 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable self-supervised learning for speech representations
Jun 11, 2024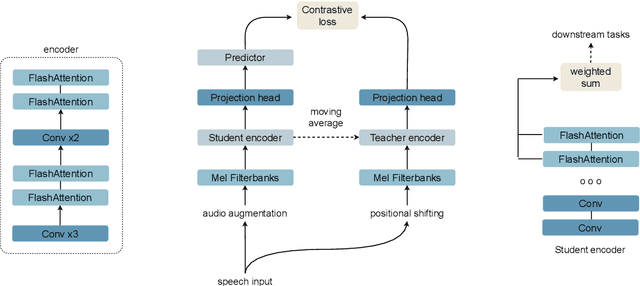
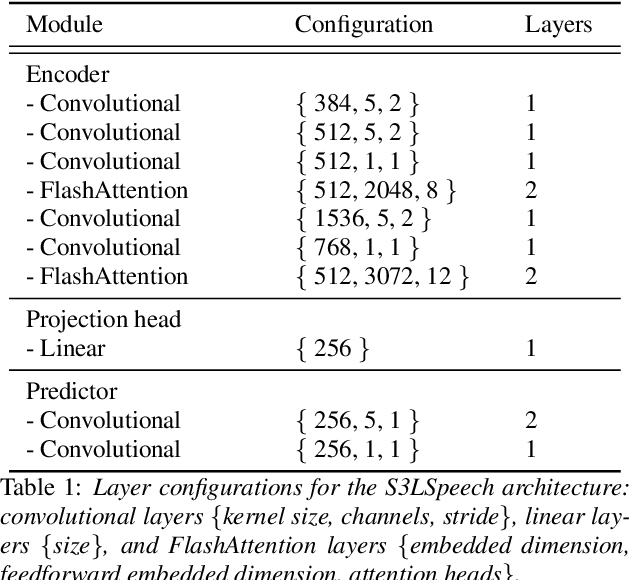
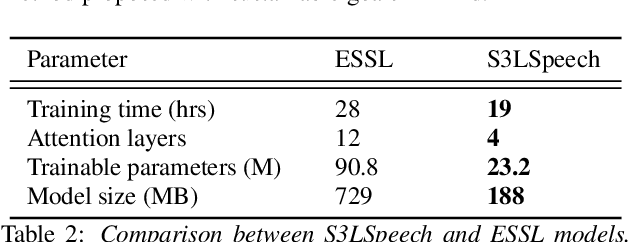
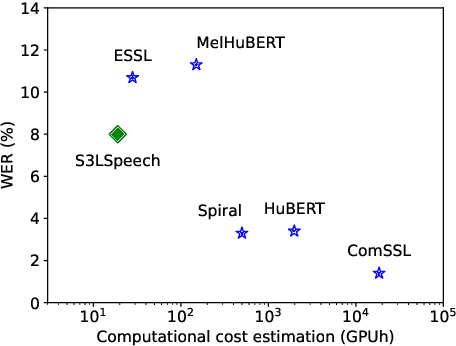
Sustainable artificial intelligence focuses on data, hardware, and algorithms to make machine learning models more environmentally responsible. In particular, machine learning models for speech representations are computationally expensive, generating environmental concerns because of their high energy consumption. Thus, we propose a sustainable self-supervised model to learn speech representation, combining optimizations in neural layers and training to reduce computing costs. The proposed model improves over a resource-efficient baseline, reducing both memory usage and computing cost estimations. It pretrains using a single GPU in less than a day. On top of that, it improves the error rate performance of the baseline in downstream task evaluations. When comparing it to large speech representation approaches, there is an order of magnitude reduction in memory usage, while computing cost reductions represent almost three orders of magnitude improvement.
Efficiency-oriented approaches for self-supervised speech representation learning
Dec 18, 2023



Self-supervised learning enables the training of large neural models without the need for large, labeled datasets. It has been generating breakthroughs in several fields, including computer vision, natural language processing, biology, and speech. In particular, the state-of-the-art in several speech processing applications, such as automatic speech recognition or speaker identification, are models where the latent representation is learned using self-supervised approaches. Several configurations exist in self-supervised learning for speech, including contrastive, predictive, and multilingual approaches. There is, however, a crucial limitation in most existing approaches: their high computational costs. These costs limit the deployment of models, the size of the training dataset, and the number of research groups that can afford research with large self-supervised models. Likewise, we should consider the environmental costs that high energy consumption implies. Efforts in this direction comprise optimization of existing models, neural architecture efficiency, improvements in finetuning for speech processing tasks, and data efficiency. But despite current efforts, more work could be done to address high computational costs in self-supervised representation learning.