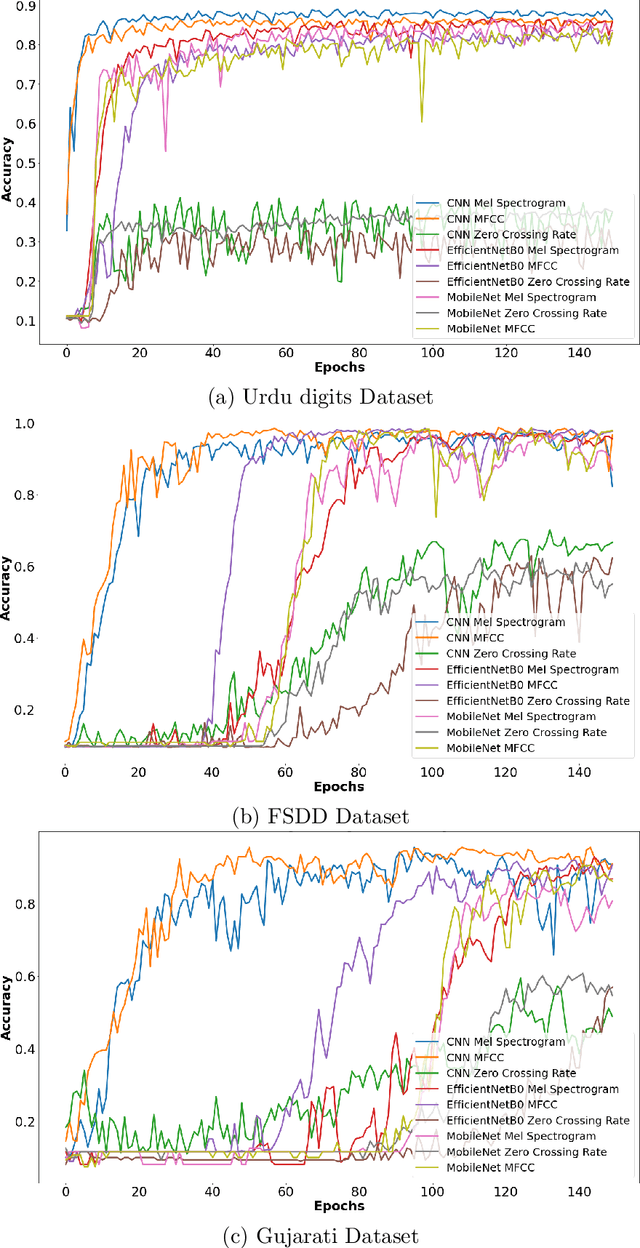
Deep Learning (DL) algorithms have shown impressive performance in diverse domains. Among them, audio has attracted many researchers over the last couple of decades due to some interesting patterns--particularly in classification of audio data. For better performance of audio classification, feature selection and combination play a key role as they have the potential to make or break the performance of any DL model. To investigate this role, we conduct an extensive evaluation of the performance of several cutting-edge DL models (i.e., Convolutional Neural Network, EfficientNet, MobileNet, Supper Vector Machine and Multi-Perceptron) with various state-of-the-art audio features (i.e., Mel Spectrogram, Mel Frequency Cepstral Coefficients, and Zero Crossing Rate) either independently or as a combination (i.e., through ensembling) on three different datasets (i.e., Free Spoken Digits Dataset, Audio Urdu Digits Dataset, and Audio Gujarati Digits Dataset). Overall, results suggest feature selection depends on both the dataset and the model. However, feature combinations should be restricted to the only features that already achieve good performances when used individually (i.e., mostly Mel Spectrogram, Mel Frequency Cepstral Coefficients). Such feature combination/ensembling enabled us to outperform the previous state-of-the-art results irrespective of our choice of DL model.