 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatum-wise Transformer for Synthetic Tabular Data Detection in the Wild
Apr 10, 2025The growing power of generative models raises major concerns about the authenticity of published content. To address this problem, several synthetic content detection methods have been proposed for uniformly structured media such as image or text. However, little work has been done on the detection of synthetic tabular data, despite its importance in industry and government. This form of data is complex to handle due to the diversity of its structures: the number and types of the columns may vary wildly from one table to another. We tackle the tough problem of detecting synthetic tabular data ''in the wild'', i.e. when the model is deployed on table structures it has never seen before. We introduce a novel datum-wise transformer architecture and show that it outperforms existing models. Furthermore, we investigate the application of domain adaptation techniques to enhance the effectiveness of our model, thereby providing a more robust data-forgery detection solution.
Synthetic Tabular Data Detection In the Wild
Mar 03, 2025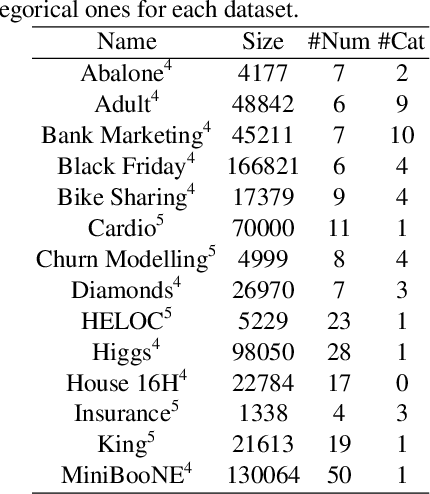
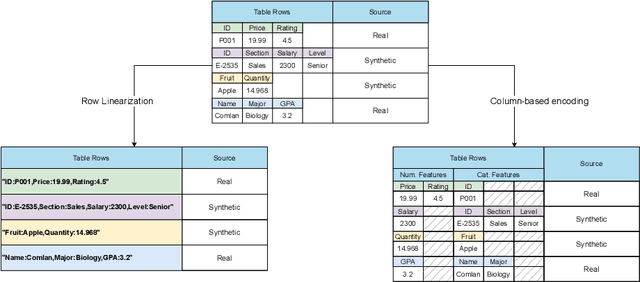
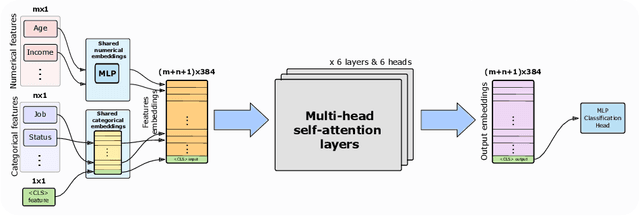
Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified across different tables. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose four table-agnostic detectors combined with simple preprocessing schemes that we evaluate on six evaluation protocols, with different levels of ''wildness''. Our results show that cross-table learning on a restricted set of tables is possible even with naive preprocessing schemes. They confirm however that cross-table transfer (i.e. deployment on a table that has not been seen before) is challenging. This suggests that sophisticated encoding schemes are required to handle this problem.
Cross-table Synthetic Tabular Data Detection
Dec 17, 2024



Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified ''in the wild''-meaning across different generators, domains, and table formats. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose three cross-table baseline detectors and four distinct evaluation protocols, each corresponding to a different level of ''wildness''. Our very preliminary results confirm that cross-table adaptation is a challenging task.
Under the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning
Jun 18, 2024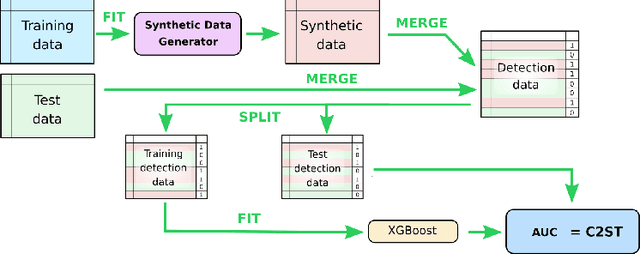
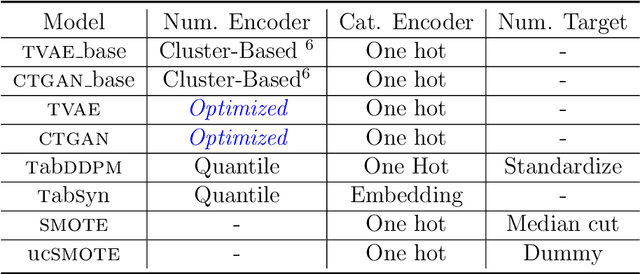
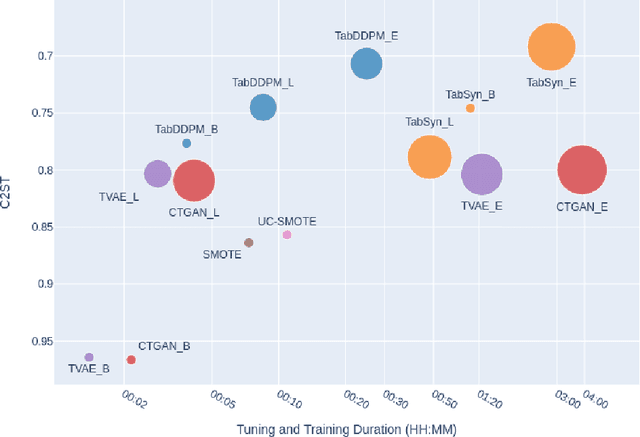
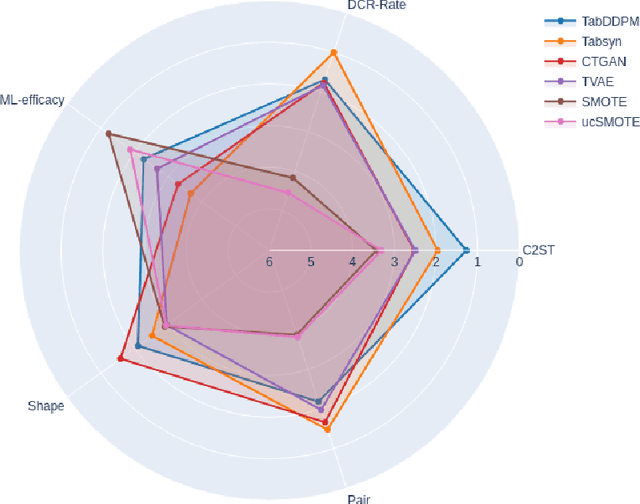
We investigate the impact of dataset-specific hyperparameter, feature encoding, and architecture tuning on five recent model families for tabular data generation through an extensive benchmark on 16 datasets. This study addresses the practical need for a unified evaluation of models that fully considers hyperparameter optimization. Additionally, we propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower cost.Our benchmark demonstrates that, for most models, large-scale dataset-specific tuning substantially improves performance compared to the original configurations. Furthermore, we confirm that diffusion-based models generally outperform other models on tabular data. However, this advantage is not significant when the entire tuning and training process is restricted to the same GPU budget for all models.
Are cascade dialogue state tracking models speaking out of turn in spoken dialogues?
Nov 03, 2023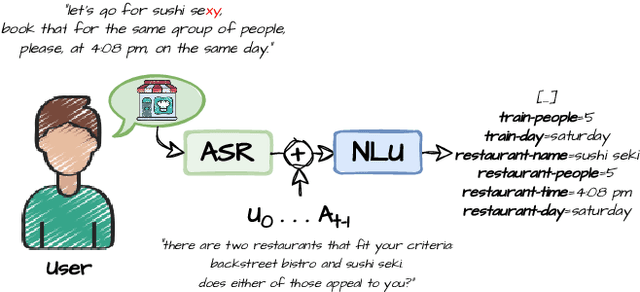

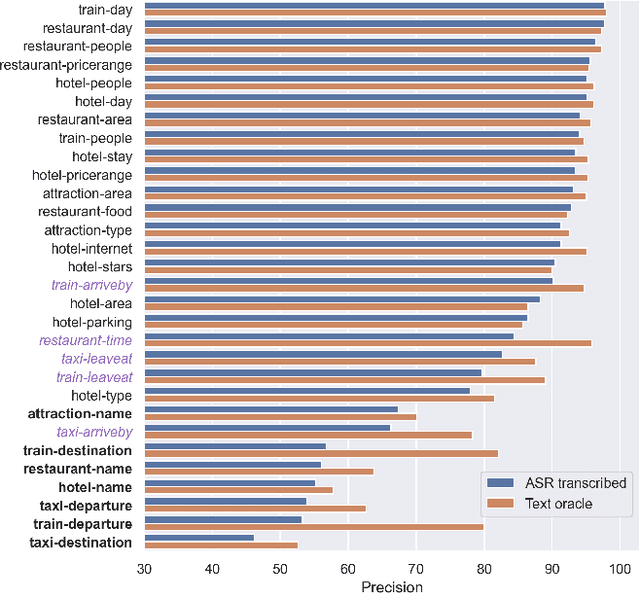
In Task-Oriented Dialogue (TOD) systems, correctly updating the system's understanding of the user's needs is key to a smooth interaction. Traditionally TOD systems are composed of several modules that interact with one another. While each of these components is the focus of active research communities, their behavior in interaction can be overlooked. This paper proposes a comprehensive analysis of the errors of state of the art systems in complex settings such as Dialogue State Tracking which highly depends on the dialogue context. Based on spoken MultiWoz, we identify that errors on non-categorical slots' values are essential to address in order to bridge the gap between spoken and chat-based dialogue systems. We explore potential solutions to improve transcriptions and help dialogue state tracking generative models correct such errors.
OLISIA: a Cascade System for Spoken Dialogue State Tracking
Apr 20, 2023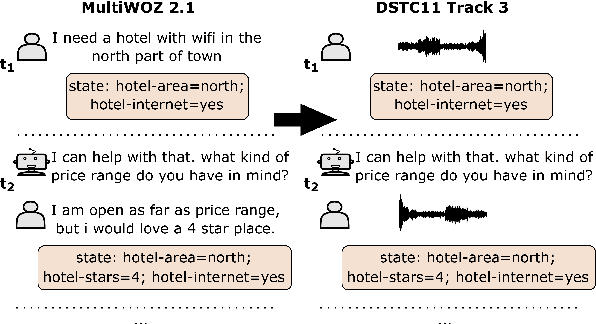
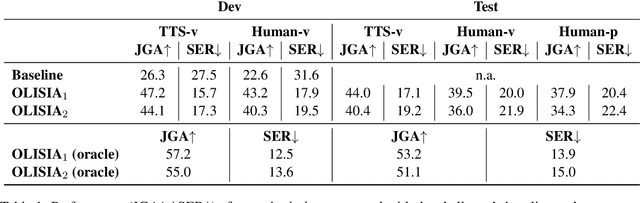

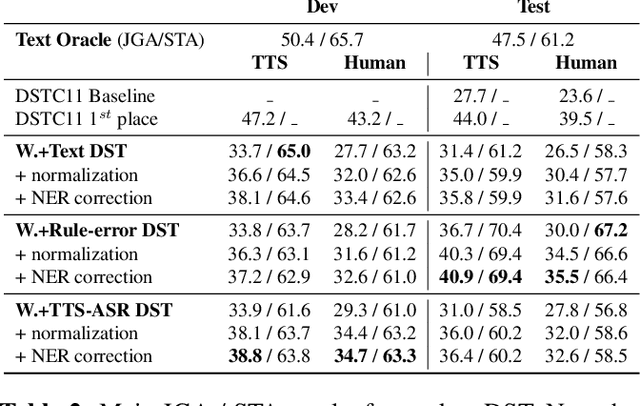
Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.
Active Learning and Multi-label Classification for Ellipsis and Coreference Detection in Conversational Question-Answering
Jul 07, 2022In human conversations, ellipsis and coreference are commonly occurring linguistic phenomena. Although these phenomena are a mean of making human-machine conversations more fluent and natural, only few dialogue corpora contain explicit indications on which turns contain ellipses and/or coreferences. In this paper we address the task of automatically detecting ellipsis and coreferences in conversational question answering. We propose to use a multi-label classifier based on DistilBERT. Multi-label classification and active learning are employed to compensate the limited amount of labeled data. We show that these methods greatly enhance the performance of the classifier for detecting these phenomena on a manually labeled dataset.