 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeepOriginalAugment: Single Image-based Better Information-Preserving Data Augmentation Approach
Paper and Code
May 10, 2024
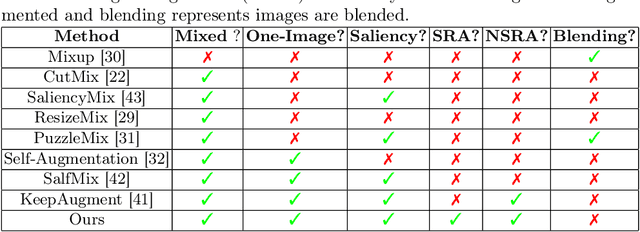

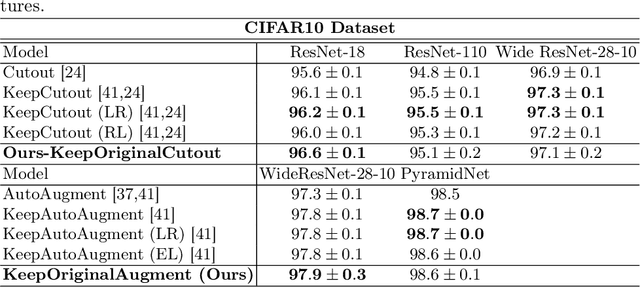
Advanced image data augmentation techniques play a pivotal role in enhancing the training of models for diverse computer vision tasks. Notably, SalfMix and KeepAugment have emerged as popular strategies, showcasing their efficacy in boosting model performance. However, SalfMix reliance on duplicating salient features poses a risk of overfitting, potentially compromising the model's generalization capabilities. Conversely, KeepAugment, which selectively preserves salient regions and augments non-salient ones, introduces a domain shift that hinders the exchange of crucial contextual information, impeding overall model understanding. In response to these challenges, we introduce KeepOriginalAugment, a novel data augmentation approach. This method intelligently incorporates the most salient region within the non-salient area, allowing augmentation to be applied to either region. Striking a balance between data diversity and information preservation, KeepOriginalAugment enables models to leverage both diverse salient and non-salient regions, leading to enhanced performance. We explore three strategies for determining the placement of the salient region minimum, maximum, or random and investigate swapping perspective strategies to decide which part (salient or non-salient) undergoes augmentation. Our experimental evaluations, conducted on classification datasets such as CIFAR-10, CIFAR-100, and TinyImageNet, demonstrate the superior performance of KeepOriginalAugment compared to existing state-of-the-art techniques.