 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 14, 2023



Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
Understanding EEG signals for subject-wise Definition of Armoni Activities
Jan 03, 2023In a growing world of technology, psychological disorders became a challenge to be solved. The methods used for cognitive stimulation are very conventional and based on one-way communication, which only relies on the material or method used for training of an individual. It doesn't use any kind of feedback from the individual to analyze the progress of the training process. We have proposed a closed-loop methodology to improve the cognitive state of a person with ID (Intellectual disability). We have used a platform named 'Armoni', for providing training to the intellectually disabled individuals. The learning is performed in a closed-loop by using feedback in the form of change in affective state. For feedback to the Armoni, an EEG (Electroencephalograph) headband is used. All the changes in EEG are observed and classified against the change in the mean and standard deviation value of all frequency bands of signal. This comparison is being helpful in defining every activity with respect to change in brain signals. In this paper, we have discussed the process of treatment of EEG signal and its definition against the different activities of Armoni. We have tested it on 6 different systems with different age groups and cognitive levels.
SQL and NoSQL Databases Software architectures performance analysis and assessments -- A Systematic Literature review
Sep 14, 2022
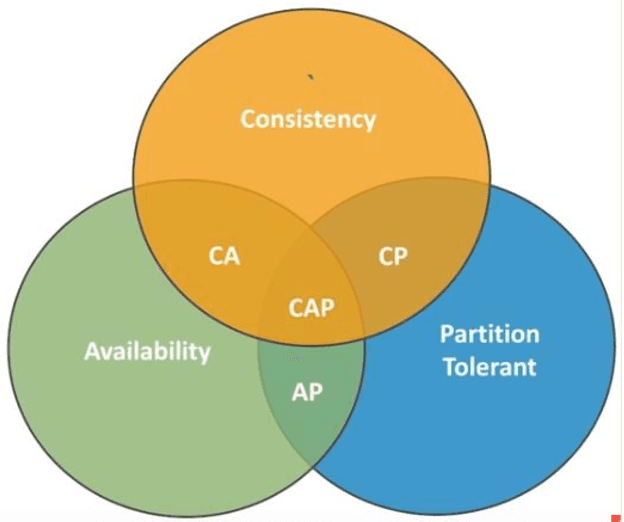
Context: The efficient processing of Big Data is a challenging task for SQL and NoSQL Databases, where competent software architecture plays a vital role. The SQL Databases are designed for structuring data and supporting vertical scalability. In contrast, horizontal scalability is backed by NoSQL Databases and can process sizeable unstructured Data efficiently. One can choose the right paradigm according to the organisation's needs; however, making the correct choice can often be challenging. The SQL and NoSQL Databases follow different architectures. Also, the mixed model is followed by each category of NoSQL Databases. Hence, data movement becomes difficult for cloud consumers across multiple cloud service providers (CSPs). In addition, each cloud platform IaaS, PaaS, SaaS, and DBaaS also monitors various paradigms. Objective: This systematic literature review (SLR) aims to study the related articles associated with SQL and NoSQL Database software architectures and tackle data portability and Interoperability among various cloud platforms. State of the art presented many performance comparison studies of SQL and NoSQL Databases by observing scaling, performance, availability, consistency and sharding characteristics. According to the research studies, NoSQL Database designed structures can be the right choice for big data analytics, while SQL Databases are suitable for OLTP Databases. The researcher proposes numerous approaches associated with data movement in the cloud. Platform-based APIs are developed, which makes users' data movement difficult. Therefore, data portability and Interoperability issues are noticed during data movement across multiple CSPs. To minimize developer efforts and Interoperability, Unified APIs are demanded to make data movement relatively more accessible among various cloud platforms.