 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbnormal Event Detection In Videos Using Deep Embedding
Sep 15, 2024Abnormal event detection or anomaly detection in surveillance videos is currently a challenge because of the diversity of possible events. Due to the lack of anomalous events at training time, anomaly detection requires the design of learning methods without supervision. In this work we propose an unsupervised approach for video anomaly detection with the aim to jointly optimize the objectives of the deep neural network and the anomaly detection task using a hybrid architecture. Initially, a convolutional autoencoder is pre-trained in an unsupervised manner with a fusion of depth, motion and appearance features. In the second step, we utilize the encoder part of the pre-trained autoencoder and extract the embeddings of the fused input. Now, we jointly train/ fine tune the encoder to map the embeddings to a hypercenter. Thus, embeddings of normal data fall near the hypercenter, whereas embeddings of anomalous data fall far away from the hypercenter.
RSD-DOG : A New Image Descriptor based on Second Order Derivatives
Aug 14, 2024This paper introduces the new and powerful image patch descriptor based on second order image statistics/derivatives. Here, the image patch is treated as a 3D surface with intensity being the 3rd dimension. The considered 3D surface has a rich set of second order features/statistics such as ridges, valleys, cliffs and so on, that can be easily captured by using the difference of rotating semi Gaussian filters. The originality of this method is based on successfully combining the response of the directional filters with that of the Difference of Gaussian (DOG) approach. The obtained descriptor shows a good discriminative power when dealing with the variations in illumination, scale, rotation, blur, viewpoint and compression. The experiments on image matching, demonstrates the advantage of the obtained descriptor when compared to its first order counterparts such as SIFT, DAISY, GLOH, GIST and LIDRIC.
Survey of 3D Human Body Pose and Shape Estimation Methods for Contemporary Dance Applications
Jan 04, 20243D human body shape and pose estimation from RGB images is a challenging problem with potential applications in augmented/virtual reality, healthcare and fitness technology and virtual retail. Recent solutions have focused on three types of inputs: i) single images, ii) multi-view images and iii) videos. In this study, we surveyed and compared 3D body shape and pose estimation methods for contemporary dance and performing arts, with a special focus on human body pose and dressing, camera viewpoint, illumination conditions and background conditions. We demonstrated that multi-frame methods, such as PHALP, provide better results than single-frame method for pose estimation when dancers are performing contemporary dances.
Unidentified Floating Object detection in maritime environment using dictionary learning
Jul 30, 2020

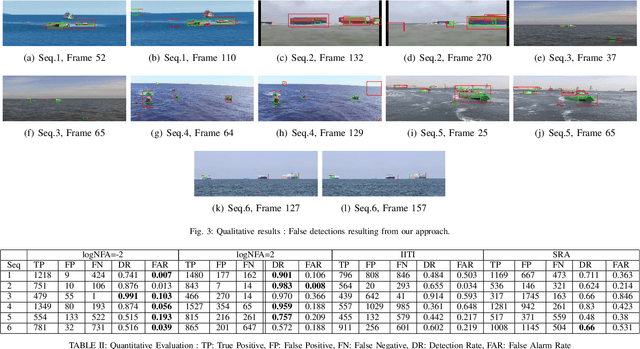

Maritime domain is one of the most challenging scenarios for object detection due to the complexity of the observed scene. In this article, we present a new approach to detect unidentified floating objects in the maritime environment. The proposed approach is capable of detecting floating objects without any prior knowledge of their visual appearance, shape or location. The input image from the video stream is denoised using a visual dictionary learned from a K-SVD algorithm. The denoised image is made of self-similar content. Later, we extract the residual image, which is the difference between the original image and the denoised (self-similar) image. Thus, the residual image contains noise and salient structures (objects). These salient structures can be extracted using an a contrario model. We demonstrate the capabilities of our algorithm by testing it on videos exhibiting varying maritime scenarios.