 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Generation in Knowledge-Driven Dialog: Explainability and Evaluation
Apr 11, 2024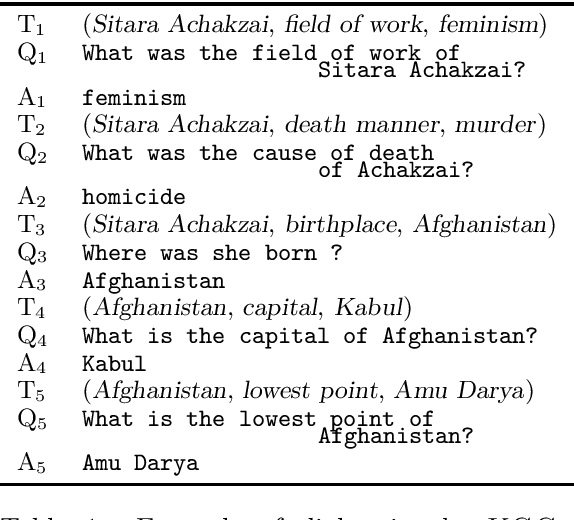



We explore question generation in the context of knowledge-grounded dialogs focusing on explainability and evaluation. Inspired by previous work on planning-based summarisation, we present a model which instead of directly generating a question, sequentially predicts first a fact then a question. We evaluate our approach on 37k test dialogs adapted from the KGConv dataset and we show that, although more demanding in terms of inference, our approach performs on par with a standard model which solely generates a question while allowing for a detailed referenceless evaluation of the model behaviour in terms of relevance, factuality and pronominalisation.
WEBDial, a Multi-domain, Multitask Statistical Dialogue Framework with RDF
Jan 08, 2024



Typically available dialogue frameworks have adopted a semantic representation based on dialogue-acts and slot-value pairs. Despite its simplicity, this representation has disadvantages such as the lack of expressivity, scalability and explainability. We present WEBDial: a dialogue framework that relies on a graph formalism by using RDF triples instead of slot-value pairs. We describe its overall architecture and the graph-based semantic representation. We show its applicability from simple to complex applications, by varying the complexity of domains and tasks: from single domain and tasks to multiple domains and complex tasks.
KGConv, a Conversational Corpus grounded in Wikidata
Aug 29, 2023

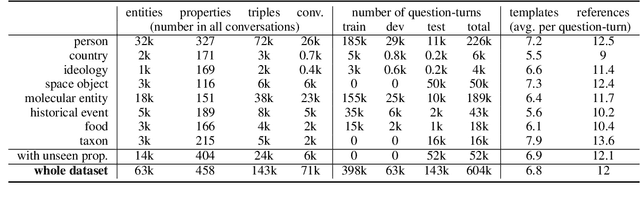

We present KGConv, a large, conversational corpus of 71k conversations where each question-answer pair is grounded in a Wikidata fact. Conversations contain on average 8.6 questions and for each Wikidata fact, we provide multiple variants (12 on average) of the corresponding question using templates, human annotations, hand-crafted rules and a question rewriting neural model. We provide baselines for the task of Knowledge-Based, Conversational Question Generation. KGConv can further be used for other generation and analysis tasks such as single-turn question generation from Wikidata triples, question rewriting, question answering from conversation or from knowledge graphs and quiz generation.
CoQAR: Question Rewriting on CoQA
Jul 07, 2022
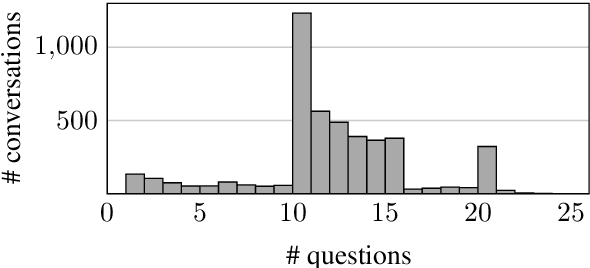
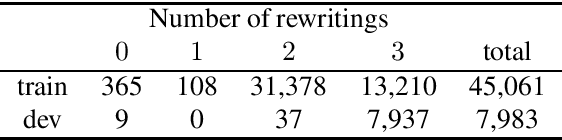
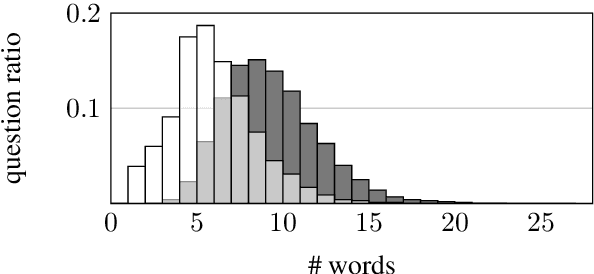
Questions asked by humans during a conversation often contain contextual dependencies, i.e., explicit or implicit references to previous dialogue turns. These dependencies take the form of coreferences (e.g., via pronoun use) or ellipses, and can make the understanding difficult for automated systems. One way to facilitate the understanding and subsequent treatments of a question is to rewrite it into an out-of-context form, i.e., a form that can be understood without the conversational context. We propose CoQAR, a corpus containing $4.5$K conversations from the Conversational Question-Answering dataset CoQA, for a total of $53$K follow-up question-answer pairs. Each original question was manually annotated with at least 2 at most 3 out-of-context rewritings. CoQAR can be used in the supervised learning of three tasks: question paraphrasing, question rewriting and conversational question answering. In order to assess the quality of CoQAR's rewritings, we conduct several experiments consisting in training and evaluating models for these three tasks. Our results support the idea that question rewriting can be used as a preprocessing step for question answering models, thereby increasing their performances.