 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transformer-based World Models with Contrastive Predictive Coding
Mar 06, 2025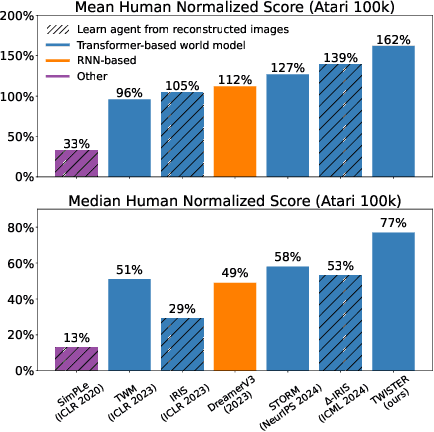

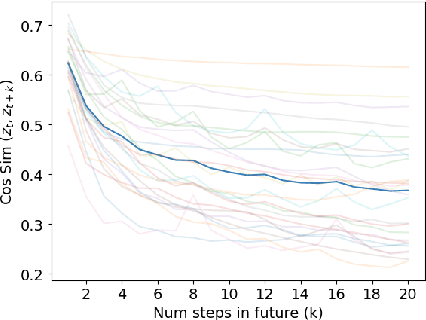
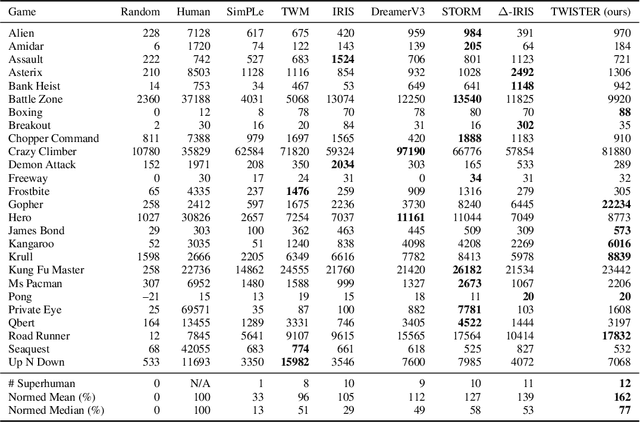
The DreamerV3 algorithm recently obtained remarkable performance across diverse environment domains by learning an accurate world model based on Recurrent Neural Networks (RNNs). Following the success of model-based reinforcement learning algorithms and the rapid adoption of the Transformer architecture for its superior training efficiency and favorable scaling properties, recent works such as STORM have proposed replacing RNN-based world models with Transformer-based world models using masked self-attention. However, despite the improved training efficiency of these methods, their impact on performance remains limited compared to the Dreamer algorithm, struggling to learn competitive Transformer-based world models. In this work, we show that the next state prediction objective adopted in previous approaches is insufficient to fully exploit the representation capabilities of Transformers. We propose to extend world model predictions to longer time horizons by introducing TWISTER (Transformer-based World model wIth contraSTivE Representations), a world model using action-conditioned Contrastive Predictive Coding to learn high-level temporal feature representations and improve the agent performance. TWISTER achieves a human-normalized mean score of 162% on the Atari 100k benchmark, setting a new record among state-of-the-art methods that do not employ look-ahead search.
MuDreamer: Learning Predictive World Models without Reconstruction
May 23, 2024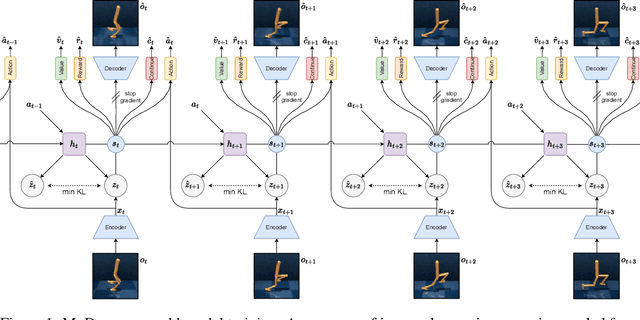
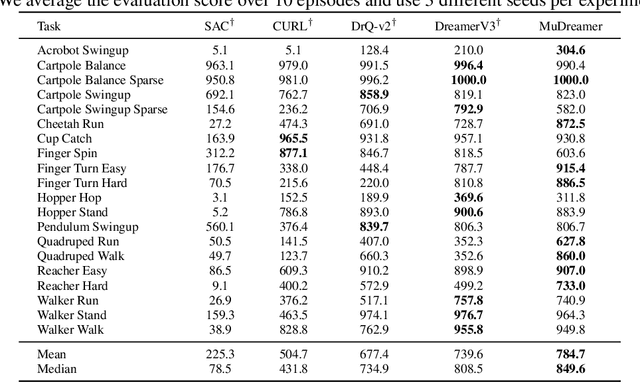

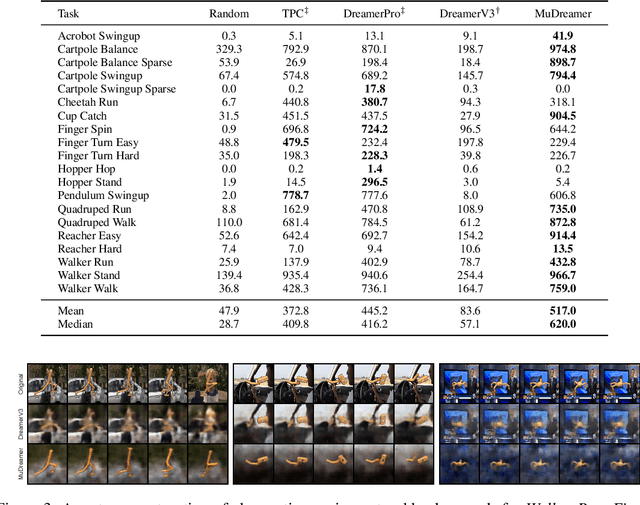
The DreamerV3 agent recently demonstrated state-of-the-art performance in diverse domains, learning powerful world models in latent space using a pixel reconstruction loss. However, while the reconstruction loss is essential to Dreamer's performance, it also necessitates modeling unnecessary information. Consequently, Dreamer sometimes fails to perceive crucial elements which are necessary for task-solving when visual distractions are present in the observation, significantly limiting its potential. In this paper, we present MuDreamer, a robust reinforcement learning agent that builds upon the DreamerV3 algorithm by learning a predictive world model without the need for reconstructing input signals. Rather than relying on pixel reconstruction, hidden representations are instead learned by predicting the environment value function and previously selected actions. Similar to predictive self-supervised methods for images, we find that the use of batch normalization is crucial to prevent learning collapse. We also study the effect of KL balancing between model posterior and prior losses on convergence speed and learning stability. We evaluate MuDreamer on the commonly used DeepMind Visual Control Suite and demonstrate stronger robustness to visual distractions compared to DreamerV3 and other reconstruction-free approaches, replacing the environment background with task-irrelevant real-world videos. Our method also achieves comparable performance on the Atari100k benchmark while benefiting from faster training.
Audio-Visual Efficient Conformer for Robust Speech Recognition
Jan 04, 2023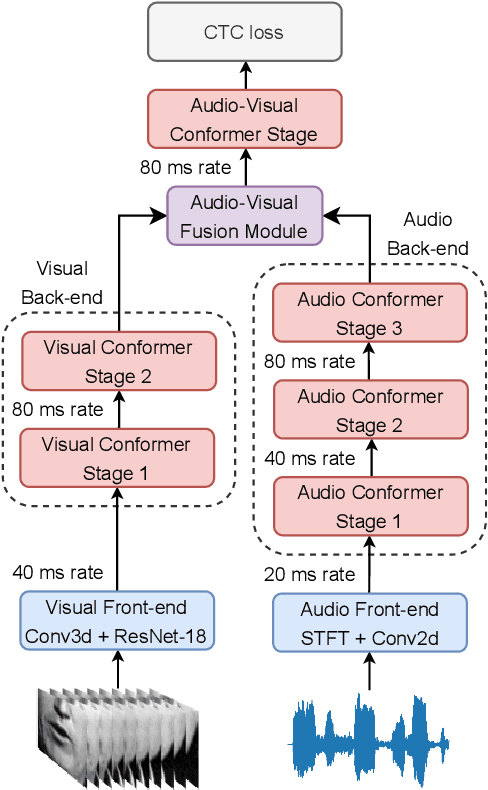
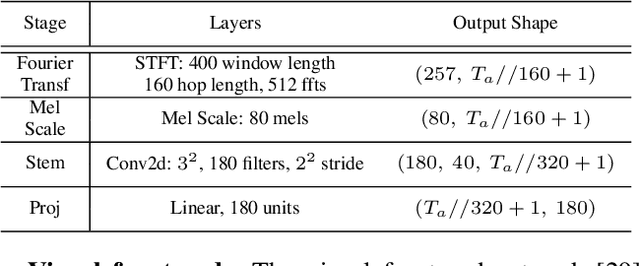
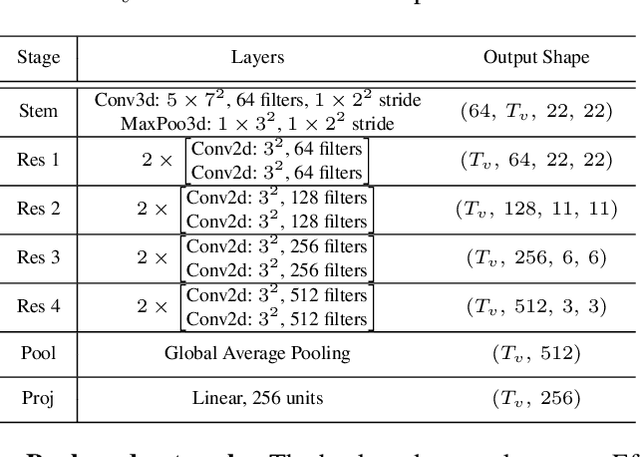

End-to-end Automatic Speech Recognition (ASR) systems based on neural networks have seen large improvements in recent years. The availability of large scale hand-labeled datasets and sufficient computing resources made it possible to train powerful deep neural networks, reaching very low Word Error Rate (WER) on academic benchmarks. However, despite impressive performance on clean audio samples, a drop of performance is often observed on noisy speech. In this work, we propose to improve the noise robustness of the recently proposed Efficient Conformer Connectionist Temporal Classification (CTC)-based architecture by processing both audio and visual modalities. We improve previous lip reading methods using an Efficient Conformer back-end on top of a ResNet-18 visual front-end and by adding intermediate CTC losses between blocks. We condition intermediate block features on early predictions using Inter CTC residual modules to relax the conditional independence assumption of CTC-based models. We also replace the Efficient Conformer grouped attention by a more efficient and simpler attention mechanism that we call patch attention. We experiment with publicly available Lip Reading Sentences 2 (LRS2) and Lip Reading Sentences 3 (LRS3) datasets. Our experiments show that using audio and visual modalities allows to better recognize speech in the presence of environmental noise and significantly accelerate training, reaching lower WER with 4 times less training steps. Our Audio-Visual Efficient Conformer (AVEC) model achieves state-of-the-art performance, reaching WER of 2.3% and 1.8% on LRS2 and LRS3 test sets. Code and pretrained models are available at https://github.com/burchim/AVEC.
Swin2SR: SwinV2 Transformer for Compressed Image Super-Resolution and Restoration
Sep 22, 2022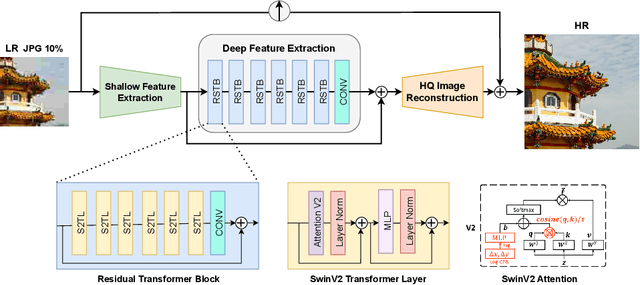
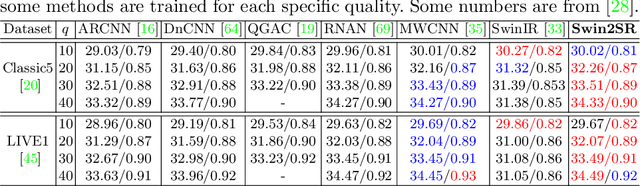
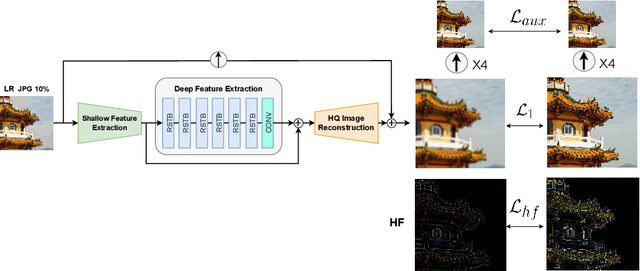

Compression plays an important role on the efficient transmission and storage of images and videos through band-limited systems such as streaming services, virtual reality or videogames. However, compression unavoidably leads to artifacts and the loss of the original information, which may severely degrade the visual quality. For these reasons, quality enhancement of compressed images has become a popular research topic. While most state-of-the-art image restoration methods are based on convolutional neural networks, other transformers-based methods such as SwinIR, show impressive performance on these tasks. In this paper, we explore the novel Swin Transformer V2, to improve SwinIR for image super-resolution, and in particular, the compressed input scenario. Using this method we can tackle the major issues in training transformer vision models, such as training instability, resolution gaps between pre-training and fine-tuning, and hunger on data. We conduct experiments on three representative tasks: JPEG compression artifacts removal, image super-resolution (classical and lightweight), and compressed image super-resolution. Experimental results demonstrate that our method, Swin2SR, can improve the training convergence and performance of SwinIR, and is a top-5 solution at the "AIM 2022 Challenge on Super-Resolution of Compressed Image and Video".
Conformer and Blind Noisy Students for Improved Image Quality Assessment
Apr 27, 2022

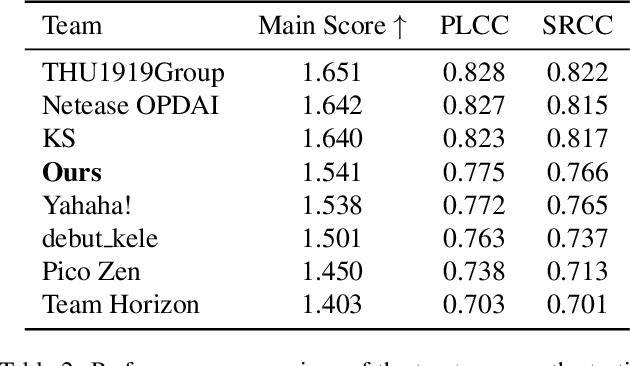
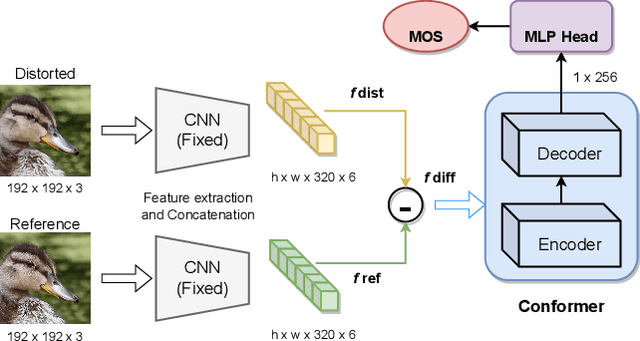
Generative models for image restoration, enhancement, and generation have significantly improved the quality of the generated images. Surprisingly, these models produce more pleasant images to the human eye than other methods, yet, they may get a lower perceptual quality score using traditional perceptual quality metrics such as PSNR or SSIM. Therefore, it is necessary to develop a quantitative metric to reflect the performance of new algorithms, which should be well-aligned with the person's mean opinion score (MOS). Learning-based approaches for perceptual image quality assessment (IQA) usually require both the distorted and reference image for measuring the perceptual quality accurately. However, commonly only the distorted or generated image is available. In this work, we explore the performance of transformer-based full-reference IQA models. We also propose a method for IQA based on semi-supervised knowledge distillation from full-reference teacher models into blind student models using noisy pseudo-labeled data. Our approaches achieved competitive results on the NTIRE 2022 Perceptual Image Quality Assessment Challenge: our full-reference model was ranked 4th, and our blind noisy student was ranked 3rd among 70 participants, each in their respective track.
Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition
Sep 08, 2021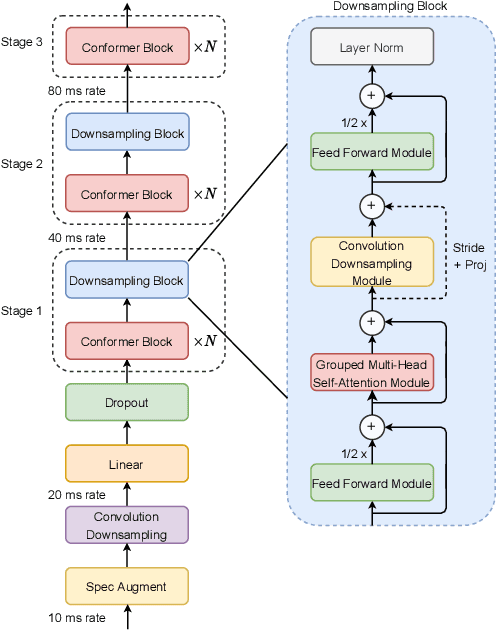
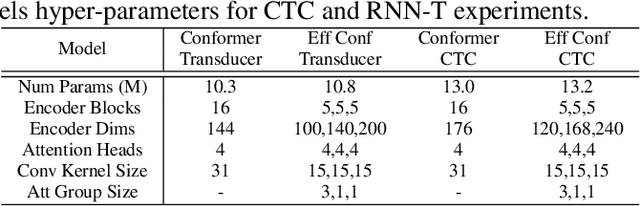

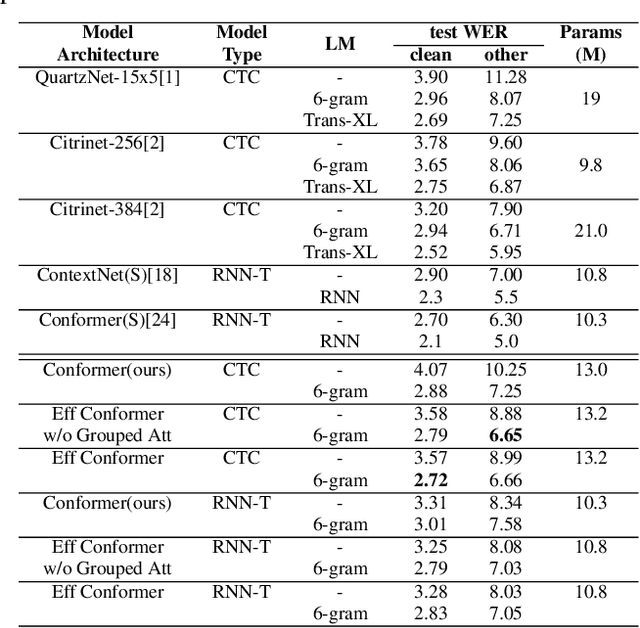
The recently proposed Conformer architecture has shown state-of-the-art performances in Automatic Speech Recognition by combining convolution with attention to model both local and global dependencies. In this paper, we study how to reduce the Conformer architecture complexity with a limited computing budget, leading to a more efficient architecture design that we call Efficient Conformer. We introduce progressive downsampling to the Conformer encoder and propose a novel attention mechanism named grouped attention, allowing us to reduce attention complexity from $O(n^{2}d)$ to $O(n^{2}d / g)$ for sequence length $n$, hidden dimension $d$ and group size parameter $g$. We also experiment the use of strided multi-head self-attention as a global downsampling operation. Our experiments are performed on the LibriSpeech dataset with CTC and RNN-Transducer losses. We show that within the same computing budget, the proposed architecture achieves better performances with faster training and decoding compared to the Conformer. Our 13M parameters CTC model achieves competitive WERs of 3.6%/9.0% without using a language model and 2.7%/6.7% with an external n-gram language model on the test-clean/test-other sets while being 29% faster than our CTC Conformer baseline at inference and 36% faster to train.