 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised contrastive learning for cell stage classification of animal embryos
Feb 11, 2025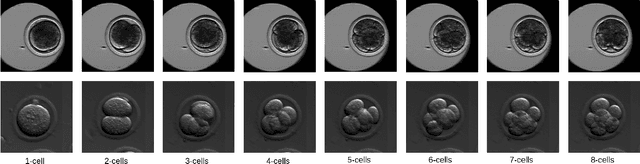
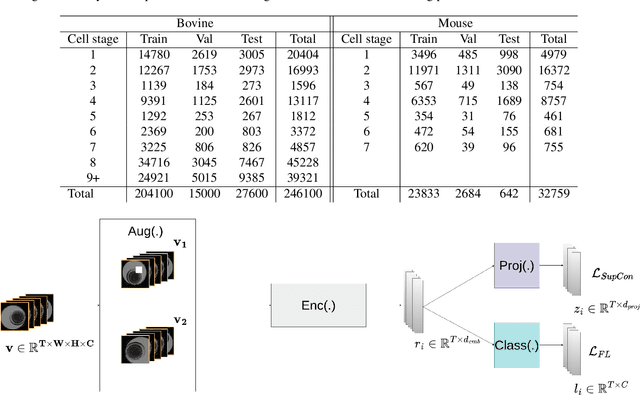
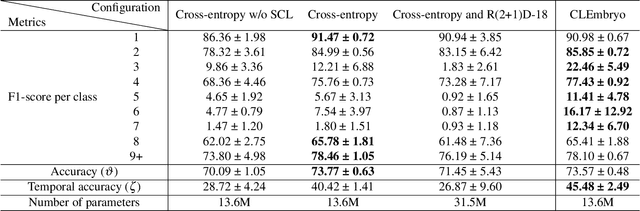

Video microscopy, when combined with machine learning, offers a promising approach for studying the early development of in vitro produced (IVP) embryos. However, manually annotating developmental events, and more specifically cell divisions, is time-consuming for a biologist and cannot scale up for practical applications. We aim to automatically classify the cell stages of embryos from 2D time-lapse microscopy videos with a deep learning approach. We focus on the analysis of bovine embryonic development using video microscopy, as we are primarily interested in the application of cattle breeding, and we have created a Bovine Embryos Cell Stages (ECS) dataset. The challenges are three-fold: (1) low-quality images and bovine dark cells that make the identification of cell stages difficult, (2) class ambiguity at the boundaries of developmental stages, and (3) imbalanced data distribution. To address these challenges, we introduce CLEmbryo, a novel method that leverages supervised contrastive learning combined with focal loss for training, and the lightweight 3D neural network CSN-50 as an encoder. We also show that our method generalizes well. CLEmbryo outperforms state-of-the-art methods on both our Bovine ECS dataset and the publicly available NYU Mouse Embryos dataset.
Early prediction of the transferability of bovine embryos from videomicroscopy
Jan 14, 2025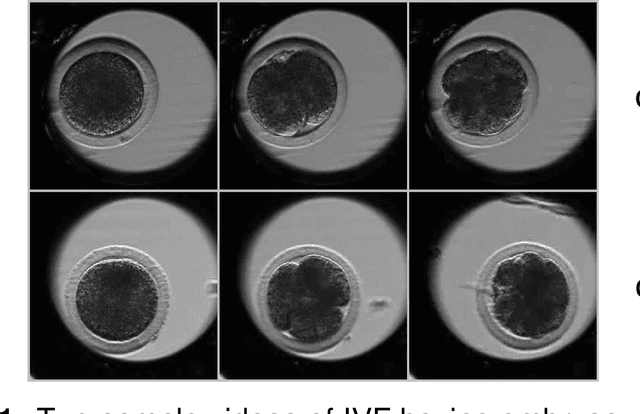

Videomicroscopy is a promising tool combined with machine learning for studying the early development of in vitro fertilized bovine embryos and assessing its transferability as soon as possible. We aim to predict the embryo transferability within four days at most, taking 2D time-lapse microscopy videos as input. We formulate this problem as a supervised binary classification problem for the classes transferable and not transferable. The challenges are three-fold: 1) poorly discriminating appearance and motion, 2) class ambiguity, 3) small amount of annotated data. We propose a 3D convolutional neural network involving three pathways, which makes it multi-scale in time and able to handle appearance and motion in different ways. For training, we retain the focal loss. Our model, named SFR, compares favorably to other methods. Experiments demonstrate its effectiveness and accuracy for our challenging biological task.
* Accepted at the 2024 IEEE International Conference on Image Processing
Unsupervised motion segmentation in one go: Smooth long-term model over a video
Oct 02, 2023



Human beings have the ability to continuously analyze a video and immediately extract the main motion components. Motion segmentation methods often proceed frame by frame. We want to go beyond this classical paradigm, and perform the motion segmentation over a video sequence in one go. It will be a prominent added value for downstream computer vision tasks, and could provide a pretext criterion for unsupervised video representation learning. In this perspective, we propose a novel long-term spatio-temporal model operating in a totally unsupervised way. It takes as input the volume of consecutive optical flow (OF) fields, and delivers a volume of segments of coherent motion over the video. More specifically, we have designed a transformer-based network, where we leverage a mathematically well-founded framework, the Evidence Lower Bound (ELBO), to infer the loss function. The loss function combines a flow reconstruction term involving spatio-temporal parametric motion models combining, in a novel way, polynomial (quadratic) motion models for the $(x,y)$-spatial dimensions and B-splines for the time dimension of the video sequence, and a regularization term enforcing temporal consistency on the masks. We report experiments on four VOS benchmarks with convincing quantitative results. We also highlight through visual results the key contributions on temporal consistency brought by our method.
EM-driven unsupervised learning for efficient motion segmentation
Jan 06, 2022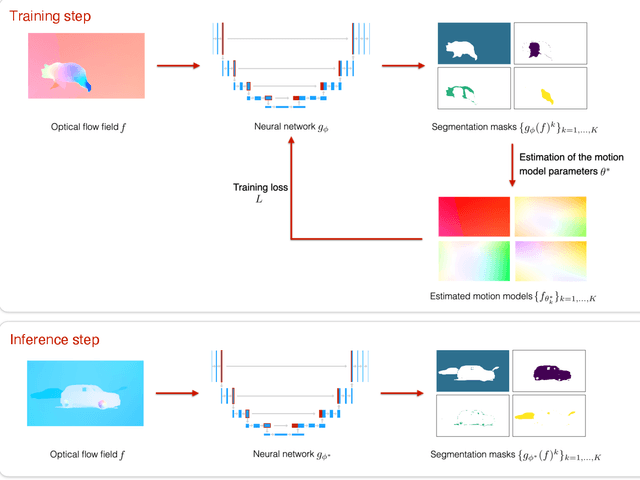

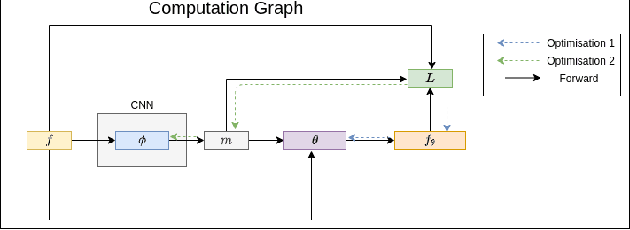

This paper presents a CNN-based fully unsupervised method for motion segmentation from optical flow. We assume that the input optical flow can be represented as a piecewise set of parametric motion models, typically, affine or quadratic motion models.The core idea of this work is to leverage the Expectation-Maximization (EM) framework. It enables us to design in a well-founded manner the loss function and the training procedure of our motion segmentation neural network. However, in contrast to the classical iterative EM, once the network is trained, we can provide a segmentation for any unseen optical flow field in a single inference step, with no dependence on the initialization of the motion model parameters since they are not estimated in the inference stage. Different loss functions have been investigated including robust ones. We also propose a novel data augmentation technique on the optical flow field with a noticeable impact on the performance. We tested our motion segmentation network on the DAVIS2016 dataset. Our method outperforms comparable unsupervised methods and is very efficient. Indeed, it can run at 125fps making it usable for real-time applications.
Learning how to be robust: Deep polynomial regression
May 23, 2018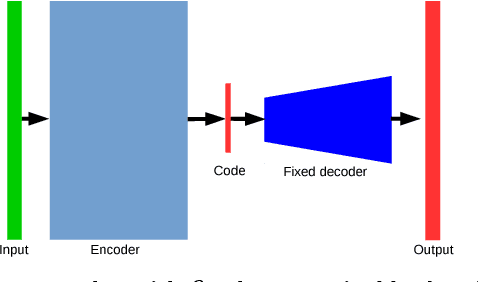

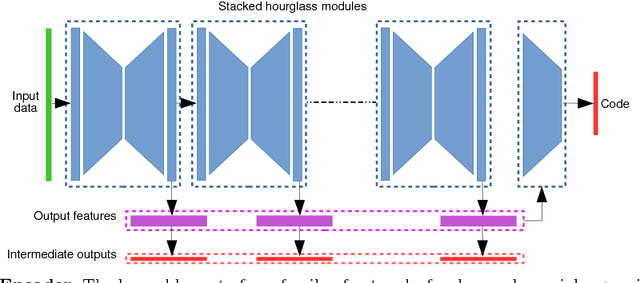

Polynomial regression is a recurrent problem with a large number of applications. In computer vision it often appears in motion analysis. Whatever the application, standard methods for regression of polynomial models tend to deliver biased results when the input data is heavily contaminated by outliers. Moreover, the problem is even harder when outliers have strong structure. Departing from problem-tailored heuristics for robust estimation of parametric models, we explore deep convolutional neural networks. Our work aims to find a generic approach for training deep regression models without the explicit need of supervised annotation. We bypass the need for a tailored loss function on the regression parameters by attaching to our model a differentiable hard-wired decoder corresponding to the polynomial operation at hand. We demonstrate the value of our findings by comparing with standard robust regression methods. Furthermore, we demonstrate how to use such models for a real computer vision problem, i.e., video stabilization. The qualitative and quantitative experiments show that neural networks are able to learn robustness for general polynomial regression, with results that well overpass scores of traditional robust estimation methods.
Tubelets: Unsupervised action proposals from spatiotemporal super-voxels
Jul 07, 2016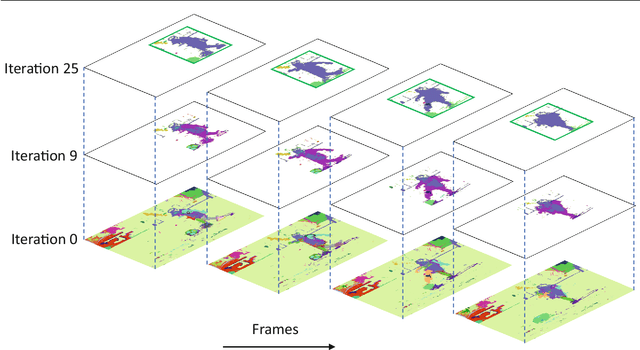
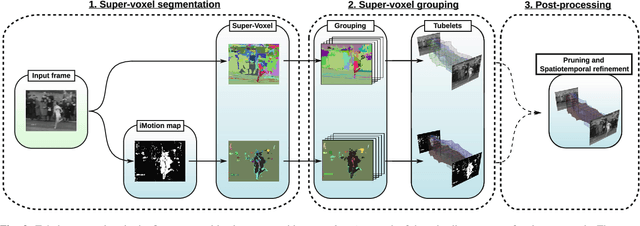
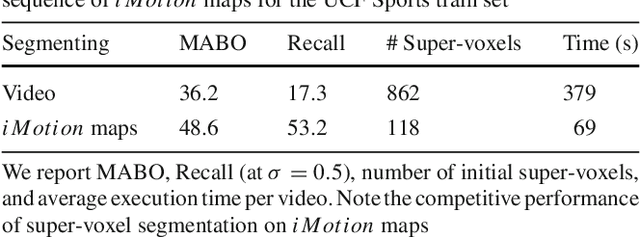

This paper considers the problem of localizing actions in videos as a sequences of bounding boxes. The objective is to generate action proposals that are likely to include the action of interest, ideally achieving high recall with few proposals. Our contributions are threefold. First, inspired by selective search for object proposals, we introduce an approach to generate action proposals from spatiotemporal super-voxels in an unsupervised manner, we call them Tubelets. Second, along with the static features from individual frames our approach advantageously exploits motion. We introduce independent motion evidence as a feature to characterize how the action deviates from the background and explicitly incorporate such motion information in various stages of the proposal generation. Finally, we introduce spatiotemporal refinement of Tubelets, for more precise localization of actions, and pruning to keep the number of Tubelets limited. We demonstrate the suitability of our approach by extensive experiments for action proposal quality and action localization on three public datasets: UCF Sports, MSR-II and UCF101. For action proposal quality, our unsupervised proposals beat all other existing approaches on the three datasets. For action localization, we show top performance on both the trimmed videos of UCF Sports and UCF101 as well as the untrimmed videos of MSR-II.
Aggregation of local parametric candidates with exemplar-based occlusion handling for optical flow
Jul 22, 2014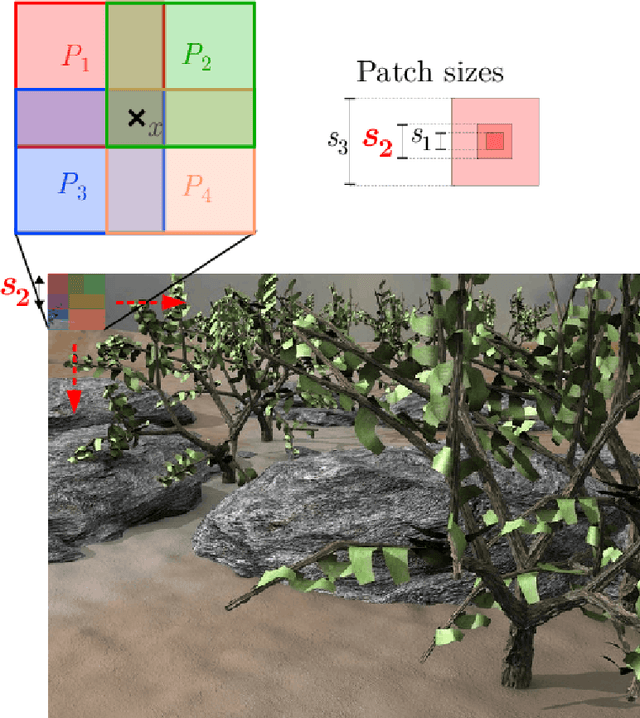



Handling all together large displacements, motion details and occlusions remains an open issue for reliable computation of optical flow in a video sequence. We propose a two-step aggregation paradigm to address this problem. The idea is to supply local motion candidates at every pixel in a first step, and then to combine them to determine the global optical flow field in a second step. We exploit local parametric estimations combined with patch correspondences and we experimentally demonstrate that they are sufficient to produce highly accurate motion candidates. The aggregation step is designed as the discrete optimization of a global regularized energy. The occlusion map is estimated jointly with the flow field throughout the two steps. We propose a generic exemplar-based approach for occlusion filling with motion vectors. We achieve state-of-the-art results in computer vision benchmarks, with particularly significant improvements in the case of large displacements and occlusions.