 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnder the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning
Paper and Code
Jun 18, 2024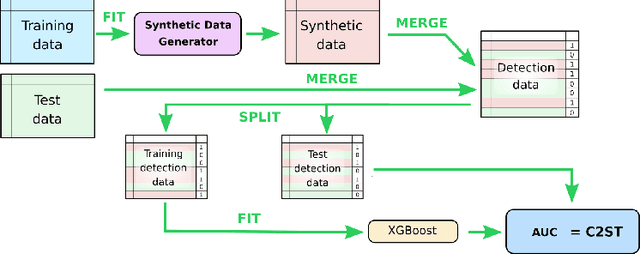
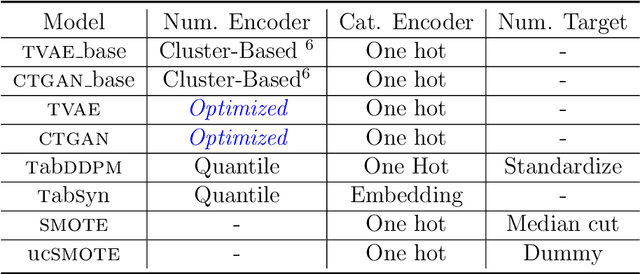
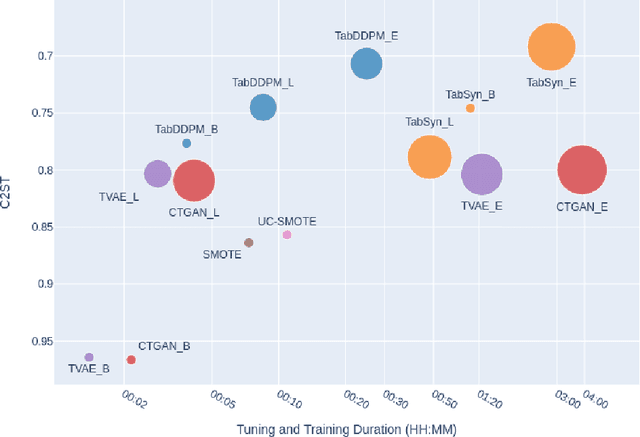
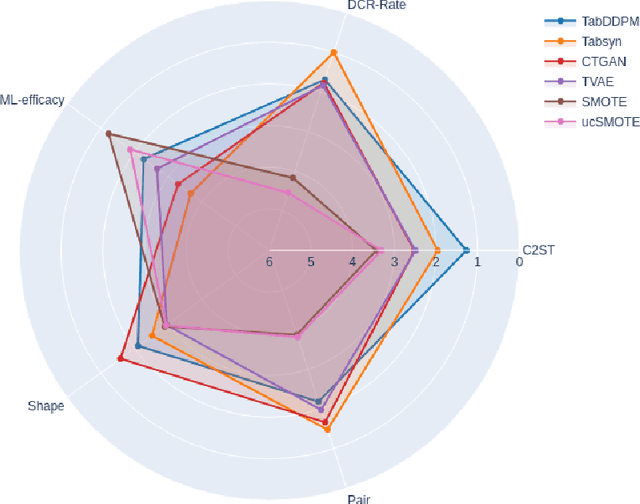
We investigate the impact of dataset-specific hyperparameter, feature encoding, and architecture tuning on five recent model families for tabular data generation through an extensive benchmark on 16 datasets. This study addresses the practical need for a unified evaluation of models that fully considers hyperparameter optimization. Additionally, we propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower cost.Our benchmark demonstrates that, for most models, large-scale dataset-specific tuning substantially improves performance compared to the original configurations. Furthermore, we confirm that diffusion-based models generally outperform other models on tabular data. However, this advantage is not significant when the entire tuning and training process is restricted to the same GPU budget for all models.