 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRIQT: Physics-Aware Diffusion Model for Image Quality Transfer in Neonatal Ultra-Low-Field MRI
Nov 17, 2025Portable ultra-low-field MRI (uLF-MRI, 0.064 T) offers accessible neuroimaging for neonatal care but suffers from low signal-to-noise ratio and poor diagnostic quality compared to high-field (HF) MRI. We propose MRIQT, a 3D conditional diffusion framework for image quality transfer (IQT) from uLF to HF MRI. MRIQT combines realistic K-space degradation for physics-consistent uLF simulation, v-prediction with classifier-free guidance for stable image-to-image generation, and an SNR-weighted 3D perceptual loss for anatomical fidelity. The model denoises from a noised uLF input conditioned on the same scan, leveraging volumetric attention-UNet architecture for structure-preserving translation. Trained on a neonatal cohort with diverse pathologies, MRIQT surpasses recent GAN and CNN baselines in PSNR 15.3% with 1.78% over the state of the art, while physicians rated 85% of its outputs as good quality with clear pathology present. MRIQT enables high-fidelity, diffusion-based enhancement of portable ultra-low-field (uLF) MRI for deliable neonatal brain assessment.
Bias and Generalizability of Foundation Models across Datasets in Breast Mammography
May 19, 2025Over the past decades, computer-aided diagnosis tools for breast cancer have been developed to enhance screening procedures, yet their clinical adoption remains challenged by data variability and inherent biases. Although foundation models (FMs) have recently demonstrated impressive generalizability and transfer learning capabilities by leveraging vast and diverse datasets, their performance can be undermined by spurious correlations that arise from variations in image quality, labeling uncertainty, and sensitive patient attributes. In this work, we explore the fairness and bias of FMs for breast mammography classification by leveraging a large pool of datasets from diverse sources-including data from underrepresented regions and an in-house dataset. Our extensive experiments show that while modality-specific pre-training of FMs enhances performance, classifiers trained on features from individual datasets fail to generalize across domains. Aggregating datasets improves overall performance, yet does not fully mitigate biases, leading to significant disparities across under-represented subgroups such as extreme breast densities and age groups. Furthermore, while domain-adaptation strategies can reduce these disparities, they often incur a performance trade-off. In contrast, fairness-aware techniques yield more stable and equitable performance across subgroups. These findings underscore the necessity of incorporating rigorous fairness evaluations and mitigation strategies into FM-based models to foster inclusive and generalizable AI.
Mitigating analytical variability in fMRI results with style transfer
Apr 04, 2024We propose a novel approach to improve the reproducibility of neuroimaging results by converting statistic maps across different functional MRI pipelines. We make the assumption that pipelines can be considered as a style component of data and propose to use different generative models, among which, Diffusion Models (DM) to convert data between pipelines. We design a new DM-based unsupervised multi-domain image-to-image transition framework and constrain the generation of 3D fMRI statistic maps using the latent space of an auxiliary classifier that distinguishes statistic maps from different pipelines. We extend traditional sampling techniques used in DM to improve the transition performance. Our experiments demonstrate that our proposed methods are successful: pipelines can indeed be transferred, providing an important source of data augmentation for future medical studies.
Uncovering communities of pipelines in the task-fMRI analytical space
Dec 11, 2023



Functional magnetic resonance imaging analytical workflows are highly flexible with no definite consensus on how to choose a pipeline. While methods have been developed to explore this analytical space, there is still a lack of understanding of the relationships between the different pipelines. We use community detection algorithms to explore the pipeline space and assess its stability across different contexts. We show that there are subsets of pipelines that give similar results, especially those sharing specific parameters (e.g. number of motion regressors, software packages, etc.), with relative stability across groups of participants. By visualizing the differences between these subsets, we describe the effect of pipeline parameters and derive general relationships in the analytical space.
On the benefits of self-taught learning for brain decoding
Sep 19, 2022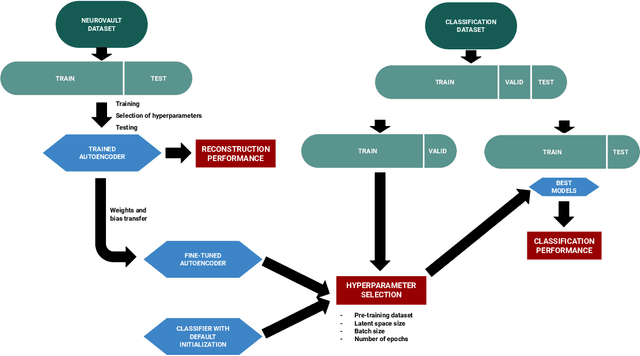
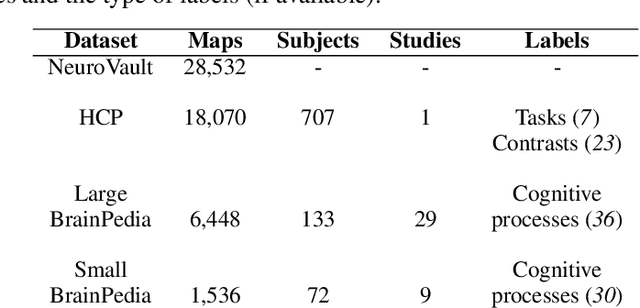
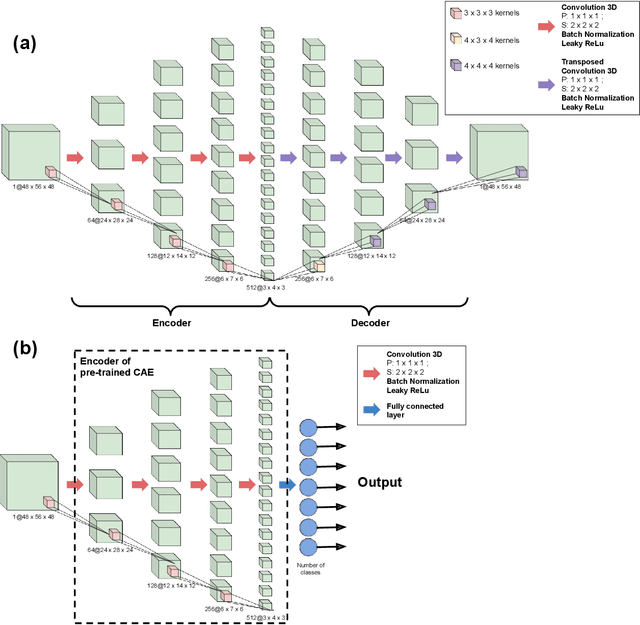

We study the benefits of using a large public neuroimaging database composed of fMRI statistic maps, in a self-taught learning framework, for improving brain decoding on new tasks. First, we leverage the NeuroVault database to train, on a selection of relevant statistic maps, a convolutional autoencoder to reconstruct these maps. Then, we use this trained encoder to initialize a supervised convolutional neural network to classify tasks or cognitive processes of unseen statistic maps from large collections of the NeuroVault database. We show that such a self-taught learning process always improves the performance of the classifiers but the magnitude of the benefits strongly depends on the number of data available both for pre-training and finetuning the models and on the complexity of the targeted downstream task.