 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumiCtrl : Learning Illuminant Prompts for Lighting Control in Personalized Text-to-Image Models
Dec 19, 2025Current text-to-image (T2I) models have demonstrated remarkable progress in creative image generation, yet they still lack precise control over scene illuminants, which is a crucial factor for content designers aiming to manipulate the mood, atmosphere, and visual aesthetics of generated images. In this paper, we present an illuminant personalization method named LumiCtrl that learns an illuminant prompt given a single image of an object. LumiCtrl consists of three basic components: given an image of the object, our method applies (a) physics-based illuminant augmentation along the Planckian locus to create fine-tuning variants under standard illuminants; (b) edge-guided prompt disentanglement using a frozen ControlNet to ensure prompts focus on illumination rather than structure; and (c) a masked reconstruction loss that focuses learning on the foreground object while allowing the background to adapt contextually, enabling what we call contextual light adaptation. We qualitatively and quantitatively compare LumiCtrl against other T2I customization methods. The results show that our method achieves significantly better illuminant fidelity, aesthetic quality, and scene coherence compared to existing personalization baselines. A human preference study further confirms strong user preference for LumiCtrl outputs. The code and data will be released upon publication.
GenColorBench: A Color Evaluation Benchmark for Text-to-Image Generation Models
Oct 23, 2025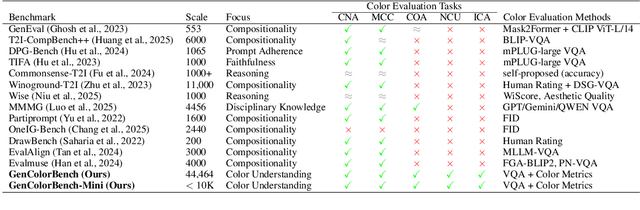

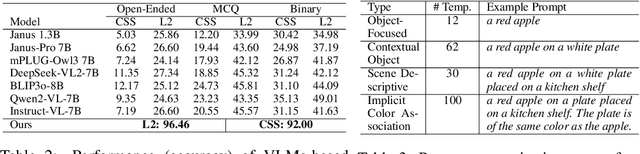
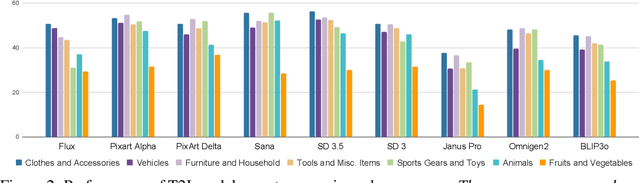
Recent years have seen impressive advances in text-to-image generation, with image generative or unified models producing high-quality images from text. Yet these models still struggle with fine-grained color controllability, often failing to accurately match colors specified in text prompts. While existing benchmarks evaluate compositional reasoning and prompt adherence, none systematically assess color precision. Color is fundamental to human visual perception and communication, critical for applications from art to design workflows requiring brand consistency. However, current benchmarks either neglect color or rely on coarse assessments, missing key capabilities such as interpreting RGB values or aligning with human expectations. To this end, we propose GenColorBench, the first comprehensive benchmark for text-to-image color generation, grounded in color systems like ISCC-NBS and CSS3/X11, including numerical colors which are absent elsewhere. With 44K color-focused prompts covering 400+ colors, it reveals models' true capabilities via perceptual and automated assessments. Evaluations of popular text-to-image models using GenColorBench show performance variations, highlighting which color conventions models understand best and identifying failure modes. Our GenColorBench assessments will guide improvements in precise color generation. The benchmark will be made public upon acceptance.
Deep Spectral Reflectance and Illuminant Estimation from Self-Interreflections
Dec 09, 2018
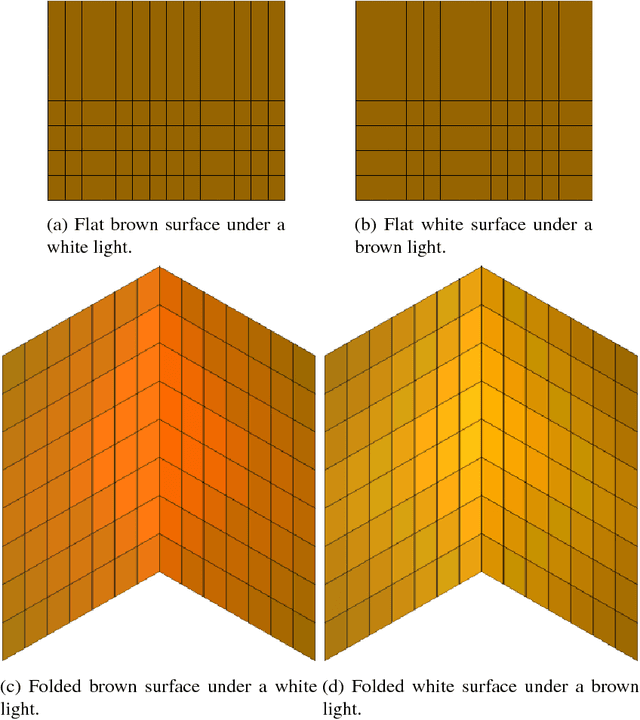
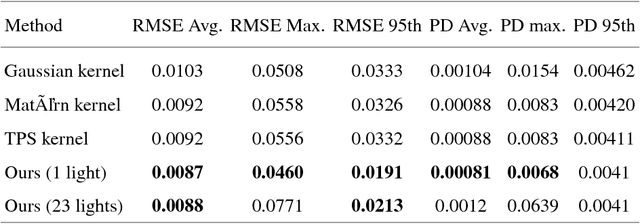
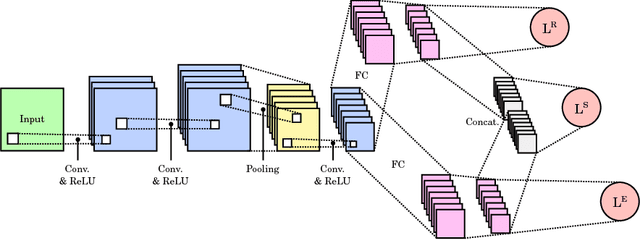
In this work, we propose a CNN-based approach to estimate the spectral reflectance of a surface and the spectral power distribution of the light from a single RGB image of a V-shaped surface. Interreflections happening in a concave surface lead to gradients of RGB values over its area. These gradients carry a lot of information concerning the physical properties of the surface and the illuminant. Our network is trained with only simulated data constructed using a physics-based interreflection model. Coupling interreflection effects with deep learning helps to retrieve the spectral reflectance under an unknown light and to estimate the spectral power distribution of this light as well. In addition, it is more robust to the presence of image noise than the classical approaches. Our results show that the proposed approach outperforms the state of the art learning-based approaches on simulated data. In addition, it gives better results on real data compared to other interreflection-based approaches.