 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloPath: An Entity-Centric Foundation Model for Glomerular Lesion Assessment and Clinicopathological Insights
Mar 03, 2026Glomerular pathology is central to the diagnosis and prognosis of renal diseases, yet the heterogeneity of glomerular morphology and fine-grained lesion patterns remain challenging for current AI approaches. We present GloPath, an entity-centric foundation model trained on over one million glomeruli extracted from 14,049 renal biopsy specimens using multi-scale and multi-view self-supervised learning. GloPath addresses two major challenges in nephropathology: glomerular lesion assessment and clinicopathological insights discovery. For lesion assessment, GloPath was benchmarked across three independent cohorts on 52 tasks, including lesion recognition, grading, few-shot classification, and cross-modality diagnosis-outperforming state-of-the-art methods in 42 tasks (80.8%). In the large-scale real-world study, it achieved an ROC-AUC of 91.51% for lesion recognition, demonstrating strong robustness in routine clinical settings. For clinicopathological insights, GloPath systematically revealed statistically significant associations between glomerular morphological parameters and clinical indicators across 224 morphology-clinical variable pairs, demonstrating its capacity to connect tissue-level pathology with patient-level outcomes. Together, these results position GloPath as a scalable and interpretable platform for glomerular lesion assessment and clinicopathological discovery, representing a step toward clinically translatable AI in renal pathology.
EM-Net: Gaze Estimation with Expectation Maximization Algorithm
Dec 11, 2024



In recent years, the accuracy of gaze estimation techniques has gradually improved, but existing methods often rely on large datasets or large models to improve performance, which leads to high demands on computational resources. In terms of this issue, this paper proposes a lightweight gaze estimation model EM-Net based on deep learning and traditional machine learning algorithms Expectation Maximization algorithm. First, the proposed Global Attention Mechanism(GAM) is added to extract features related to gaze estimation to improve the model's ability to capture global dependencies and thus improve its performance. Second, by learning hierarchical feature representations through the EM module, the model has strong generalization ability, which reduces the need for sample size. Experiments have confirmed that, on the premise of using only 50% of the training data, EM-Net improves the performance of Gaze360, MPIIFaceGaze, and RT-Gene datasets by 2.2%, 2.02%, and 2.03%, respectively, compared with GazeNAS-ETH. It also shows good robustness in the face of Gaussian noise interference.
Multi-task Gaze Estimation Via Unidirectional Convolution
Nov 27, 2024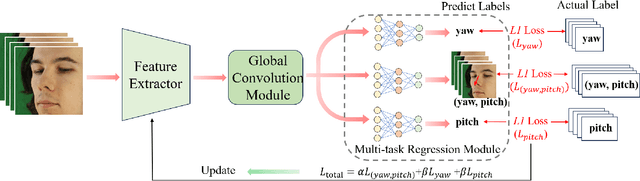
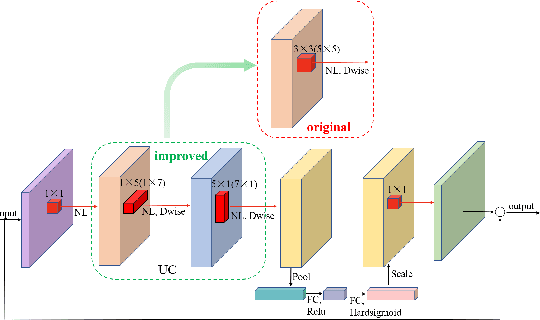
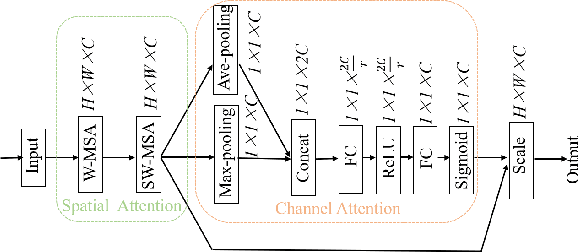
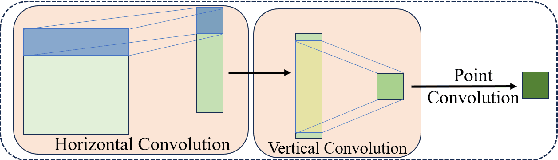
Using lightweight models as backbone networks in gaze estimation tasks often results in significant performance degradation. The main reason is that the number of feature channels in lightweight networks is usually small, which makes the model expression ability limited. In order to improve the performance of lightweight models in gaze estimation tasks, a network model named Multitask-Gaze is proposed. The main components of Multitask-Gaze include Unidirectional Convolution (UC), Spatial and Channel Attention (SCA), Global Convolution Module (GCM), and Multi-task Regression Module(MRM). UC not only significantly reduces the number of parameters and FLOPs, but also extends the receptive field and improves the long-distance modeling capability of the model, thereby improving the model performance. SCA highlights gaze-related features and suppresses gaze-irrelevant features. The GCM replaces the pooling layer and avoids the performance degradation due to information loss. MRM improves the accuracy of individual tasks and strengthens the connections between tasks for overall performance improvement. The experimental results show that compared with the State-of-the-art method SUGE, the performance of Multitask-Gaze on MPIIFaceGaze and Gaze360 datasets is improved by 1.71% and 2.75%, respectively, while the number of parameters and FLOPs are significantly reduced by 75.5% and 86.88%.
Lightweight Gaze Estimation Model Via Fusion Global Information
Nov 27, 2024



Deep learning-based appearance gaze estimation methods are gaining popularity due to their high accuracy and fewer constraints from the environment. However, existing high-precision models often rely on deeper networks, leading to problems such as large parameters, long training time, and slow convergence. In terms of this issue, this paper proposes a novel lightweight gaze estimation model FGI-Net(Fusion Global Information). The model fuses global information into the CNN, effectively compensating for the need of multi-layer convolution and pooling to indirectly capture global information, while reducing the complexity of the model, improving the model accuracy and convergence speed. To validate the performance of the model, a large number of experiments are conducted, comparing accuracy with existing classical models and lightweight models, comparing convergence speed with models of different architectures, and conducting ablation experiments. Experimental results show that compared with GazeCaps, the latest gaze estimation model, FGI-Net achieves a smaller angle error with 87.1% and 79.1% reduction in parameters and FLOPs, respectively (MPIIFaceGaze is 3.74{\deg}, EyeDiap is 5.15{\deg}, Gaze360 is 10.50{\deg} and RT-Gene is 6.02{\deg}). Moreover, compared with different architectural models such as CNN and Transformer, FGI-Net is able to quickly converge to a higher accuracy range with fewer iterations of training, when achieving optimal accuracy on the Gaze360 and EyeDiap datasets, the FGI-Net model has 25% and 37.5% fewer iterations of training compared to GazeTR, respectively.