 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Tabular Data Detection In the Wild
Paper and Code
Mar 03, 2025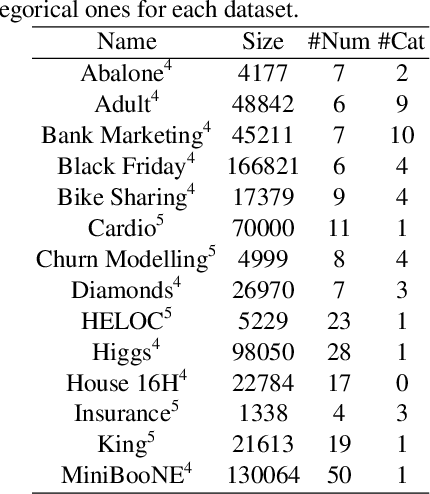
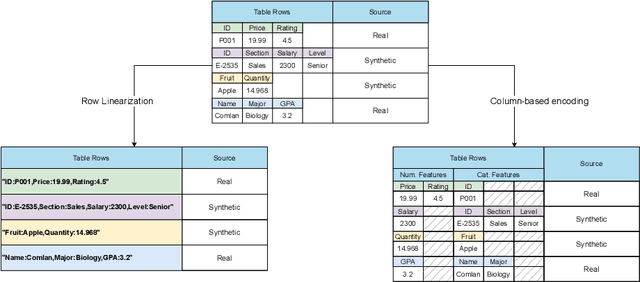
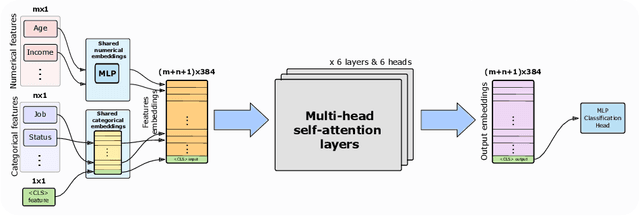
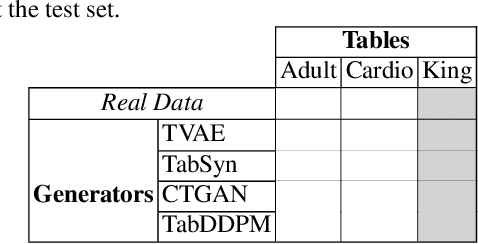
Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified across different tables. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose four table-agnostic detectors combined with simple preprocessing schemes that we evaluate on six evaluation protocols, with different levels of ''wildness''. Our results show that cross-table learning on a restricted set of tables is possible even with naive preprocessing schemes. They confirm however that cross-table transfer (i.e. deployment on a table that has not been seen before) is challenging. This suggests that sophisticated encoding schemes are required to handle this problem.