 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Dimension Reduction makes ML Algorithms efficient
Nov 17, 2022



Data dimension reduction (DDR) is all about mapping data from high dimensions to low dimensions, various techniques of DDR are being used for image dimension reduction like Random Projections, Principal Component Analysis (PCA), the Variance approach, LSA-Transform, the Combined and Direct approaches, and the New Random Approach. Auto-encoders (AE) are used to learn end-to-end mapping. In this paper, we demonstrate that pre-processing not only speeds up the algorithms but also improves accuracy in both supervised and unsupervised learning. In pre-processing of DDR, first PCA based DDR is used for supervised learning, then we explore AE based DDR for unsupervised learning. In PCA based DDR, we first compare supervised learning algorithms accuracy and time before and after applying PCA. Similarly, in AE based DDR, we compare unsupervised learning algorithm accuracy and time before and after AE representation learning. Supervised learning algorithms including support-vector machines (SVM), Decision Tree with GINI index, Decision Tree with entropy and Stochastic Gradient Descent classifier (SGDC) and unsupervised learning algorithm including K-means clustering, are used for classification purpose. We used two datasets MNIST and FashionMNIST Our experiment shows that there is massive improvement in accuracy and time reduction after pre-processing in both supervised and unsupervised learning.
SQL and NoSQL Databases Software architectures performance analysis and assessments -- A Systematic Literature review
Sep 14, 2022
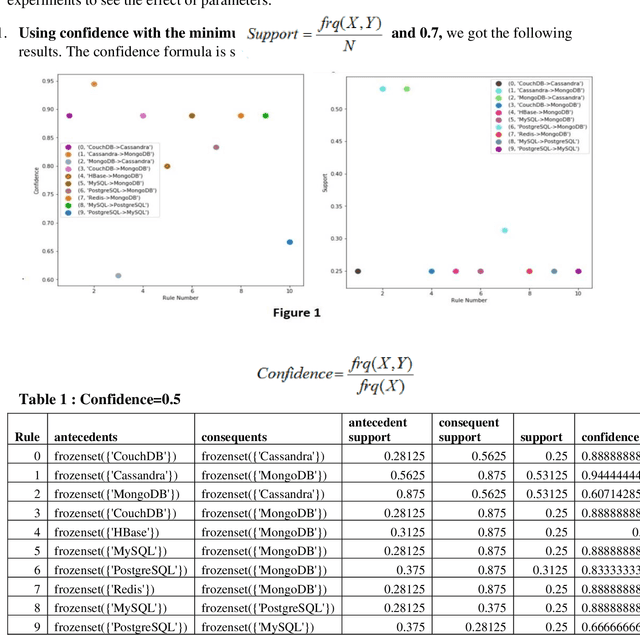
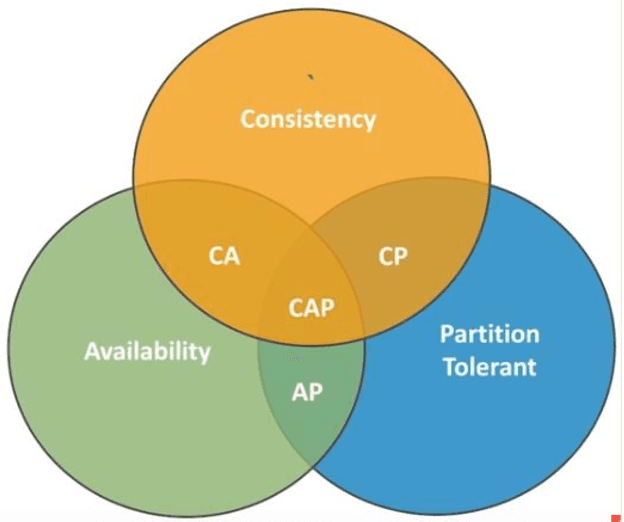
Context: The efficient processing of Big Data is a challenging task for SQL and NoSQL Databases, where competent software architecture plays a vital role. The SQL Databases are designed for structuring data and supporting vertical scalability. In contrast, horizontal scalability is backed by NoSQL Databases and can process sizeable unstructured Data efficiently. One can choose the right paradigm according to the organisation's needs; however, making the correct choice can often be challenging. The SQL and NoSQL Databases follow different architectures. Also, the mixed model is followed by each category of NoSQL Databases. Hence, data movement becomes difficult for cloud consumers across multiple cloud service providers (CSPs). In addition, each cloud platform IaaS, PaaS, SaaS, and DBaaS also monitors various paradigms. Objective: This systematic literature review (SLR) aims to study the related articles associated with SQL and NoSQL Database software architectures and tackle data portability and Interoperability among various cloud platforms. State of the art presented many performance comparison studies of SQL and NoSQL Databases by observing scaling, performance, availability, consistency and sharding characteristics. According to the research studies, NoSQL Database designed structures can be the right choice for big data analytics, while SQL Databases are suitable for OLTP Databases. The researcher proposes numerous approaches associated with data movement in the cloud. Platform-based APIs are developed, which makes users' data movement difficult. Therefore, data portability and Interoperability issues are noticed during data movement across multiple CSPs. To minimize developer efforts and Interoperability, Unified APIs are demanded to make data movement relatively more accessible among various cloud platforms.