 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Omissions and Distortions in Transformer-based RDF-to-Text Models
Sep 25, 2024
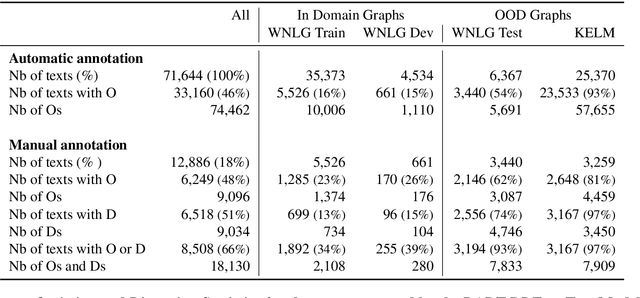
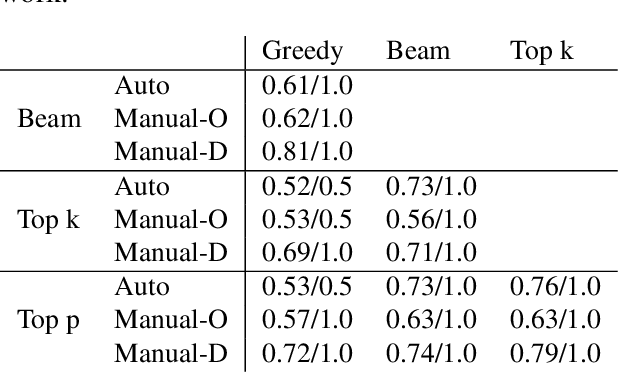
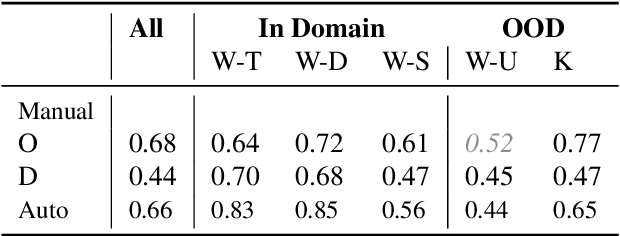
In Natural Language Generation (NLG), important information is sometimes omitted in the output text. To better understand and analyse how this type of mistake arises, we focus on RDF-to-Text generation and explore two methods of probing omissions in the encoder output of BART (Lewis et al, 2020) and of T5 (Raffel et al, 2019): (i) a novel parameter-free probing method based on the computation of cosine similarity between embeddings of RDF graphs and of RDF graphs in which we removed some entities and (ii) a parametric probe which performs binary classification on the encoder embeddings to detect omitted entities. We also extend our analysis to distorted entities, i.e. entities that are not fully correctly mentioned in the generated text (e.g. misspelling of entity, wrong units of measurement). We found that both omitted and distorted entities can be probed in the encoder's output embeddings. This suggests that the encoder emits a weaker signal for these entities and therefore is responsible for some loss of information. This also shows that probing methods can be used to detect mistakes in the output of NLG models.
Question Generation in Knowledge-Driven Dialog: Explainability and Evaluation
Apr 11, 2024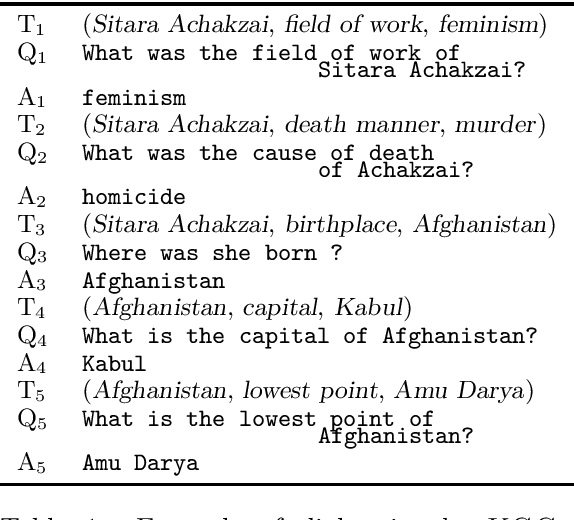



We explore question generation in the context of knowledge-grounded dialogs focusing on explainability and evaluation. Inspired by previous work on planning-based summarisation, we present a model which instead of directly generating a question, sequentially predicts first a fact then a question. We evaluate our approach on 37k test dialogs adapted from the KGConv dataset and we show that, although more demanding in terms of inference, our approach performs on par with a standard model which solely generates a question while allowing for a detailed referenceless evaluation of the model behaviour in terms of relevance, factuality and pronominalisation.
Evaluating Document Simplification: On the Importance of Separately Assessing Simplicity and Meaning Preservation
Apr 04, 2024



Text simplification intends to make a text easier to read while preserving its core meaning. Intuitively and as shown in previous works, these two dimensions (simplification and meaning preservation) are often-times inversely correlated. An overly conservative text will fail to simplify sufficiently, whereas extreme simplification will degrade meaning preservation. Yet, popular evaluation metrics either aggregate meaning preservation and simplification into a single score (SARI, LENS), or target meaning preservation alone (BERTScore, QuestEval). Moreover, these metrics usually require a set of references and most previous work has only focused on sentence-level simplification. In this paper, we focus on the evaluation of document-level text simplification and compare existing models using distinct metrics for meaning preservation and simplification. We leverage existing metrics from similar tasks and introduce a reference-less metric variant for simplicity, showing that models are mostly biased towards either simplification or meaning preservation, seldom performing well on both dimensions. Making use of the fact that the metrics we use are all reference-less, we also investigate the performance of existing models when applied to unseen data (where reference simplifications are unavailable).
Simplicity Level Estimate (SLE): A Learned Reference-Less Metric for Sentence Simplification
Oct 12, 2023
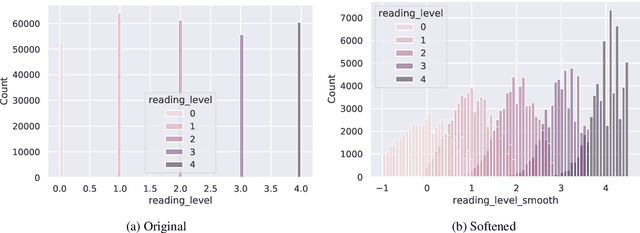

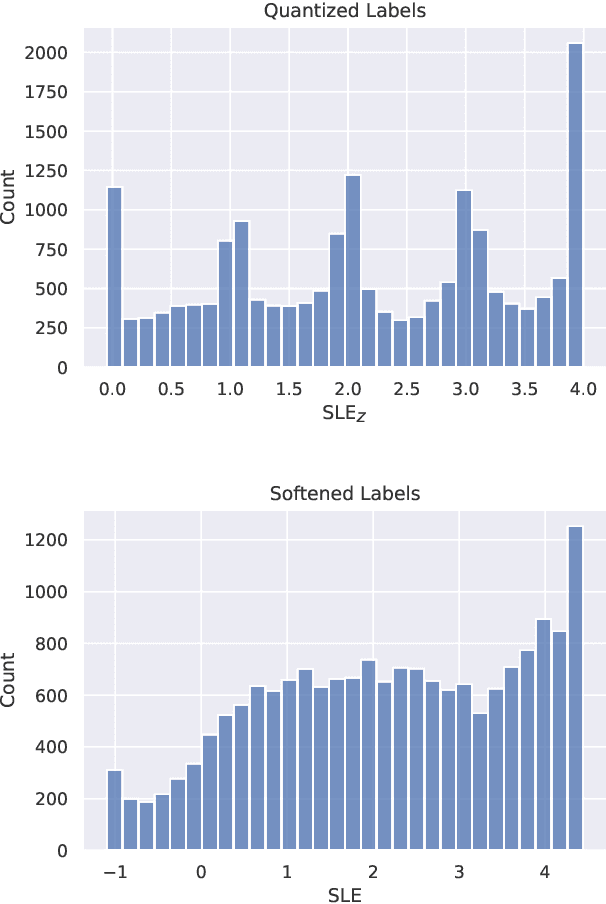
Automatic evaluation for sentence simplification remains a challenging problem. Most popular evaluation metrics require multiple high-quality references -- something not readily available for simplification -- which makes it difficult to test performance on unseen domains. Furthermore, most existing metrics conflate simplicity with correlated attributes such as fluency or meaning preservation. We propose a new learned evaluation metric (SLE) which focuses on simplicity, outperforming almost all existing metrics in terms of correlation with human judgements.
Automatic and Human-AI Interactive Text Generation
Oct 05, 2023In this tutorial, we focus on text-to-text generation, a class of natural language generation (NLG) tasks, that takes a piece of text as input and then generates a revision that is improved according to some specific criteria (e.g., readability or linguistic styles), while largely retaining the original meaning and the length of the text. This includes many useful applications, such as text simplification, paraphrase generation, style transfer, etc. In contrast to text summarization and open-ended text completion (e.g., story), the text-to-text generation tasks we discuss in this tutorial are more constrained in terms of semantic consistency and targeted language styles. This level of control makes these tasks ideal testbeds for studying the ability of models to generate text that is both semantically adequate and stylistically appropriate. Moreover, these tasks are interesting from a technical standpoint, as they require complex combinations of lexical and syntactical transformations, stylistic control, and adherence to factual knowledge, -- all at once. With a special focus on text simplification and revision, this tutorial aims to provide an overview of the state-of-the-art natural language generation research from four major aspects -- Data, Models, Human-AI Collaboration, and Evaluation -- and to discuss and showcase a few significant and recent advances: (1) the use of non-retrogressive approaches; (2) the shift from fine-tuning to prompting with large language models; (3) the development of new learnable metric and fine-grained human evaluation framework; (4) a growing body of studies and datasets on non-English languages; (5) the rise of HCI+NLP+Accessibility interdisciplinary research to create real-world writing assistant systems.
KGConv, a Conversational Corpus grounded in Wikidata
Aug 29, 2023

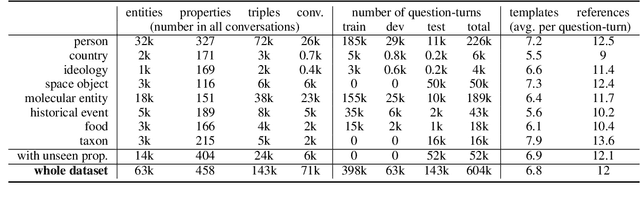

We present KGConv, a large, conversational corpus of 71k conversations where each question-answer pair is grounded in a Wikidata fact. Conversations contain on average 8.6 questions and for each Wikidata fact, we provide multiple variants (12 on average) of the corresponding question using templates, human annotations, hand-crafted rules and a question rewriting neural model. We provide baselines for the task of Knowledge-Based, Conversational Question Generation. KGConv can further be used for other generation and analysis tasks such as single-turn question generation from Wikidata triples, question rewriting, question answering from conversation or from knowledge graphs and quiz generation.
Context-Aware Document Simplification
May 10, 2023To date, most work on text simplification has focused on sentence-level inputs. Early attempts at document simplification merely applied these approaches iteratively over the sentences of a document. However, this fails to coherently preserve the discourse structure, leading to suboptimal output quality. Recently, strategies from controllable simplification have been leveraged to achieve state-of-the-art results on document simplification by first generating a document-level plan (a sequence of sentence-level simplification operations) and using this plan to guide sentence-level simplification downstream. However, this is still limited in that the simplification model has no direct access to the local inter-sentence document context, likely having a negative impact on surface realisation. We explore various systems that use document context within the simplification process itself, either by iterating over larger text units or by extending the system architecture to attend over a high-level representation of document context. In doing so, we achieve state-of-the-art performance on the document simplification task, even when not relying on plan-guidance. Further, we investigate the performance and efficiency tradeoffs of system variants and make suggestions of when each should be preferred.
Joint Representations of Text and Knowledge Graphs for Retrieval and Evaluation
Feb 28, 2023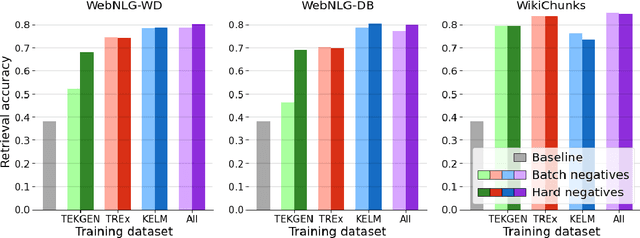
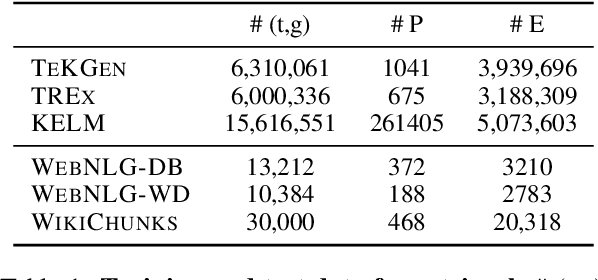
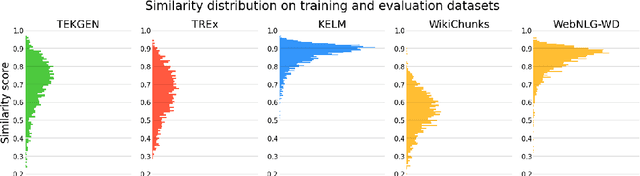
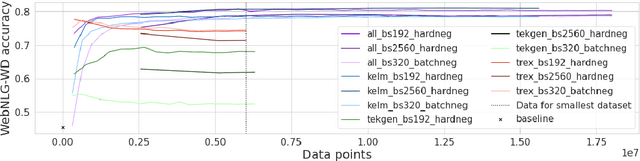
A key feature of neural models is that they can produce semantic vector representations of objects (texts, images, speech, etc.) ensuring that similar objects are close to each other in the vector space. While much work has focused on learning representations for other modalities, there are no aligned cross-modal representations for text and knowledge base (KB) elements. One challenge for learning such representations is the lack of parallel data, which we use contrastive training on heuristics-based datasets and data augmentation to overcome, training embedding models on (KB graph, text) pairs. On WebNLG, a cleaner manually crafted dataset, we show that they learn aligned representations suitable for retrieval. We then fine-tune on annotated data to create EREDAT (Ensembled Representations for Evaluation of DAta-to-Text), a similarity metric between English text and KB graphs. EREDAT outperforms or matches state-of-the-art metrics in terms of correlation with human judgments on WebNLG even though, unlike them, it does not require a reference text to compare against.
Active Learning and Multi-label Classification for Ellipsis and Coreference Detection in Conversational Question-Answering
Jul 07, 2022In human conversations, ellipsis and coreference are commonly occurring linguistic phenomena. Although these phenomena are a mean of making human-machine conversations more fluent and natural, only few dialogue corpora contain explicit indications on which turns contain ellipses and/or coreferences. In this paper we address the task of automatically detecting ellipsis and coreferences in conversational question answering. We propose to use a multi-label classifier based on DistilBERT. Multi-label classification and active learning are employed to compensate the limited amount of labeled data. We show that these methods greatly enhance the performance of the classifier for detecting these phenomena on a manually labeled dataset.
Generating Full Length Wikipedia Biographies: The Impact of Gender Bias on the Retrieval-Based Generation of Women Biographies
Apr 12, 2022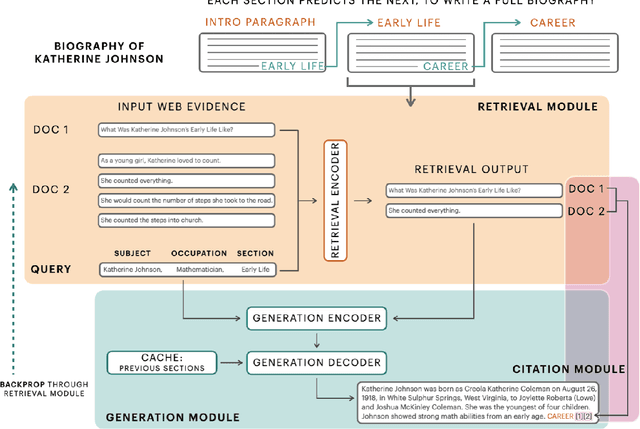



Generating factual, long-form text such as Wikipedia articles raises three key challenges: how to gather relevant evidence, how to structure information into well-formed text, and how to ensure that the generated text is factually correct. We address these by developing a model for English text that uses a retrieval mechanism to identify relevant supporting information on the web and a cache-based pre-trained encoder-decoder to generate long-form biographies section by section, including citation information. To assess the impact of available web evidence on the output text, we compare the performance of our approach when generating biographies about women (for which less information is available on the web) vs. biographies generally. To this end, we curate a dataset of 1,500 biographies about women. We analyze our generated text to understand how differences in available web evidence data affect generation. We evaluate the factuality, fluency, and quality of the generated texts using automatic metrics and human evaluation. We hope that these techniques can be used as a starting point for human writers, to aid in reducing the complexity inherent in the creation of long-form, factual text.