 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Low-Cost LLM Annotation for~Spoken Dialogue Understanding Datasets
Jun 19, 2024In spoken Task-Oriented Dialogue (TOD) systems, the choice of the semantic representation describing the users' requests is key to a smooth interaction. Indeed, the system uses this representation to reason over a database and its domain knowledge to choose its next action. The dialogue course thus depends on the information provided by this semantic representation. While textual datasets provide fine-grained semantic representations, spoken dialogue datasets fall behind. This paper provides insights into automatic enhancement of spoken dialogue datasets' semantic representations. Our contributions are three fold: (1) assess the relevance of Large Language Model fine-tuning, (2) evaluate the knowledge captured by the produced annotations and (3) highlight semi-automatic annotation implications.
Are cascade dialogue state tracking models speaking out of turn in spoken dialogues?
Nov 03, 2023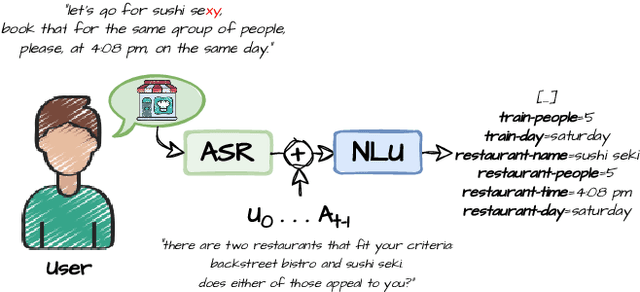

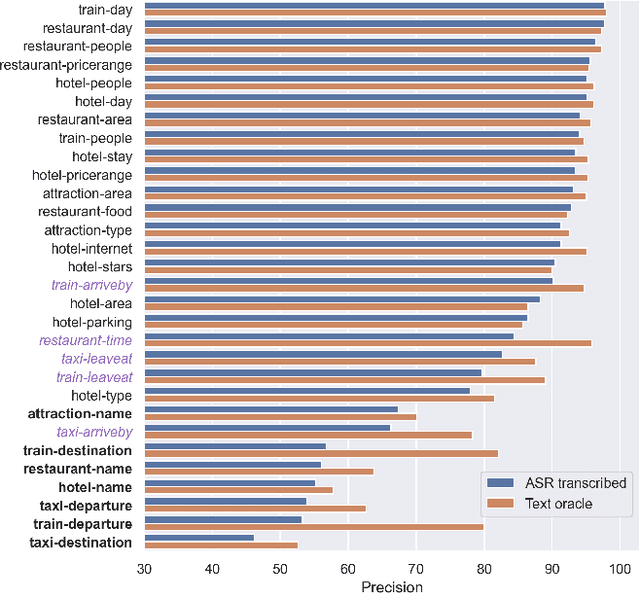
In Task-Oriented Dialogue (TOD) systems, correctly updating the system's understanding of the user's needs is key to a smooth interaction. Traditionally TOD systems are composed of several modules that interact with one another. While each of these components is the focus of active research communities, their behavior in interaction can be overlooked. This paper proposes a comprehensive analysis of the errors of state of the art systems in complex settings such as Dialogue State Tracking which highly depends on the dialogue context. Based on spoken MultiWoz, we identify that errors on non-categorical slots' values are essential to address in order to bridge the gap between spoken and chat-based dialogue systems. We explore potential solutions to improve transcriptions and help dialogue state tracking generative models correct such errors.
Is one brick enough to break the wall of spoken dialogue state tracking?
Nov 03, 2023



In Task-Oriented Dialogue (TOD) systems, correctly updating the system's understanding of the user's needs (a.k.a dialogue state tracking) is key to a smooth interaction. Traditionally, TOD systems perform this update in three steps: transcription of the user's utterance, semantic extraction of the key concepts, and contextualization with the previously identified concepts. Such cascade approaches suffer from cascading errors and separate optimization. End-to-End approaches have been proved helpful up to the semantic extraction step. This paper goes one step further paving the path towards completely neural spoken dialogue state tracking by comparing three approaches: (1) a state of the art cascade approach, (2) a locally E2E approach with rule-based contextualization and (3) a completely neural approach. Our study highlights that although they all outperform the recent DSTC11 best model, especially with a filtering post-processing step, (1) remains the most accurate approach. Indeed, both (2) and (3) have trouble propagating context as dialogues unfold showing that context propagation in completely neural approaches is an open challenge.
OLISIA: a Cascade System for Spoken Dialogue State Tracking
Apr 20, 2023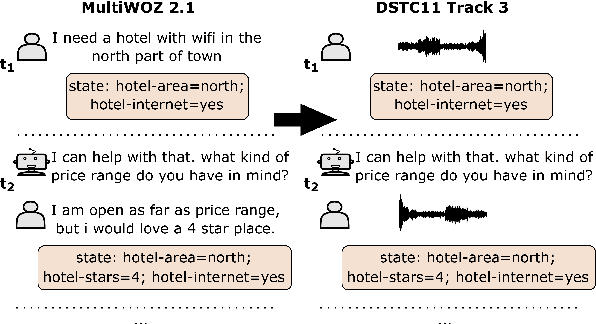
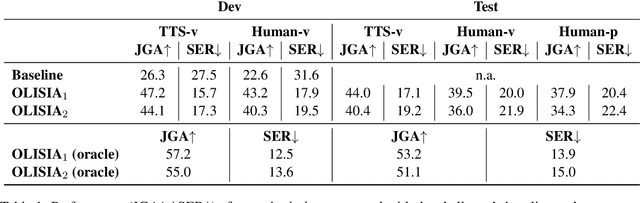

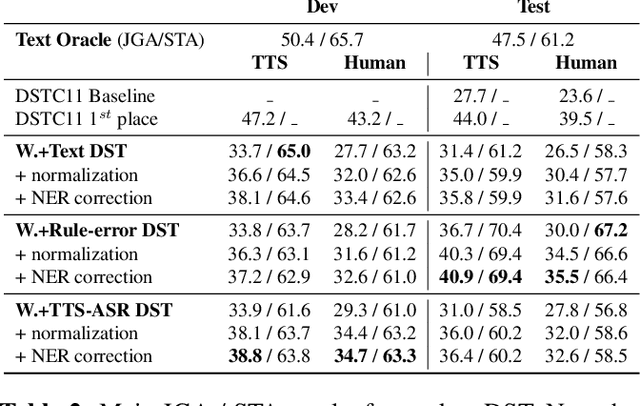
Though Dialogue State Tracking (DST) is a core component of spoken dialogue systems, recent work on this task mostly deals with chat corpora, disregarding the discrepancies between spoken and written language.In this paper, we propose OLISIA, a cascade system which integrates an Automatic Speech Recognition (ASR) model and a DST model. We introduce several adaptations in the ASR and DST modules to improve integration and robustness to spoken conversations.With these adaptations, our system ranked first in DSTC11 Track 3, a benchmark to evaluate spoken DST. We conduct an in-depth analysis of the results and find that normalizing the ASR outputs and adapting the DST inputs through data augmentation, along with increasing the pre-trained models size all play an important role in reducing the performance discrepancy between written and spoken conversations.