Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIID Relaxation by Logical Expressivity: A Research Agenda for Fitting Logics to Neurosymbolic Requirements
Paper and Code
Apr 30, 2024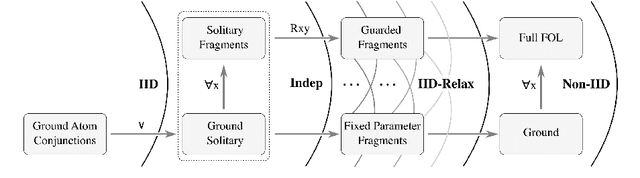
Neurosymbolic background knowledge and the expressivity required of its logic can break Machine Learning assumptions about data Independence and Identical Distribution. In this position paper we propose to analyze IID relaxation in a hierarchy of logics that fit different use case requirements. We discuss the benefits of exploiting known data dependencies and distribution constraints for Neurosymbolic use cases and argue that the expressivity required for this knowledge has implications for the design of underlying ML routines. This opens a new research agenda with general questions about Neurosymbolic background knowledge and the expressivity required of its logic.
* 12 pages, 2 figures, submitted to NeSy 2024
View paper on