 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards generating more interpretable counterfactuals via concept vectors: a preliminary study on chest X-rays
Jun 04, 2025An essential step in deploying medical imaging models is ensuring alignment with clinical knowledge and interpretability. We focus on mapping clinical concepts into the latent space of generative models to identify Concept Activation Vectors (CAVs). Using a simple reconstruction autoencoder, we link user-defined concepts to image-level features without explicit label training. The extracted concepts are stable across datasets, enabling visual explanations that highlight clinically relevant features. By traversing latent space along concept directions, we produce counterfactuals that exaggerate or reduce specific clinical features. Preliminary results on chest X-rays show promise for large pathologies like cardiomegaly, while smaller pathologies remain challenging due to reconstruction limits. Although not outperforming baselines, this approach offers a path toward interpretable, concept-based explanations aligned with clinical knowledge.
TWIG: Two-Step Image Generation using Segmentation Masks in Diffusion Models
Apr 21, 2025In today's age of social media and marketing, copyright issues can be a major roadblock to the free sharing of images. Generative AI models have made it possible to create high-quality images, but concerns about copyright infringement are a hindrance to their abundant use. As these models use data from training images to generate new ones, it is often a daunting task to ensure they do not violate intellectual property rights. Some AI models have even been noted to directly copy copyrighted images, a problem often referred to as source copying. Traditional copyright protection measures such as watermarks and metadata have also proven to be futile in this regard. To address this issue, we propose a novel two-step image generation model inspired by the conditional diffusion model. The first step involves creating an image segmentation mask for some prompt-based generated images. This mask embodies the shape of the image. Thereafter, the diffusion model is asked to generate the image anew while avoiding the shape in question. This approach shows a decrease in structural similarity from the training image, i.e. we are able to avoid the source copying problem using this approach without expensive retraining of the model or user-centered prompt generation techniques. This makes our approach the most computationally inexpensive approach to avoiding both copyright infringement and source copying for diffusion model-based image generation.
Saliency-Based diversity and fairness Metric and FaceKeepOriginalAugment: A Novel Approach for Enhancing Fairness and Diversity
Oct 29, 2024



Data augmentation has become a pivotal tool in enhancing the performance of computer vision tasks, with the KeepOriginalAugment method emerging as a standout technique for its intelligent incorporation of salient regions within less prominent areas, enabling augmentation in both regions. Despite its success in image classification, its potential in addressing biases remains unexplored. In this study, we introduce an extension of the KeepOriginalAugment method, termed FaceKeepOriginalAugment, which explores various debiasing aspects-geographical, gender, and stereotypical biases-in computer vision models. By maintaining a delicate balance between data diversity and information preservation, our approach empowers models to exploit both diverse salient and non-salient regions, thereby fostering increased diversity and debiasing effects. We investigate multiple strategies for determining the placement of the salient region and swapping perspectives to decide which part undergoes augmentation. Leveraging the Image Similarity Score (ISS), we quantify dataset diversity across a range of datasets, including Flickr Faces HQ (FFHQ), WIKI, IMDB, Labelled Faces in the Wild (LFW), UTK Faces, and Diverse Dataset. We evaluate the effectiveness of FaceKeepOriginalAugment in mitigating gender bias across CEO, Engineer, Nurse, and School Teacher datasets, utilizing the Image-Image Association Score (IIAS) in convolutional neural networks (CNNs) and vision transformers (ViTs). Our findings shows the efficacy of FaceKeepOriginalAugment in promoting fairness and inclusivity within computer vision models, demonstrated by reduced gender bias and enhanced overall fairness. Additionally, we introduce a novel metric, Saliency-Based Diversity and Fairness Metric, which quantifies both diversity and fairness while handling data imbalance across various datasets.
FaceSaliencyAug: Mitigating Geographic, Gender and Stereotypical Biases via Saliency-Based Data Augmentation
Oct 17, 2024
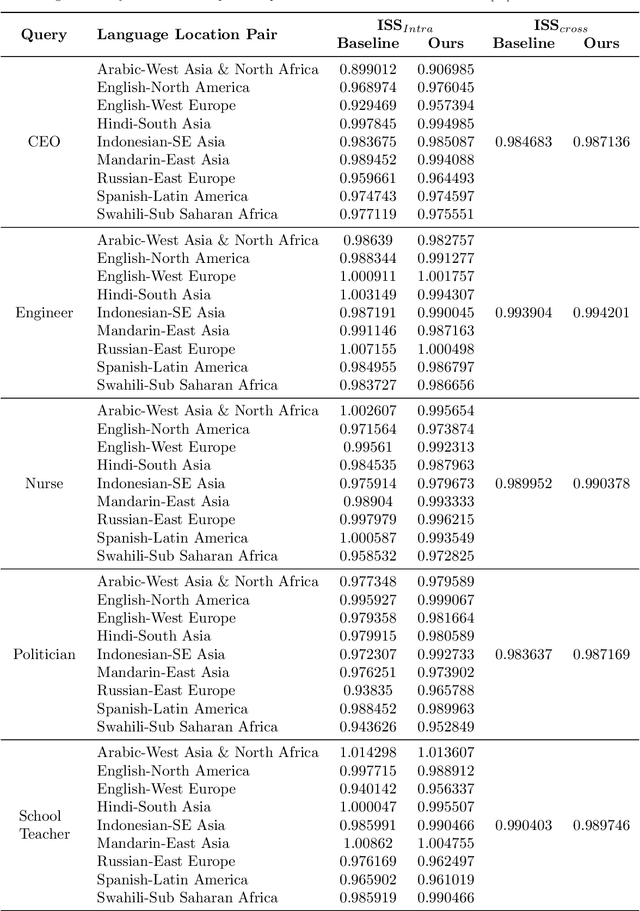
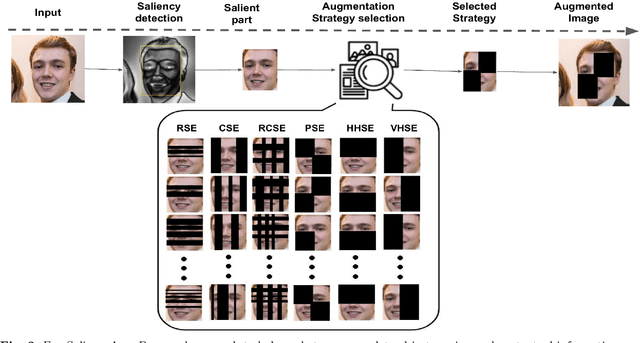
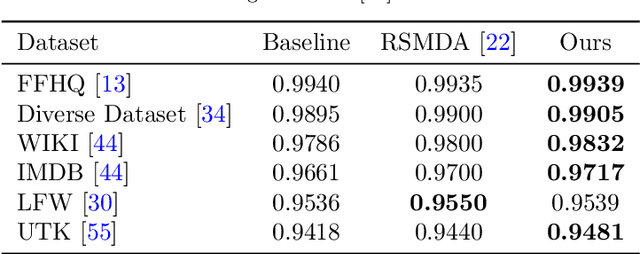
Geographical, gender and stereotypical biases in computer vision models pose significant challenges to their performance and fairness. {In this study, we present an approach named FaceSaliencyAug aimed at addressing the gender bias in} {Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs). Leveraging the salient regions} { of faces detected by saliency, the propose approach mitigates geographical and stereotypical biases } {in the datasets. FaceSaliencyAug} randomly selects masks from a predefined search space and applies them to the salient region of face images, subsequently restoring the original image with masked salient region. {The proposed} augmentation strategy enhances data diversity, thereby improving model performance and debiasing effects. We quantify dataset diversity using Image Similarity Score (ISS) across five datasets, including Flickr Faces HQ (FFHQ), WIKI, IMDB, Labelled Faces in the Wild (LFW), UTK Faces, and Diverse Dataset. The proposed approach demonstrates superior diversity metrics, as evaluated by ISS-intra and ISS-inter algorithms. Furthermore, we evaluate the effectiveness of our approach in mitigating gender bias on CEO, Engineer, Nurse, and School Teacher datasets. We use the Image-Image Association Score (IIAS) to measure gender bias in these occupations. Our experiments reveal a reduction in gender bias for both CNNs and ViTs, indicating the efficacy of our method in promoting fairness and inclusivity in computer vision models.
KeepOriginalAugment: Single Image-based Better Information-Preserving Data Augmentation Approach
May 10, 2024
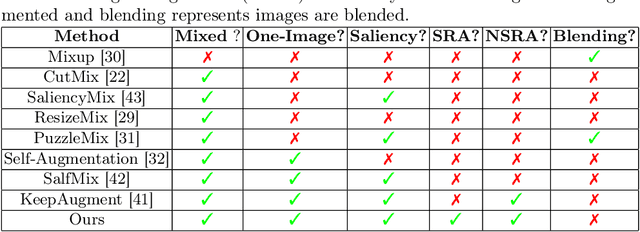

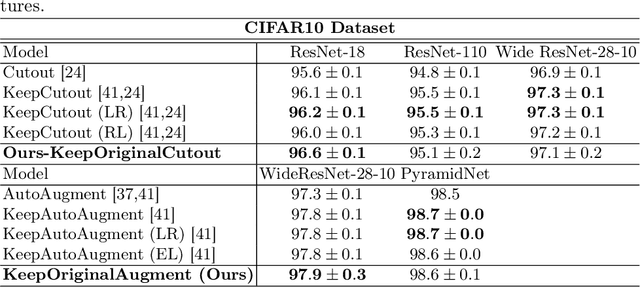
Advanced image data augmentation techniques play a pivotal role in enhancing the training of models for diverse computer vision tasks. Notably, SalfMix and KeepAugment have emerged as popular strategies, showcasing their efficacy in boosting model performance. However, SalfMix reliance on duplicating salient features poses a risk of overfitting, potentially compromising the model's generalization capabilities. Conversely, KeepAugment, which selectively preserves salient regions and augments non-salient ones, introduces a domain shift that hinders the exchange of crucial contextual information, impeding overall model understanding. In response to these challenges, we introduce KeepOriginalAugment, a novel data augmentation approach. This method intelligently incorporates the most salient region within the non-salient area, allowing augmentation to be applied to either region. Striking a balance between data diversity and information preservation, KeepOriginalAugment enables models to leverage both diverse salient and non-salient regions, leading to enhanced performance. We explore three strategies for determining the placement of the salient region minimum, maximum, or random and investigate swapping perspective strategies to decide which part (salient or non-salient) undergoes augmentation. Our experimental evaluations, conducted on classification datasets such as CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate the superior performance of KeepOriginalAugment compared to existing state-of-the-art techniques.
IID Relaxation by Logical Expressivity: A Research Agenda for Fitting Logics to Neurosymbolic Requirements
Apr 30, 2024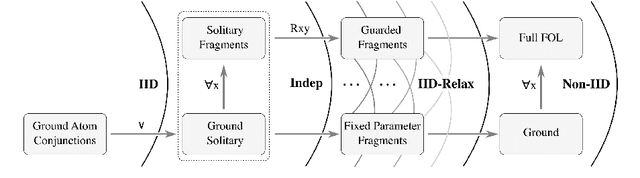
Neurosymbolic background knowledge and the expressivity required of its logic can break Machine Learning assumptions about data Independence and Identical Distribution. In this position paper we propose to analyze IID relaxation in a hierarchy of logics that fit different use case requirements. We discuss the benefits of exploiting known data dependencies and distribution constraints for Neurosymbolic use cases and argue that the expressivity required for this knowledge has implications for the design of underlying ML routines. This opens a new research agenda with general questions about Neurosymbolic background knowledge and the expressivity required of its logic.
A Systematic Review of Available Datasets in Additive Manufacturing
Jan 27, 2024In-situ monitoring incorporating data from visual and other sensor technologies, allows the collection of extensive datasets during the Additive Manufacturing (AM) process. These datasets have potential for determining the quality of the manufactured output and the detection of defects through the use of Machine Learning during the manufacturing process. Open and annotated datasets derived from AM processes are necessary for the machine learning community to address this opportunity, which creates difficulties in the application of computer vision-related machine learning in AM. This systematic review investigates the availability of open image-based datasets originating from AM processes that align with a number of pre-defined selection criteria. The review identifies existing gaps among the current image-based datasets in the domain of AM, and points to the need for greater availability of open datasets in order to allow quality assessment and defect detection during additive manufacturing, to develop.
AudRandAug: Random Image Augmentations for Audio Classification
Sep 09, 2023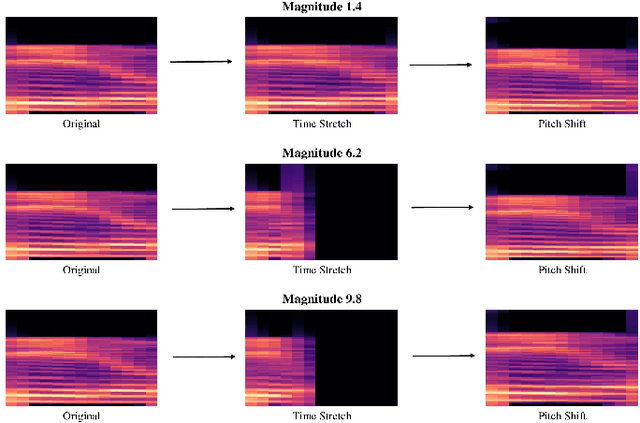

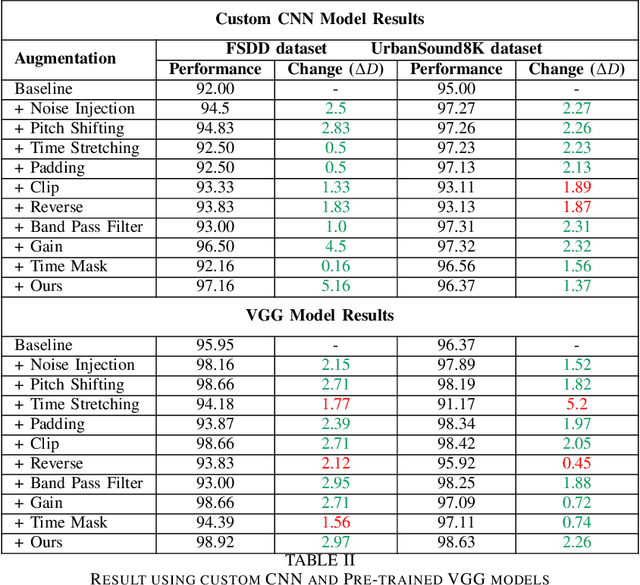
Data augmentation has proven to be effective in training neural networks. Recently, a method called RandAug was proposed, randomly selecting data augmentation techniques from a predefined search space. RandAug has demonstrated significant performance improvements for image-related tasks while imposing minimal computational overhead. However, no prior research has explored the application of RandAug specifically for audio data augmentation, which converts audio into an image-like pattern. To address this gap, we introduce AudRandAug, an adaptation of RandAug for audio data. AudRandAug selects data augmentation policies from a dedicated audio search space. To evaluate the effectiveness of AudRandAug, we conducted experiments using various models and datasets. Our findings indicate that AudRandAug outperforms other existing data augmentation methods regarding accuracy performance.
Proceedings 39th International Conference on Logic Programming
Aug 28, 2023This volume contains the Technical Communications presented at the 39th International Conference on Logic Programming (ICLP 2023), held at Imperial College London, UK from July 9 to July 15, 2023. Technical Communications included here concern the Main Track, the Doctoral Consortium, the Application and Systems/Demo track, the Recently Published Research Track, the Birds-of-a-Feather track, the Thematic Tracks on Logic Programming and Machine Learning, and Logic Programming and Explainability, Ethics, and Trustworthiness.
Defect Classification in Additive Manufacturing Using CNN-Based Vision Processing
Jul 14, 2023The development of computer vision and in-situ monitoring using visual sensors allows the collection of large datasets from the additive manufacturing (AM) process. Such datasets could be used with machine learning techniques to improve the quality of AM. This paper examines two scenarios: first, using convolutional neural networks (CNNs) to accurately classify defects in an image dataset from AM and second, applying active learning techniques to the developed classification model. This allows the construction of a human-in-the-loop mechanism to reduce the size of the data required to train and generate training data.