 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecise Single-stage Detector
Oct 09, 2022
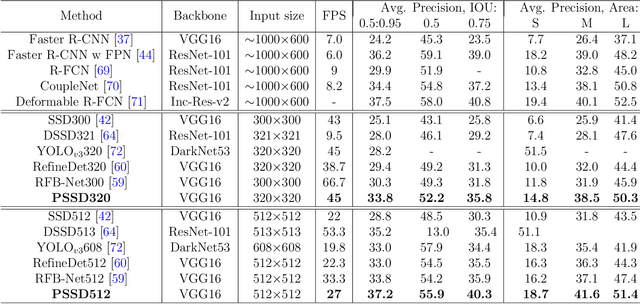
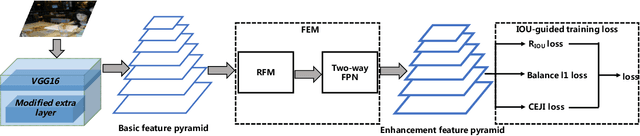

There are still two problems in SDD causing some inaccurate results: (1) In the process of feature extraction, with the layer-by-layer acquisition of semantic information, local information is gradually lost, resulting into less representative feature maps; (2) During the Non-Maximum Suppression (NMS) algorithm due to inconsistency in classification and regression tasks, the classification confidence and predicted detection position cannot accurately indicate the position of the prediction boxes. Methods: In order to address these aforementioned issues, we propose a new architecture, a modified version of Single Shot Multibox Detector (SSD), named Precise Single Stage Detector (PSSD). Firstly, we improve the features by adding extra layers to SSD. Secondly, we construct a simple and effective feature enhancement module to expand the receptive field step by step for each layer and enhance its local and semantic information. Finally, we design a more efficient loss function to predict the IOU between the prediction boxes and ground truth boxes, and the threshold IOU guides classification training and attenuates the scores, which are used by the NMS algorithm. Main Results: Benefiting from the above optimization, the proposed model PSSD achieves exciting performance in real-time. Specifically, with the hardware of Titan Xp and the input size of 320 pix, PSSD achieves 33.8 mAP at 45 FPS speed on MS COCO benchmark and 81.28 mAP at 66 FPS speed on Pascal VOC 2007 outperforming state-of-the-art object detection models. Besides, the proposed model performs significantly well with larger input size. Under 512 pix, PSSD can obtain 37.2 mAP with 27 FPS on MS COCO and 82.82 mAP with 40 FPS on Pascal VOC 2007. The experiment results prove that the proposed model has a better trade-off between speed and accuracy.
SQL and NoSQL Databases Software architectures performance analysis and assessments -- A Systematic Literature review
Sep 14, 2022
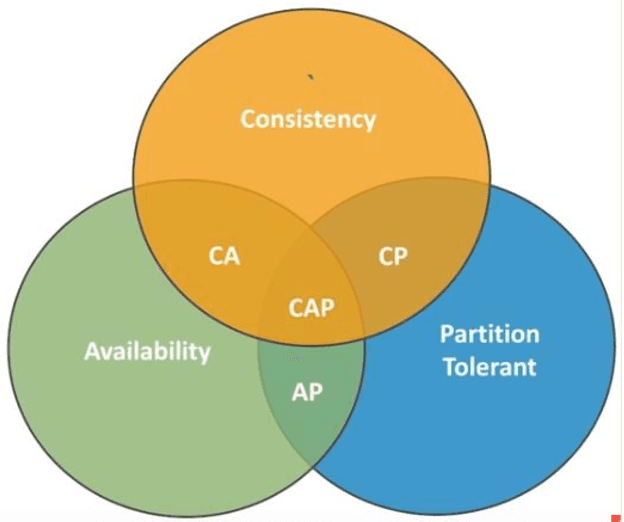
Context: The efficient processing of Big Data is a challenging task for SQL and NoSQL Databases, where competent software architecture plays a vital role. The SQL Databases are designed for structuring data and supporting vertical scalability. In contrast, horizontal scalability is backed by NoSQL Databases and can process sizeable unstructured Data efficiently. One can choose the right paradigm according to the organisation's needs; however, making the correct choice can often be challenging. The SQL and NoSQL Databases follow different architectures. Also, the mixed model is followed by each category of NoSQL Databases. Hence, data movement becomes difficult for cloud consumers across multiple cloud service providers (CSPs). In addition, each cloud platform IaaS, PaaS, SaaS, and DBaaS also monitors various paradigms. Objective: This systematic literature review (SLR) aims to study the related articles associated with SQL and NoSQL Database software architectures and tackle data portability and Interoperability among various cloud platforms. State of the art presented many performance comparison studies of SQL and NoSQL Databases by observing scaling, performance, availability, consistency and sharding characteristics. According to the research studies, NoSQL Database designed structures can be the right choice for big data analytics, while SQL Databases are suitable for OLTP Databases. The researcher proposes numerous approaches associated with data movement in the cloud. Platform-based APIs are developed, which makes users' data movement difficult. Therefore, data portability and Interoperability issues are noticed during data movement across multiple CSPs. To minimize developer efforts and Interoperability, Unified APIs are demanded to make data movement relatively more accessible among various cloud platforms.