 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable self-supervised learning for speech representations
Paper and Code
Jun 11, 2024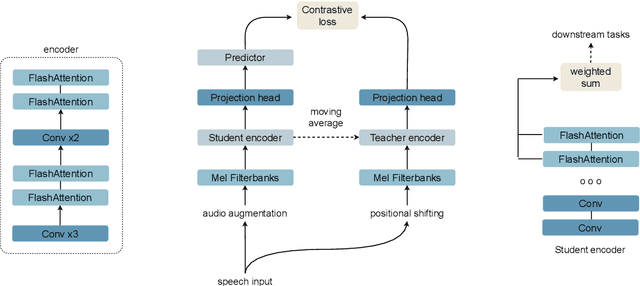
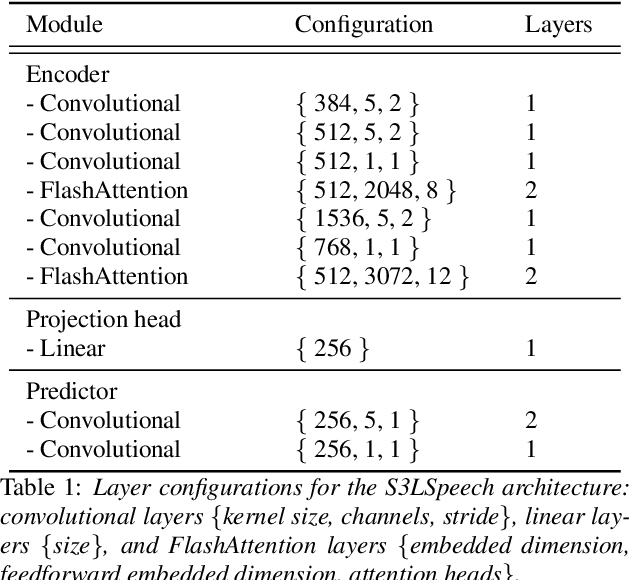
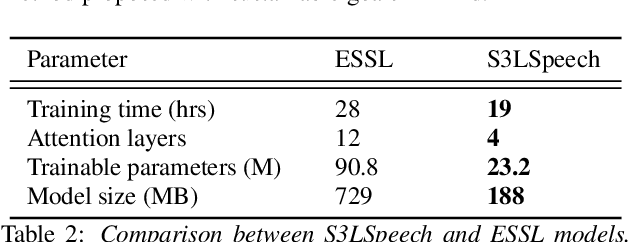
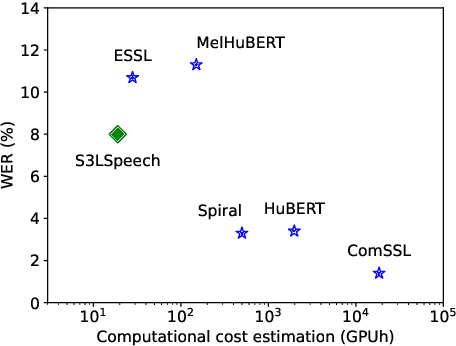
Sustainable artificial intelligence focuses on data, hardware, and algorithms to make machine learning models more environmentally responsible. In particular, machine learning models for speech representations are computationally expensive, generating environmental concerns because of their high energy consumption. Thus, we propose a sustainable self-supervised model to learn speech representation, combining optimizations in neural layers and training to reduce computing costs. The proposed model improves over a resource-efficient baseline, reducing both memory usage and computing cost estimations. It pretrains using a single GPU in less than a day. On top of that, it improves the error rate performance of the baseline in downstream task evaluations. When comparing it to large speech representation approaches, there is an order of magnitude reduction in memory usage, while computing cost reductions represent almost three orders of magnitude improvement.