 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Dance Video Archives Challenge Computer Vision
May 12, 2025The accuracy and efficiency of human body pose estimation depend on the quality of the data to be processed and of the particularities of these data. To demonstrate how dance videos can challenge pose estimation techniques, we proposed a new 3D human body pose estimation pipeline which combined up-to-date techniques and methods that had not been yet used in dance analysis. Second, we performed tests and extensive experimentations from dance video archives, and used visual analytic tools to evaluate the impact of several data parameters on human body pose. Our results are publicly available for research at https://www.couleur.org/articles/arXiv-1-2025/
Emotion Recognition in Contemporary Dance Performances Using Laban Movement Analysis
Apr 29, 2025This paper presents a novel framework for emotion recognition in contemporary dance by improving existing Laban Movement Analysis (LMA) feature descriptors and introducing robust, novel descriptors that capture both quantitative and qualitative aspects of the movement. Our approach extracts expressive characteristics from 3D keypoints data of professional dancers performing contemporary dance under various emotional states, and trains multiple classifiers, including Random Forests and Support Vector Machines. Additionally, we provide in-depth explanation of features and their impact on model predictions using explainable machine learning methods. Overall, our study improves emotion recognition in contemporary dance and offers promising applications in performance analysis, dance training, and human--computer interaction, with a highest accuracy of 96.85\%.
Dance Style Recognition Using Laban Movement Analysis
Apr 29, 2025



The growing interest in automated movement analysis has presented new challenges in recognition of complex human activities including dance. This study focuses on dance style recognition using features extracted using Laban Movement Analysis. Previous studies for dance style recognition often focus on cross-frame movement analysis, which limits the ability to capture temporal context and dynamic transitions between movements. This gap highlights the need for a method that can add temporal context to LMA features. For this, we introduce a novel pipeline which combines 3D pose estimation, 3D human mesh reconstruction, and floor aware body modeling to effectively extract LMA features. To address the temporal limitation, we propose a sliding window approach that captures movement evolution across time in features. These features are then used to train various machine learning methods for classification, and their explainability explainable AI methods to evaluate the contribution of each feature to classification performance. Our proposed method achieves a highest classification accuracy of 99.18\% which shows that the addition of temporal context significantly improves dance style recognition performance.
Survey of 3D Human Body Pose and Shape Estimation Methods for Contemporary Dance Applications
Jan 04, 20243D human body shape and pose estimation from RGB images is a challenging problem with potential applications in augmented/virtual reality, healthcare and fitness technology and virtual retail. Recent solutions have focused on three types of inputs: i) single images, ii) multi-view images and iii) videos. In this study, we surveyed and compared 3D body shape and pose estimation methods for contemporary dance and performing arts, with a special focus on human body pose and dressing, camera viewpoint, illumination conditions and background conditions. We demonstrated that multi-frame methods, such as PHALP, provide better results than single-frame method for pose estimation when dancers are performing contemporary dances.
Deep Learning for Material recognition: most recent advances and open challenges
Dec 14, 2020
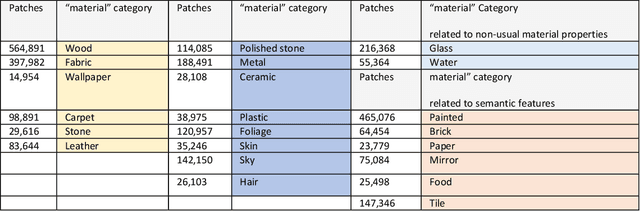
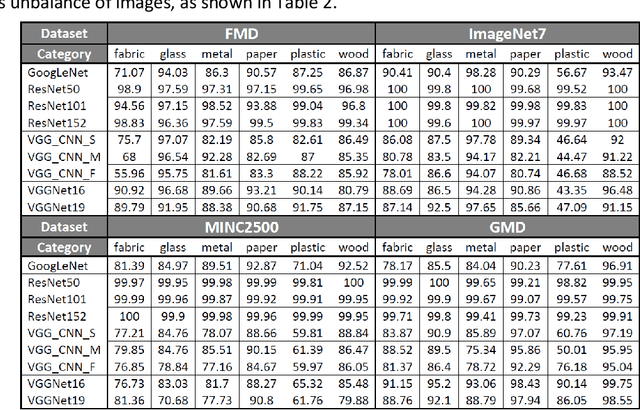

Recognizing material from color images is still a challenging problem today. While deep neural networks provide very good results on object recognition and has been the topic of a huge amount of papers in the last decade, their adaptation to material images still requires some works to reach equivalent accuracies. Nevertheless, recent studies achieve very good results in material recognition with deep learning and we propose, in this paper, to review most of them by focusing on three aspects: material image datasets, influence of the context and ad hoc descriptors for material appearance. Every aspect is introduced by a systematic manner and results from representative works are cited. We also present our own studies in this area and point out some open challenges for future works.
Deep Spectral Reflectance and Illuminant Estimation from Self-Interreflections
Dec 09, 2018
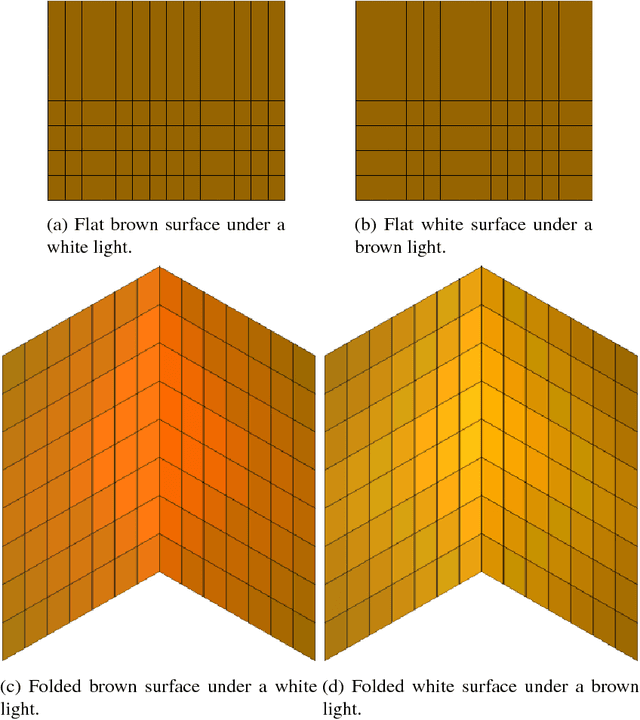
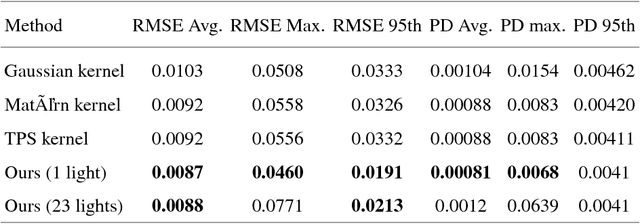
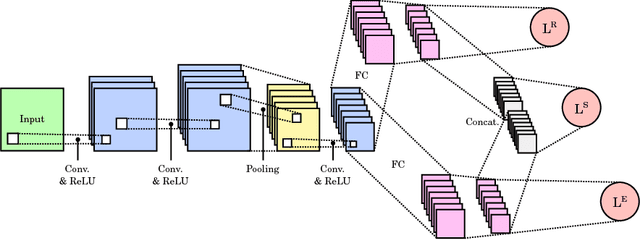
In this work, we propose a CNN-based approach to estimate the spectral reflectance of a surface and the spectral power distribution of the light from a single RGB image of a V-shaped surface. Interreflections happening in a concave surface lead to gradients of RGB values over its area. These gradients carry a lot of information concerning the physical properties of the surface and the illuminant. Our network is trained with only simulated data constructed using a physics-based interreflection model. Coupling interreflection effects with deep learning helps to retrieve the spectral reflectance under an unknown light and to estimate the spectral power distribution of this light as well. In addition, it is more robust to the presence of image noise than the classical approaches. Our results show that the proposed approach outperforms the state of the art learning-based approaches on simulated data. In addition, it gives better results on real data compared to other interreflection-based approaches.
Spectral reflectance estimation from one RGB image using self-interreflections in a concave object
Mar 05, 2018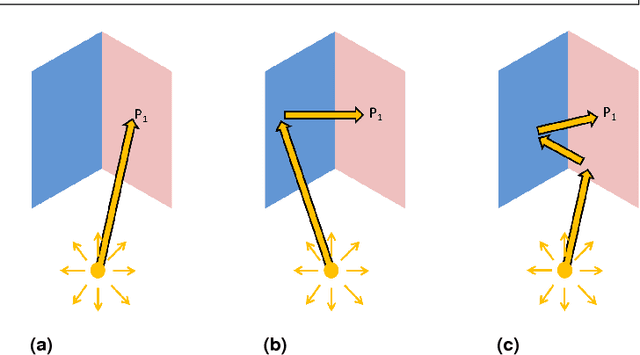
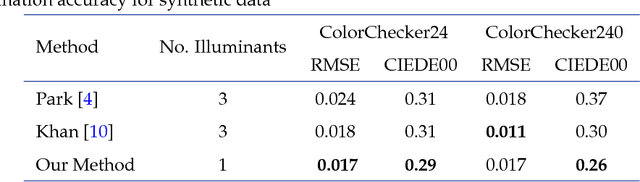
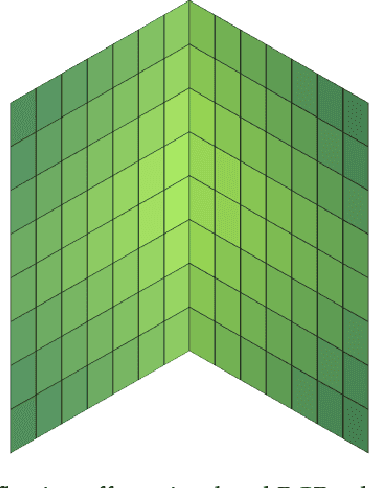
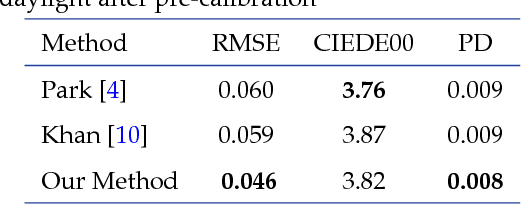
Light interreflections occurring in a concave object generate a color gradient which is characteristic of the object's spectral reflectance. In this paper, we use this property in order to estimate the spectral reflectance of matte, uniformly colored, V-shaped surfaces from a single RGB image taken under directional lighting. First, simulations show that using one image of the concave object is equivalent to, and can even outperform, the state of the art approaches based on three images taken under three lightings with different colors. Experiments on real images of folded papers were performed under unmeasured direct sunlight. The results show that our interreflection-based approach outperforms existing approaches even when the latter are improved by a calibration step. The mathematical solution for the interreflection equation and the effect of surface parameters on the performance of the method are also discussed in this paper.
Residual Conv-Deconv Grid Network for Semantic Segmentation
Jul 26, 2017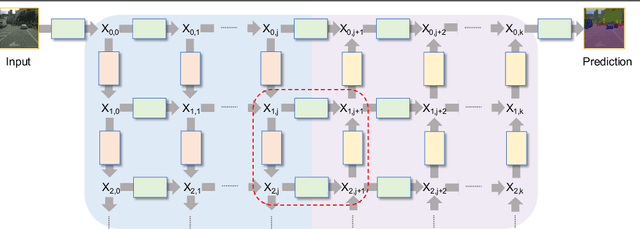
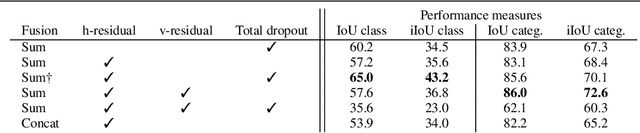
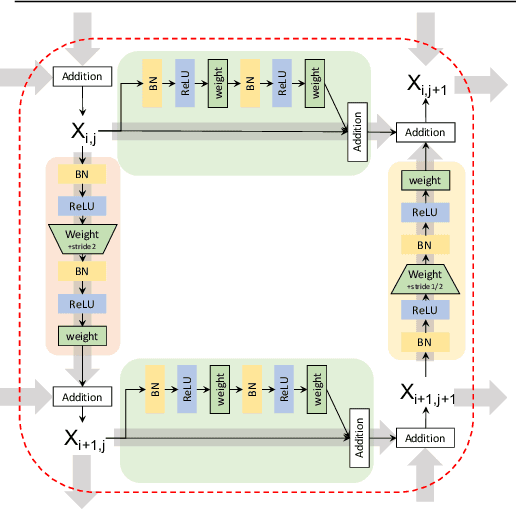

This paper presents GridNet, a new Convolutional Neural Network (CNN) architecture for semantic image segmentation (full scene labelling). Classical neural networks are implemented as one stream from the input to the output with subsampling operators applied in the stream in order to reduce the feature maps size and to increase the receptive field for the final prediction. However, for semantic image segmentation, where the task consists in providing a semantic class to each pixel of an image, feature maps reduction is harmful because it leads to a resolution loss in the output prediction. To tackle this problem, our GridNet follows a grid pattern allowing multiple interconnected streams to work at different resolutions. We show that our network generalizes many well known networks such as conv-deconv, residual or U-Net networks. GridNet is trained from scratch and achieves competitive results on the Cityscapes dataset.
MidRank: Learning to rank based on subsequences
Nov 29, 2015



We present a supervised learning to rank algorithm that effectively orders images by exploiting the structure in image sequences. Most often in the supervised learning to rank literature, ranking is approached either by analyzing pairs of images or by optimizing a list-wise surrogate loss function on full sequences. In this work we propose MidRank, which learns from moderately sized sub-sequences instead. These sub-sequences contain useful structural ranking information that leads to better learnability during training and better generalization during testing. By exploiting sub-sequences, the proposed MidRank improves ranking accuracy considerably on an extensive array of image ranking applications and datasets.