 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Omissions and Distortions in Transformer-based RDF-to-Text Models
Sep 25, 2024
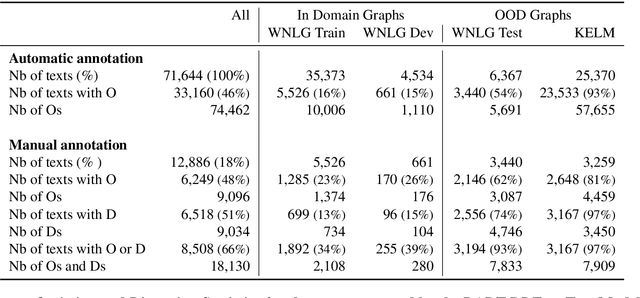
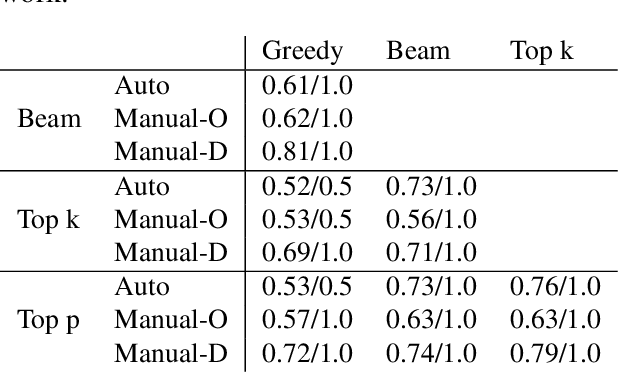
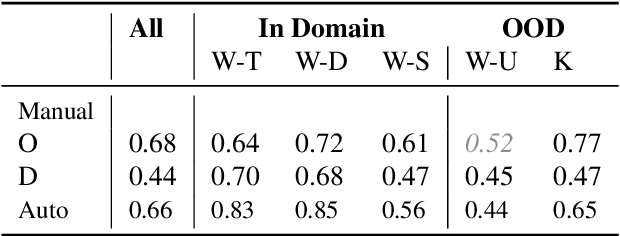
In Natural Language Generation (NLG), important information is sometimes omitted in the output text. To better understand and analyse how this type of mistake arises, we focus on RDF-to-Text generation and explore two methods of probing omissions in the encoder output of BART (Lewis et al, 2020) and of T5 (Raffel et al, 2019): (i) a novel parameter-free probing method based on the computation of cosine similarity between embeddings of RDF graphs and of RDF graphs in which we removed some entities and (ii) a parametric probe which performs binary classification on the encoder embeddings to detect omitted entities. We also extend our analysis to distorted entities, i.e. entities that are not fully correctly mentioned in the generated text (e.g. misspelling of entity, wrong units of measurement). We found that both omitted and distorted entities can be probed in the encoder's output embeddings. This suggests that the encoder emits a weaker signal for these entities and therefore is responsible for some loss of information. This also shows that probing methods can be used to detect mistakes in the output of NLG models.
Question Generation in Knowledge-Driven Dialog: Explainability and Evaluation
Apr 11, 2024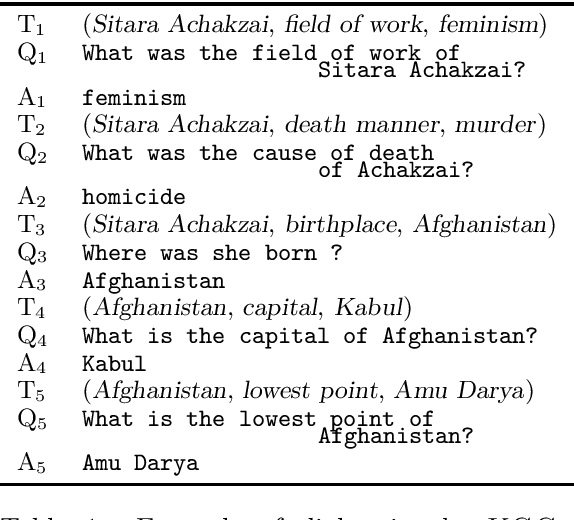



We explore question generation in the context of knowledge-grounded dialogs focusing on explainability and evaluation. Inspired by previous work on planning-based summarisation, we present a model which instead of directly generating a question, sequentially predicts first a fact then a question. We evaluate our approach on 37k test dialogs adapted from the KGConv dataset and we show that, although more demanding in terms of inference, our approach performs on par with a standard model which solely generates a question while allowing for a detailed referenceless evaluation of the model behaviour in terms of relevance, factuality and pronominalisation.