 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo we really need Self-Attention for Streaming Automatic Speech Recognition?
Jan 27, 2026Transformer-based architectures are the most used architectures in many deep learning fields like Natural Language Processing, Computer Vision or Speech processing. It may encourage the direct use of Transformers in the constrained tasks, without questioning whether it will yield the same benefits as in standard tasks. Given specific constraints, it is essential to evaluate the relevance of transformer models. This work questions the suitability of transformers for specific domains. We argue that the high computational requirements and latency issues associated with these models do not align well with streaming applications. Our study promotes the search for alternative strategies to improve efficiency without sacrificing performance. In light of this observation, our paper critically examines the usefulness of transformer architecture in such constrained environments. As a first attempt, we show that the computational cost for Streaming Automatic Speech Recognition (ASR) can be reduced using deformable convolution instead of Self-Attention. Furthermore, we show that Self-Attention mechanisms can be entirely removed and not replaced, without observing significant degradation in the Word Error Rate.
The Speech-LLM Takes It All: A Truly Fully End-to-End Spoken Dialogue State Tracking Approach
Oct 10, 2025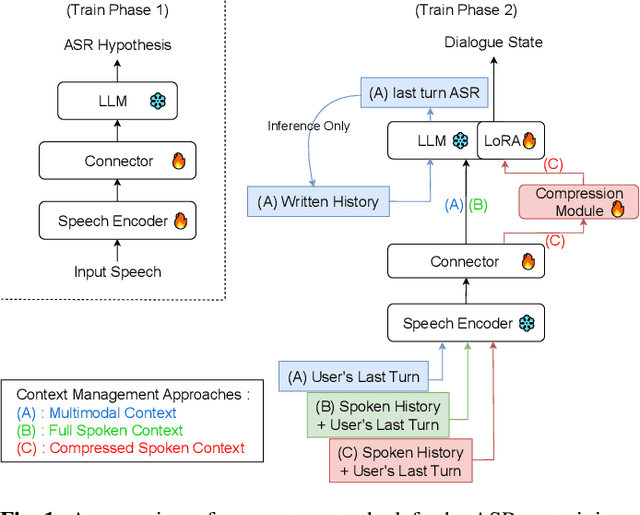

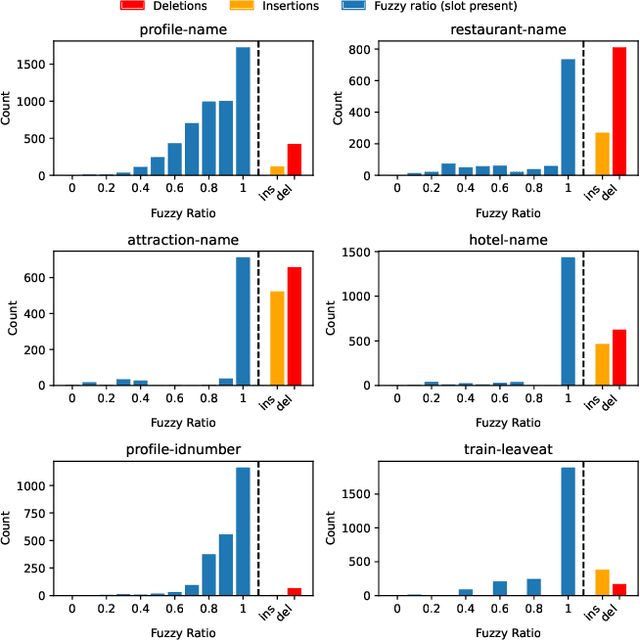
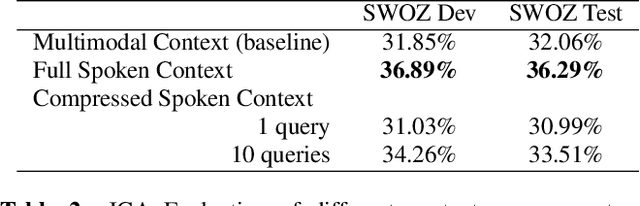
This paper presents a comparative study of context management strategies for end-to-end Spoken Dialog State Tracking using Speech-LLMs. We systematically evaluate traditional multimodal context (combining text history and spoken current turn), full spoken history, and compressed spoken history approaches. Our experiments on the SpokenWOZ corpus demonstrate that providing the full spoken conversation as input yields the highest performance among models of similar size, significantly surpassing prior methods. Furthermore, we show that attention-pooling-based compression of the spoken history offers a strong trade-off, maintaining competitive accuracy with reduced context size. Detailed analysis confirms that improvements stem from more effective context utilization.
Investigating Low-Cost LLM Annotation for~Spoken Dialogue Understanding Datasets
Jun 19, 2024In spoken Task-Oriented Dialogue (TOD) systems, the choice of the semantic representation describing the users' requests is key to a smooth interaction. Indeed, the system uses this representation to reason over a database and its domain knowledge to choose its next action. The dialogue course thus depends on the information provided by this semantic representation. While textual datasets provide fine-grained semantic representations, spoken dialogue datasets fall behind. This paper provides insights into automatic enhancement of spoken dialogue datasets' semantic representations. Our contributions are three fold: (1) assess the relevance of Large Language Model fine-tuning, (2) evaluate the knowledge captured by the produced annotations and (3) highlight semi-automatic annotation implications.
Sustainable self-supervised learning for speech representations
Jun 11, 2024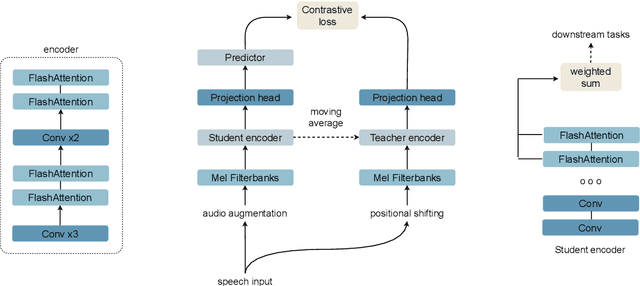
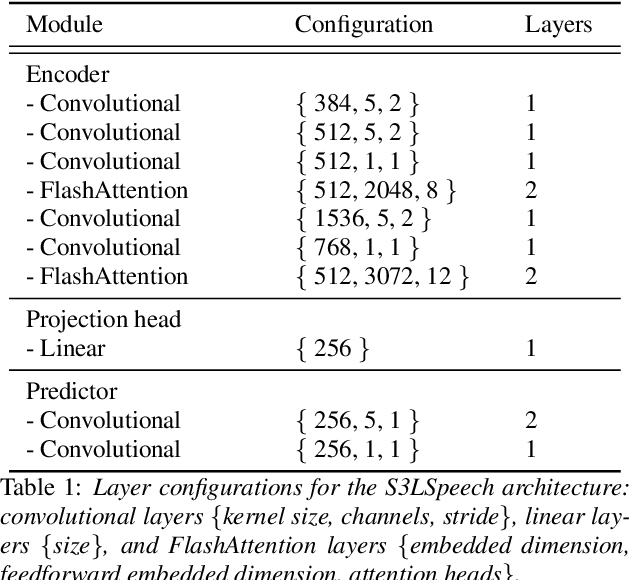
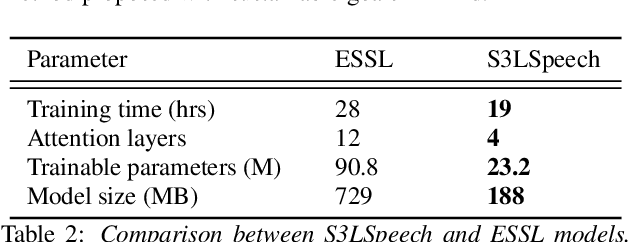
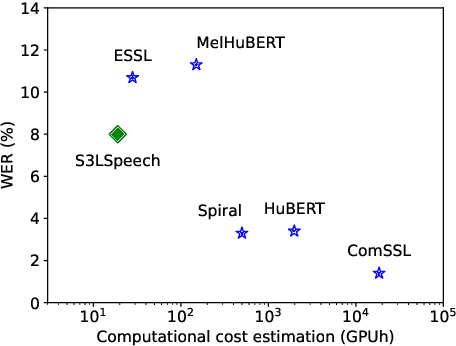
Sustainable artificial intelligence focuses on data, hardware, and algorithms to make machine learning models more environmentally responsible. In particular, machine learning models for speech representations are computationally expensive, generating environmental concerns because of their high energy consumption. Thus, we propose a sustainable self-supervised model to learn speech representation, combining optimizations in neural layers and training to reduce computing costs. The proposed model improves over a resource-efficient baseline, reducing both memory usage and computing cost estimations. It pretrains using a single GPU in less than a day. On top of that, it improves the error rate performance of the baseline in downstream task evaluations. When comparing it to large speech representation approaches, there is an order of magnitude reduction in memory usage, while computing cost reductions represent almost three orders of magnitude improvement.
Investigating the 'Autoencoder Behavior' in Speech Self-Supervised Models: a focus on HuBERT's Pretraining
May 14, 2024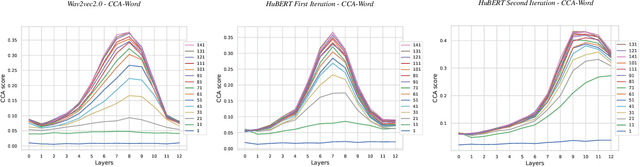
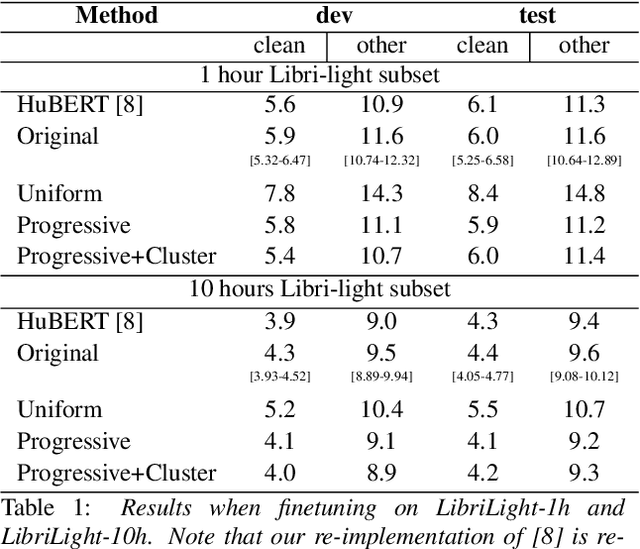
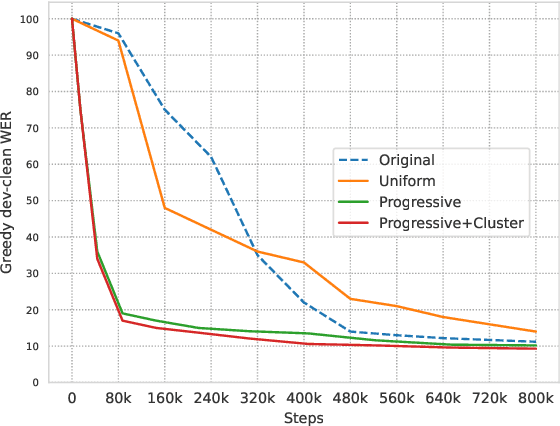
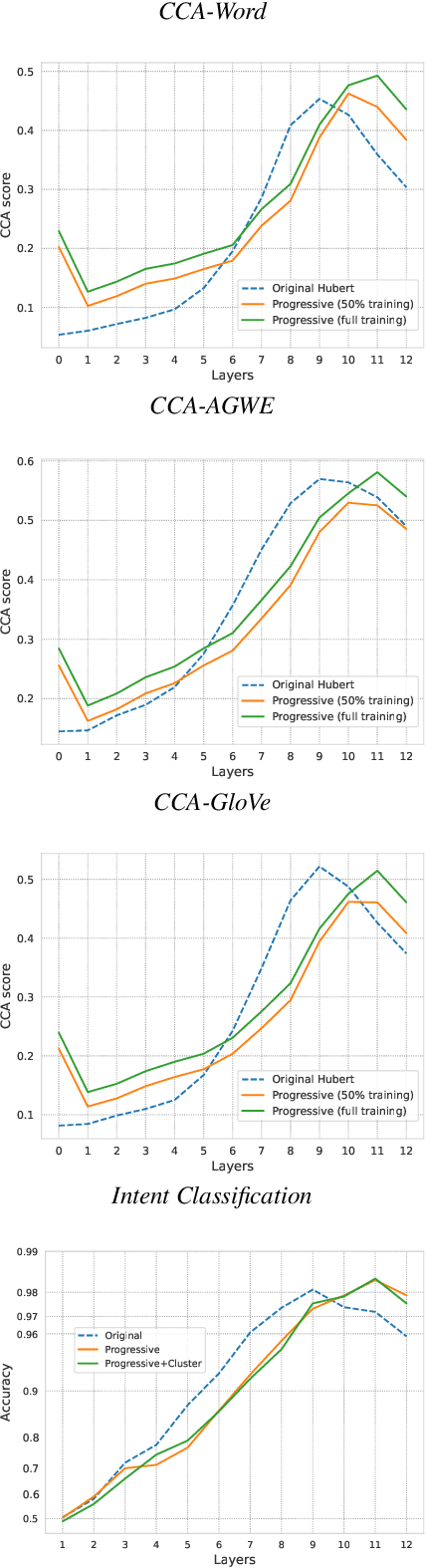
Self-supervised learning has shown great success in Speech Recognition. However, it has been observed that finetuning all layers of the learned model leads to lower performance compared to resetting top layers. This phenomenon is attributed to the ''autoencoder'' behavior: top layers contain information closer to the input and are less suitable for tasks that require linguistic information, such as Speech Recognition.To better our understanding of this behavior, we propose to study the evolution of high-level information within the model during pretraining. We focus on the HuBERT model, which exhibits a less pronounced ''autoencoder'' behavior. By experimentally exploring various factors that may have an impact, we aim to improve the training procedure and enhance the top layers of HuBERT for high-level tasks.Furthermore, our experiments demonstrate that these improvements in the training procedure result in faster convergence and competitive performance on downstream tasks.
Efficiency-oriented approaches for self-supervised speech representation learning
Dec 18, 2023



Self-supervised learning enables the training of large neural models without the need for large, labeled datasets. It has been generating breakthroughs in several fields, including computer vision, natural language processing, biology, and speech. In particular, the state-of-the-art in several speech processing applications, such as automatic speech recognition or speaker identification, are models where the latent representation is learned using self-supervised approaches. Several configurations exist in self-supervised learning for speech, including contrastive, predictive, and multilingual approaches. There is, however, a crucial limitation in most existing approaches: their high computational costs. These costs limit the deployment of models, the size of the training dataset, and the number of research groups that can afford research with large self-supervised models. Likewise, we should consider the environmental costs that high energy consumption implies. Efforts in this direction comprise optimization of existing models, neural architecture efficiency, improvements in finetuning for speech processing tasks, and data efficiency. But despite current efforts, more work could be done to address high computational costs in self-supervised representation learning.
Are cascade dialogue state tracking models speaking out of turn in spoken dialogues?
Nov 03, 2023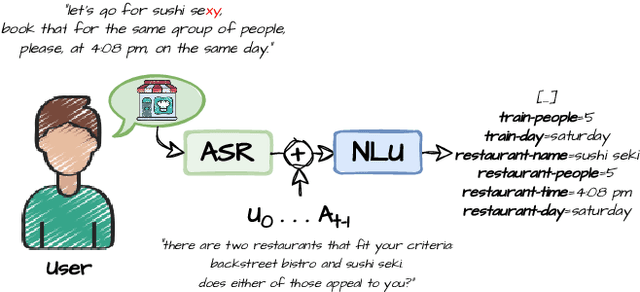

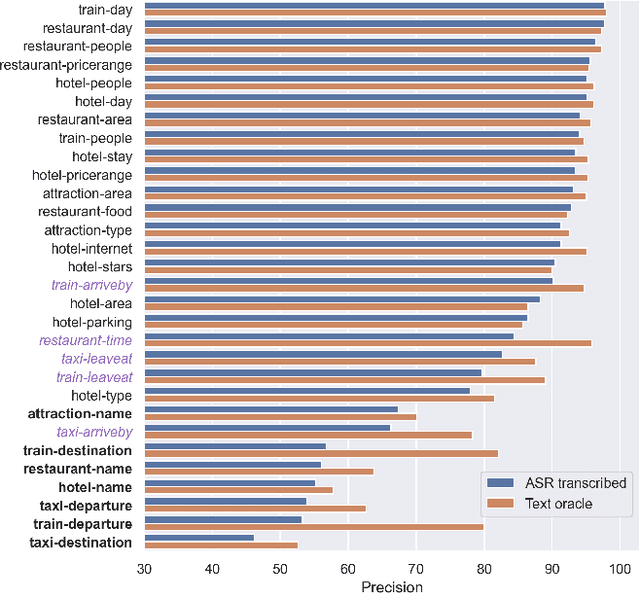
In Task-Oriented Dialogue (TOD) systems, correctly updating the system's understanding of the user's needs is key to a smooth interaction. Traditionally TOD systems are composed of several modules that interact with one another. While each of these components is the focus of active research communities, their behavior in interaction can be overlooked. This paper proposes a comprehensive analysis of the errors of state of the art systems in complex settings such as Dialogue State Tracking which highly depends on the dialogue context. Based on spoken MultiWoz, we identify that errors on non-categorical slots' values are essential to address in order to bridge the gap between spoken and chat-based dialogue systems. We explore potential solutions to improve transcriptions and help dialogue state tracking generative models correct such errors.
Is one brick enough to break the wall of spoken dialogue state tracking?
Nov 03, 2023



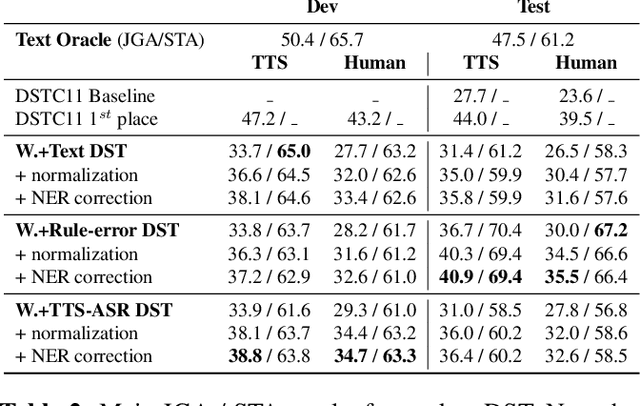
In Task-Oriented Dialogue (TOD) systems, correctly updating the system's understanding of the user's needs (a.k.a dialogue state tracking) is key to a smooth interaction. Traditionally, TOD systems perform this update in three steps: transcription of the user's utterance, semantic extraction of the key concepts, and contextualization with the previously identified concepts. Such cascade approaches suffer from cascading errors and separate optimization. End-to-End approaches have been proved helpful up to the semantic extraction step. This paper goes one step further paving the path towards completely neural spoken dialogue state tracking by comparing three approaches: (1) a state of the art cascade approach, (2) a locally E2E approach with rule-based contextualization and (3) a completely neural approach. Our study highlights that although they all outperform the recent DSTC11 best model, especially with a filtering post-processing step, (1) remains the most accurate approach. Indeed, both (2) and (3) have trouble propagating context as dialogues unfold showing that context propagation in completely neural approaches is an open challenge.
OLISIA: a Cascade System for Spoken Dialogue State Tracking
Apr 20, 2023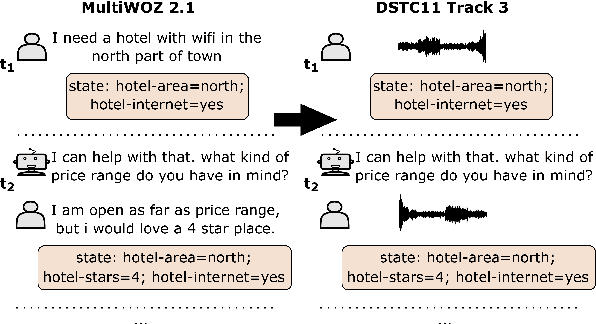
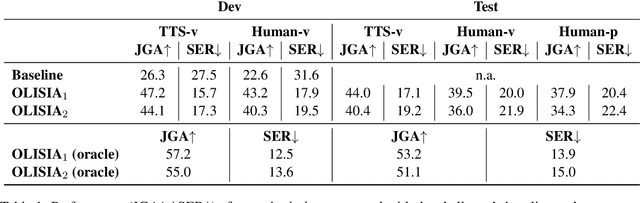

Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.
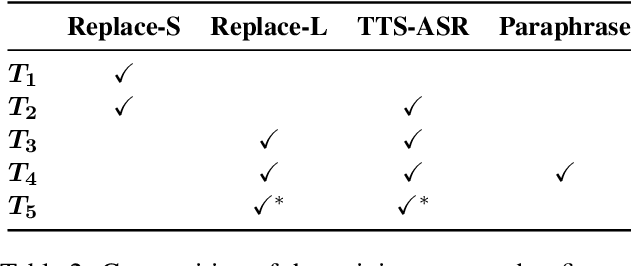
Are E2E ASR models ready for an industrial usage?
Dec 09, 2021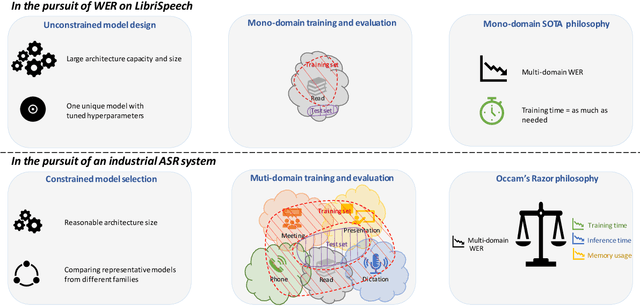
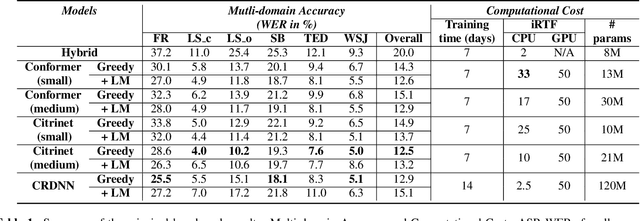
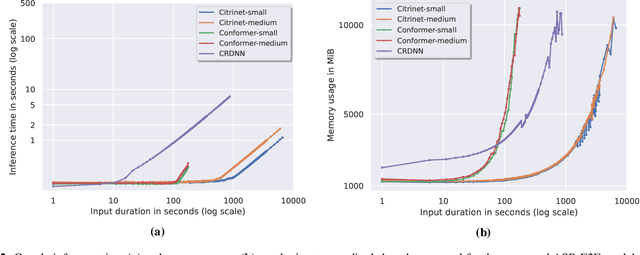
The Automated Speech Recognition (ASR) community experiences a major turning point with the rise of the fully-neural (End-to-End, E2E) approaches. At the same time, the conventional hybrid model remains the standard choice for the practical usage of ASR. According to previous studies, the adoption of E2E ASR in real-world applications was hindered by two main limitations: their ability to generalize on unseen domains and their high operational cost. In this paper, we investigate both above-mentioned drawbacks by performing a comprehensive multi-domain benchmark of several contemporary E2E models and a hybrid baseline. Our experiments demonstrate that E2E models are viable alternatives for the hybrid approach, and even outperform the baseline both in accuracy and in operational efficiency. As a result, our study shows that the generalization and complexity issues are no longer the major obstacle for industrial integration, and draws the community's attention to other potential limitations of the E2E approaches in some specific use-cases.