 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Generative Models for Anomaly Detection in Neuroimaging: A Systematic Scoping Review
Oct 16, 2025Unsupervised deep generative models are emerging as a promising alternative to supervised methods for detecting and segmenting anomalies in brain imaging. Unlike fully supervised approaches, which require large voxel-level annotated datasets and are limited to well-characterised pathologies, these models can be trained exclusively on healthy data and identify anomalies as deviations from learned normative brain structures. This PRISMA-guided scoping review synthesises recent work on unsupervised deep generative models for anomaly detection in neuroimaging, including autoencoders, variational autoencoders, generative adversarial networks, and denoising diffusion models. A total of 49 studies published between 2018 - 2025 were identified, covering applications to brain MRI and, less frequently, CT across diverse pathologies such as tumours, stroke, multiple sclerosis, and small vessel disease. Reported performance metrics are compared alongside architectural design choices. Across the included studies, generative models achieved encouraging performance for large focal lesions and demonstrated progress in addressing more subtle abnormalities. A key strength of generative models is their ability to produce interpretable pseudo-healthy (also referred to as counterfactual) reconstructions, which is particularly valuable when annotated data are scarce, as in rare or heterogeneous diseases. Looking ahead, these models offer a compelling direction for anomaly detection, enabling semi-supervised learning, supporting the discovery of novel imaging biomarkers, and facilitating within- and cross-disease deviation mapping in unified end-to-end frameworks. To realise clinical impact, future work should prioritise anatomy-aware modelling, development of foundation models, task-appropriate evaluation metrics, and rigorous clinical validation.
How Foundational are Foundation Models for Time Series Forecasting?
Oct 02, 2025
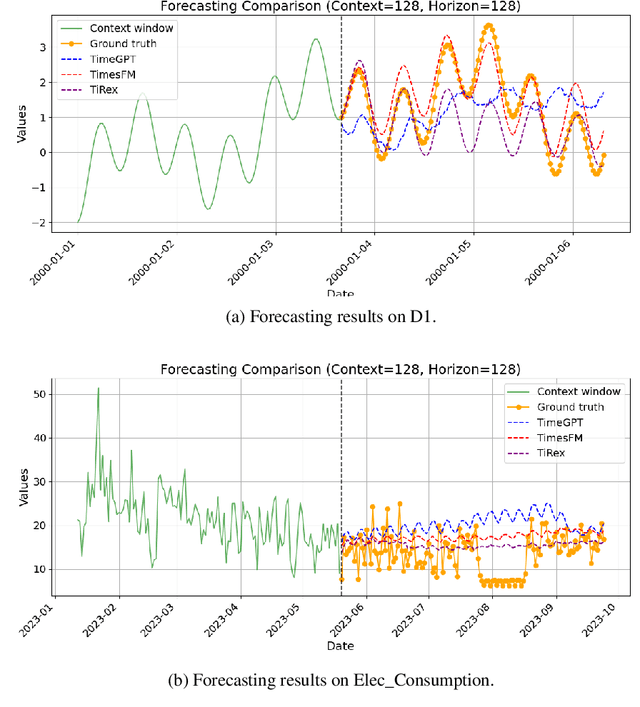

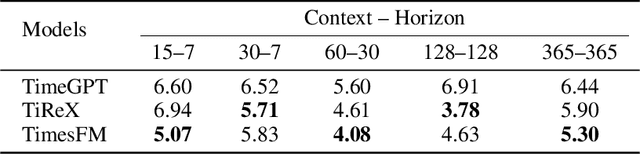
Foundation Models are designed to serve as versatile embedding machines, with strong zero shot capabilities and superior generalization performance when fine-tuned on diverse downstream tasks. While this is largely true for language and vision foundation models, we argue that the inherent diversity of time series data makes them less suited for building effective foundation models. We demonstrate this using forecasting as our downstream task. We show that the zero-shot capabilities of a time series foundation model are significantly influenced and tied to the specific domains it has been pretrained on. Furthermore, when applied to unseen real-world time series data, fine-tuned foundation models do not consistently yield substantially better results, relative to their increased parameter count and memory footprint, than smaller, dedicated models tailored to the specific forecasting task at hand.
Are Time Series Foundation Models Susceptible to Catastrophic Forgetting?
Oct 02, 2025



Time Series Foundation Models (TSFMs) have shown promising zero-shot generalization across diverse forecasting tasks. However, their robustness to continual adaptation remains underexplored. In this work, we investigate the extent to which TSFMs suffer from catastrophic forgetting when fine-tuned sequentially on multiple datasets. Using synthetic datasets designed with varying degrees of periodic structure, we measure the trade-off between adaptation to new data and retention of prior knowledge. Our experiments reveal that, while fine-tuning improves performance on new tasks, it often causes significant degradation on previously learned ones, illustrating a fundamental stability-plasticity dilemma.
Datum-wise Transformer for Synthetic Tabular Data Detection in the Wild
Apr 10, 2025The growing power of generative models raises major concerns about the authenticity of published content. To address this problem, several synthetic content detection methods have been proposed for uniformly structured media such as image or text. However, little work has been done on the detection of synthetic tabular data, despite its importance in industry and government. This form of data is complex to handle due to the diversity of its structures: the number and types of the columns may vary wildly from one table to another. We tackle the tough problem of detecting synthetic tabular data ''in the wild'', i.e. when the model is deployed on table structures it has never seen before. We introduce a novel datum-wise transformer architecture and show that it outperforms existing models. Furthermore, we investigate the application of domain adaptation techniques to enhance the effectiveness of our model, thereby providing a more robust data-forgery detection solution.
Synthetic Tabular Data Detection In the Wild
Mar 03, 2025
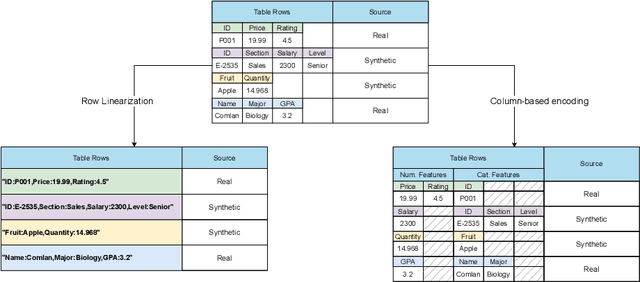
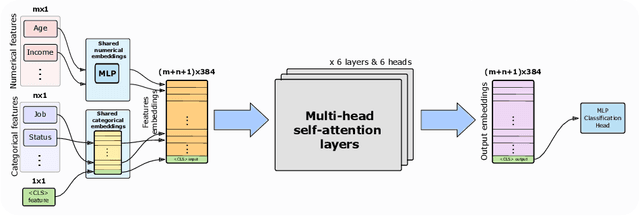
Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified across different tables. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose four table-agnostic detectors combined with simple preprocessing schemes that we evaluate on six evaluation protocols, with different levels of ''wildness''. Our results show that cross-table learning on a restricted set of tables is possible even with naive preprocessing schemes. They confirm however that cross-table transfer (i.e. deployment on a table that has not been seen before) is challenging. This suggests that sophisticated encoding schemes are required to handle this problem.
Supervised contrastive learning for cell stage classification of animal embryos
Feb 11, 2025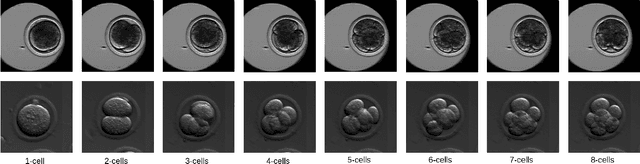
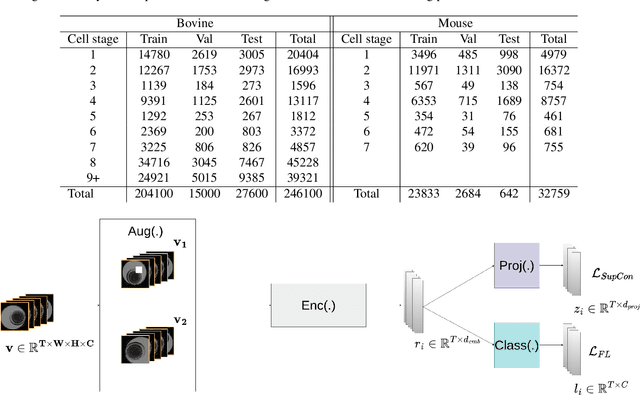
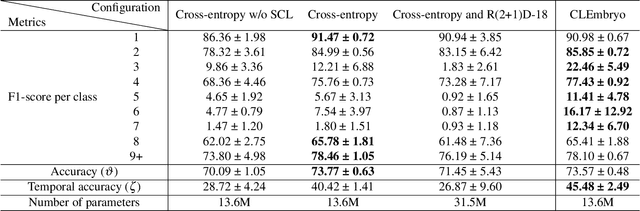

Video microscopy, when combined with machine learning, offers a promising approach for studying the early development of in vitro produced (IVP) embryos. However, manually annotating developmental events, and more specifically cell divisions, is time-consuming for a biologist and cannot scale up for practical applications. We aim to automatically classify the cell stages of embryos from 2D time-lapse microscopy videos with a deep learning approach. We focus on the analysis of bovine embryonic development using video microscopy, as we are primarily interested in the application of cattle breeding, and we have created a Bovine Embryos Cell Stages (ECS) dataset. The challenges are three-fold: (1) low-quality images and bovine dark cells that make the identification of cell stages difficult, (2) class ambiguity at the boundaries of developmental stages, and (3) imbalanced data distribution. To address these challenges, we introduce CLEmbryo, a novel method that leverages supervised contrastive learning combined with focal loss for training, and the lightweight 3D neural network CSN-50 as an encoder. We also show that our method generalizes well. CLEmbryo outperforms state-of-the-art methods on both our Bovine ECS dataset and the publicly available NYU Mouse Embryos dataset.
Early prediction of the transferability of bovine embryos from videomicroscopy
Jan 14, 2025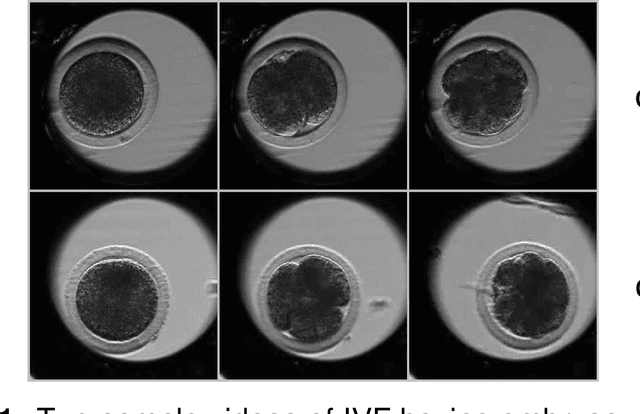

Videomicroscopy is a promising tool combined with machine learning for studying the early development of in vitro fertilized bovine embryos and assessing its transferability as soon as possible. We aim to predict the embryo transferability within four days at most, taking 2D time-lapse microscopy videos as input. We formulate this problem as a supervised binary classification problem for the classes transferable and not transferable. The challenges are three-fold: 1) poorly discriminating appearance and motion, 2) class ambiguity, 3) small amount of annotated data. We propose a 3D convolutional neural network involving three pathways, which makes it multi-scale in time and able to handle appearance and motion in different ways. For training, we retain the focal loss. Our model, named SFR, compares favorably to other methods. Experiments demonstrate its effectiveness and accuracy for our challenging biological task.
* Accepted at the 2024 IEEE International Conference on Image Processing
Cross-table Synthetic Tabular Data Detection
Dec 17, 2024



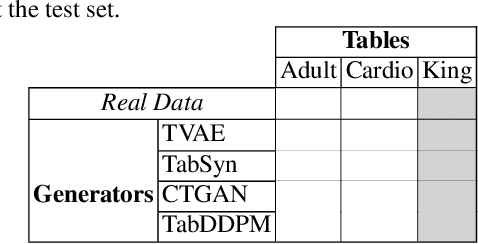
Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified ''in the wild''-meaning across different generators, domains, and table formats. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose three cross-table baseline detectors and four distinct evaluation protocols, each corresponding to a different level of ''wildness''. Our very preliminary results confirm that cross-table adaptation is a challenging task.
Under the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning
Jun 18, 2024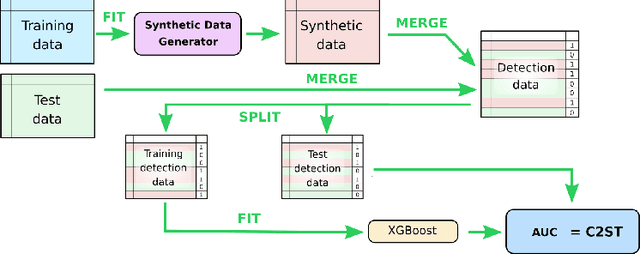
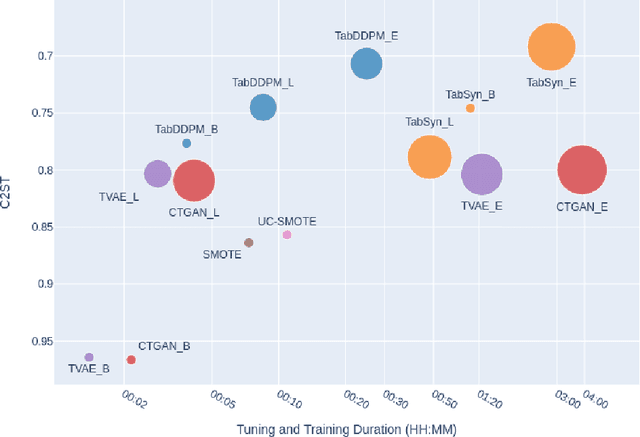
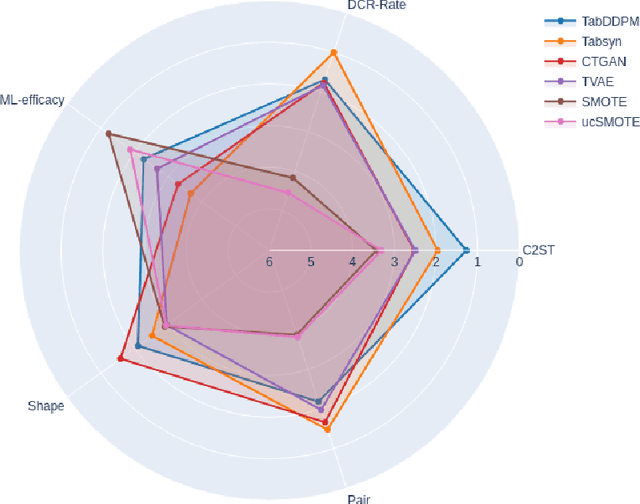
We investigate the impact of dataset-specific hyperparameter, feature encoding, and architecture tuning on five recent model families for tabular data generation through an extensive benchmark on 16 datasets. This study addresses the practical need for a unified evaluation of models that fully considers hyperparameter optimization. Additionally, we propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower cost.Our benchmark demonstrates that, for most models, large-scale dataset-specific tuning substantially improves performance compared to the original configurations. Furthermore, we confirm that diffusion-based models generally outperform other models on tabular data. However, this advantage is not significant when the entire tuning and training process is restricted to the same GPU budget for all models.
Mitigating analytical variability in fMRI results with style transfer
Apr 04, 2024We propose a novel approach to improve the reproducibility of neuroimaging results by converting statistic maps across different functional MRI pipelines. We make the assumption that pipelines can be considered as a style component of data and propose to use different generative models, among which, Diffusion Models (DM) to convert data between pipelines. We design a new DM-based unsupervised multi-domain image-to-image transition framework and constrain the generation of 3D fMRI statistic maps using the latent space of an auxiliary classifier that distinguishes statistic maps from different pipelines. We extend traditional sampling techniques used in DM to improve the transition performance. Our experiments demonstrate that our proposed methods are successful: pipelines can indeed be transferred, providing an important source of data augmentation for future medical studies.