 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEM-Net: Gaze Estimation with Expectation Maximization Algorithm
Dec 11, 2024



In recent years, the accuracy of gaze estimation techniques has gradually improved, but existing methods often rely on large datasets or large models to improve performance, which leads to high demands on computational resources. In terms of this issue, this paper proposes a lightweight gaze estimation model EM-Net based on deep learning and traditional machine learning algorithms Expectation Maximization algorithm. First, the proposed Global Attention Mechanism(GAM) is added to extract features related to gaze estimation to improve the model's ability to capture global dependencies and thus improve its performance. Second, by learning hierarchical feature representations through the EM module, the model has strong generalization ability, which reduces the need for sample size. Experiments have confirmed that, on the premise of using only 50% of the training data, EM-Net improves the performance of Gaze360, MPIIFaceGaze, and RT-Gene datasets by 2.2%, 2.02%, and 2.03%, respectively, compared with GazeNAS-ETH. It also shows good robustness in the face of Gaussian noise interference.
Multi-task Gaze Estimation Via Unidirectional Convolution
Nov 27, 2024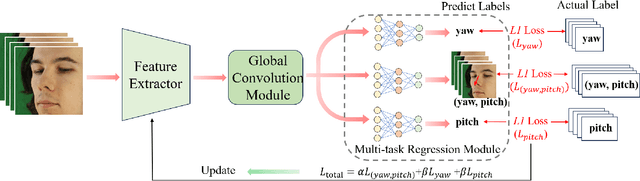
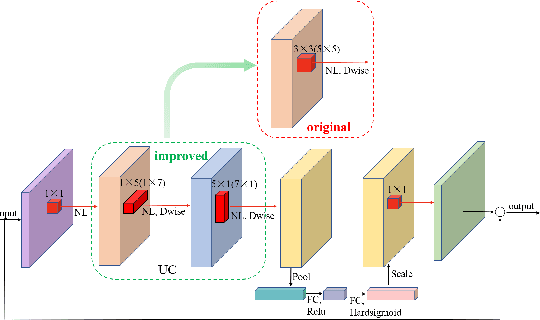
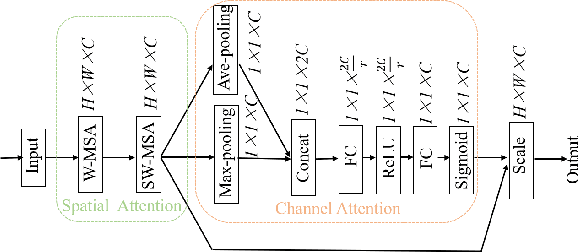
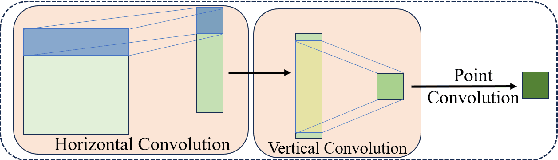
Using lightweight models as backbone networks in gaze estimation tasks often results in significant performance degradation. The main reason is that the number of feature channels in lightweight networks is usually small, which makes the model expression ability limited. In order to improve the performance of lightweight models in gaze estimation tasks, a network model named Multitask-Gaze is proposed. The main components of Multitask-Gaze include Unidirectional Convolution (UC), Spatial and Channel Attention (SCA), Global Convolution Module (GCM), and Multi-task Regression Module(MRM). UC not only significantly reduces the number of parameters and FLOPs, but also extends the receptive field and improves the long-distance modeling capability of the model, thereby improving the model performance. SCA highlights gaze-related features and suppresses gaze-irrelevant features. The GCM replaces the pooling layer and avoids the performance degradation due to information loss. MRM improves the accuracy of individual tasks and strengthens the connections between tasks for overall performance improvement. The experimental results show that compared with the State-of-the-art method SUGE, the performance of Multitask-Gaze on MPIIFaceGaze and Gaze360 datasets is improved by 1.71% and 2.75%, respectively, while the number of parameters and FLOPs are significantly reduced by 75.5% and 86.88%.
Lightweight Gaze Estimation Model Via Fusion Global Information
Nov 27, 2024



Deep learning-based appearance gaze estimation methods are gaining popularity due to their high accuracy and fewer constraints from the environment. However, existing high-precision models often rely on deeper networks, leading to problems such as large parameters, long training time, and slow convergence. In terms of this issue, this paper proposes a novel lightweight gaze estimation model FGI-Net(Fusion Global Information). The model fuses global information into the CNN, effectively compensating for the need of multi-layer convolution and pooling to indirectly capture global information, while reducing the complexity of the model, improving the model accuracy and convergence speed. To validate the performance of the model, a large number of experiments are conducted, comparing accuracy with existing classical models and lightweight models, comparing convergence speed with models of different architectures, and conducting ablation experiments. Experimental results show that compared with GazeCaps, the latest gaze estimation model, FGI-Net achieves a smaller angle error with 87.1% and 79.1% reduction in parameters and FLOPs, respectively (MPIIFaceGaze is 3.74{\deg}, EyeDiap is 5.15{\deg}, Gaze360 is 10.50{\deg} and RT-Gene is 6.02{\deg}). Moreover, compared with different architectural models such as CNN and Transformer, FGI-Net is able to quickly converge to a higher accuracy range with fewer iterations of training, when achieving optimal accuracy on the Gaze360 and EyeDiap datasets, the FGI-Net model has 25% and 37.5% fewer iterations of training compared to GazeTR, respectively.
SQL and NoSQL Databases Software architectures performance analysis and assessments -- A Systematic Literature review
Sep 14, 2022
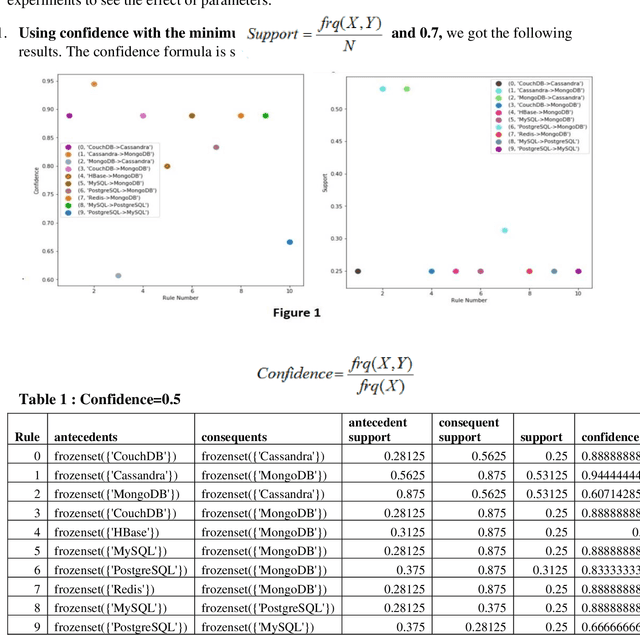
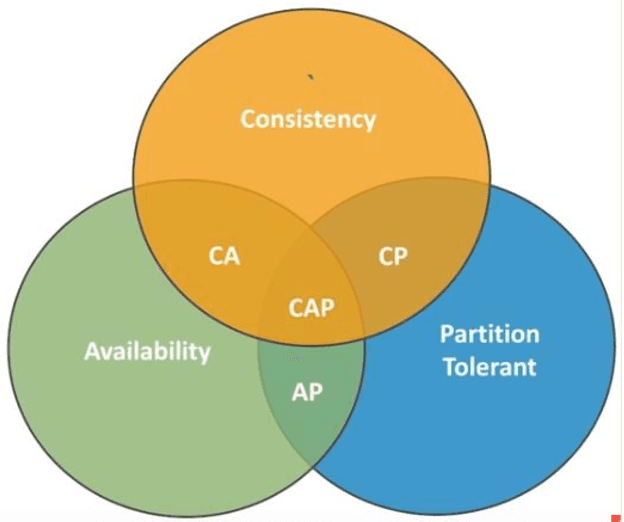
Context: The efficient processing of Big Data is a challenging task for SQL and NoSQL Databases, where competent software architecture plays a vital role. The SQL Databases are designed for structuring data and supporting vertical scalability. In contrast, horizontal scalability is backed by NoSQL Databases and can process sizeable unstructured Data efficiently. One can choose the right paradigm according to the organisation's needs; however, making the correct choice can often be challenging. The SQL and NoSQL Databases follow different architectures. Also, the mixed model is followed by each category of NoSQL Databases. Hence, data movement becomes difficult for cloud consumers across multiple cloud service providers (CSPs). In addition, each cloud platform IaaS, PaaS, SaaS, and DBaaS also monitors various paradigms. Objective: This systematic literature review (SLR) aims to study the related articles associated with SQL and NoSQL Database software architectures and tackle data portability and Interoperability among various cloud platforms. State of the art presented many performance comparison studies of SQL and NoSQL Databases by observing scaling, performance, availability, consistency and sharding characteristics. According to the research studies, NoSQL Database designed structures can be the right choice for big data analytics, while SQL Databases are suitable for OLTP Databases. The researcher proposes numerous approaches associated with data movement in the cloud. Platform-based APIs are developed, which makes users' data movement difficult. Therefore, data portability and Interoperability issues are noticed during data movement across multiple CSPs. To minimize developer efforts and Interoperability, Unified APIs are demanded to make data movement relatively more accessible among various cloud platforms.
PatchFormer: An Efficient Point Transformer with Patch Attention
Dec 02, 2021
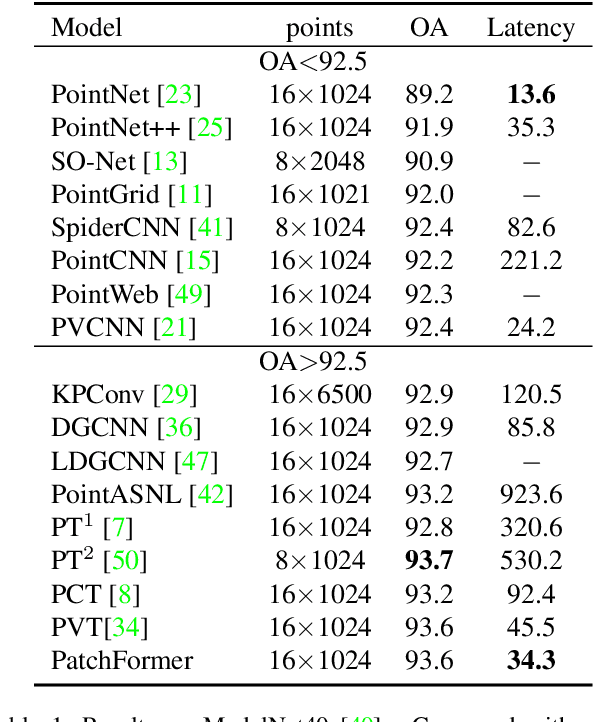
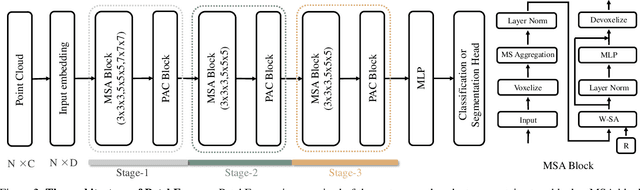
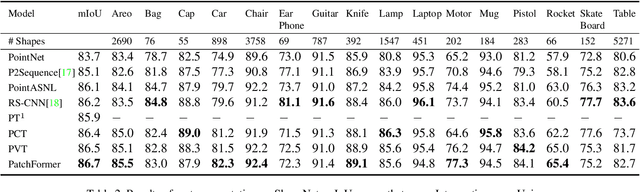
The point cloud learning community is witnesses a modeling shift from CNNs to Transformers, where pure Transformer architectures have achieved top accuracy on the major learning benchmarks. However, existing point Transformers are computationally expensive since they need to generate a large attention map, which has quadratic complexity (both in space and time) with respect to input size. To solve this shortcoming, we introduce Patch attention (PAT) to adaptively learn a much smaller set of bases upon which the attention maps are computed. By a weighted summation upon these bases, PAT not only captures the global shape context but also achieves linear complexity to input size. In addition, we propose a lightweight Multi-scale attention (MST) block to build attentions among features of different scales, providing the model with multi-scale features. Equipped with the PAT and MST, we construct our neural architecture called PatchFormer that integrates both modules into a joint framework for point cloud learning. Extensive experiments demonstrate that our network achieves comparable accuracy on general point cloud learning tasks with 9.2x speed-up than previous point Transformers.