 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoBench: Benchmarking LLMs on Hard Topological Reasoning
Mar 12, 2026Solving topological grid puzzles requires reasoning over global spatial invariants such as connectivity, loop closure, and region symmetry and remains challenging for even the most powerful large language models (LLMs). To study these abilities under controlled settings, we introduce TopoBench, a benchmark of six puzzle families across three difficulty levels. We evaluate strong reasoning LLMs on TopoBench and find that even frontier models solve fewer than one quarter of hard instances, with two families nearly unsolved. To investigate whether these failures stem from reasoning limitations or from difficulty extracting and maintaining spatial constraints, we annotate 750 chain of thought traces with an error taxonomy that surfaces four candidate causal failure modes, then test them with targeted interventions simulating each error type. These interventions show that certain error patterns like premature commitment and constraint forgetting have a direct impact on the ability to solve the puzzle, while repeated reasoning is a benign effect of search. Finally we study mitigation strategies including prompt guidance, cell-aligned grid representations and tool-based constraint checking, finding that the bottleneck lies in extracting constraints from spatial representations and not in reasoning over them. Code and data are available at github.com/mayug/topobench-benchmark.
Metamorphic Testing for Pose Estimation Systems
Feb 13, 2025Pose estimation systems are used in a variety of fields, from sports analytics to livestock care. Given their potential impact, it is paramount to systematically test their behaviour and potential for failure. This is a complex task due to the oracle problem and the high cost of manual labelling necessary to build ground truth keypoints. This problem is exacerbated by the fact that different applications require systems to focus on different subjects (e.g., human versus animal) or landmarks (e.g., only extremities versus whole body and face), which makes labelled test data rarely reusable. To combat these problems we propose MET-POSE, a metamorphic testing framework for pose estimation systems that bypasses the need for manual annotation while assessing the performance of these systems under different circumstances. MET-POSE thus allows users of pose estimation systems to assess the systems in conditions that more closely relate to their application without having to label an ad-hoc test dataset or rely only on available datasets, which may not be adapted to their application domain. While we define MET-POSE in general terms, we also present a non-exhaustive list of metamorphic rules that represent common challenges in computer vision applications, as well as a specific way to evaluate these rules. We then experimentally show the effectiveness of MET-POSE by applying it to Mediapipe Holistic, a state of the art human pose estimation system, with the FLIC and PHOENIX datasets. With these experiments, we outline numerous ways in which the outputs of MET-POSE can uncover faults in pose estimation systems at a similar or higher rate than classic testing using hand labelled data, and show that users can tailor the rule set they use to the faults and level of accuracy relevant to their application.
What's left can't be right -- The remaining positional incompetence of contrastive vision-language models
Nov 20, 2023Contrastive vision-language models like CLIP have been found to lack spatial understanding capabilities. In this paper we discuss the possible causes of this phenomenon by analysing both datasets and embedding space. By focusing on simple left-right positional relations, we show that this behaviour is entirely predictable, even with large-scale datasets, demonstrate that these relations can be taught using synthetic data and show that this approach can generalise well to natural images - improving the performance on left-right relations on Visual Genome Relations.
Towards the extraction of robust sign embeddings for low resource sign language recognition
Jun 30, 2023Isolated Sign Language Recognition (SLR) has mostly been applied on relatively large datasets containing signs executed slowly and clearly by a limited group of signers. In real-world scenarios, however, we are met with challenging visual conditions, coarticulated signing, small datasets, and the need for signer independent models. To tackle this difficult problem, we require a robust feature extractor to process the sign language videos. One could expect human pose estimators to be ideal candidates. However, due to a domain mismatch with their training sets and challenging poses in sign language, they lack robustness on sign language data and image based models often still outperform keypoint based models. Furthermore, whereas the common practice of transfer learning with image based models yields even higher accuracy, keypoint based models are typically trained from scratch on every SLR dataset. These factors limit their usefulness for SLR. From the existing literature, it is also not clear which, if any, pose estimator performs best for SLR. We compare the three most popular pose estimators for SLR: OpenPose, MMPose and MediaPipe. We show that through keypoint normalization, missing keypoint imputation, and learning a pose embedding, we can obtain significantly better results and enable transfer learning. We show that keypoint-based embeddings contain cross-lingual features: they can transfer between sign languages and achieve competitive performance even when fine-tuning only the classifier layer of an SLR model on a target sign language. We furthermore achieve better performance using fine-tuned transferred embeddings than models trained only on the target sign language. The application of these embeddings could prove particularly useful for low resource sign languages in the future.
Deep Context-Aware Novelty Detection
Jun 01, 2020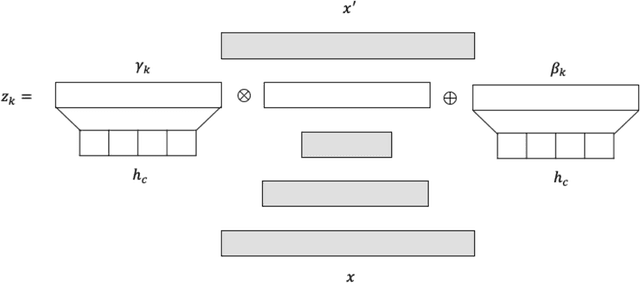
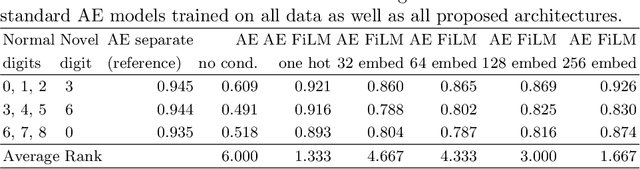
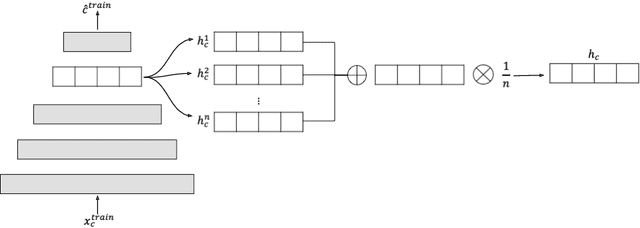
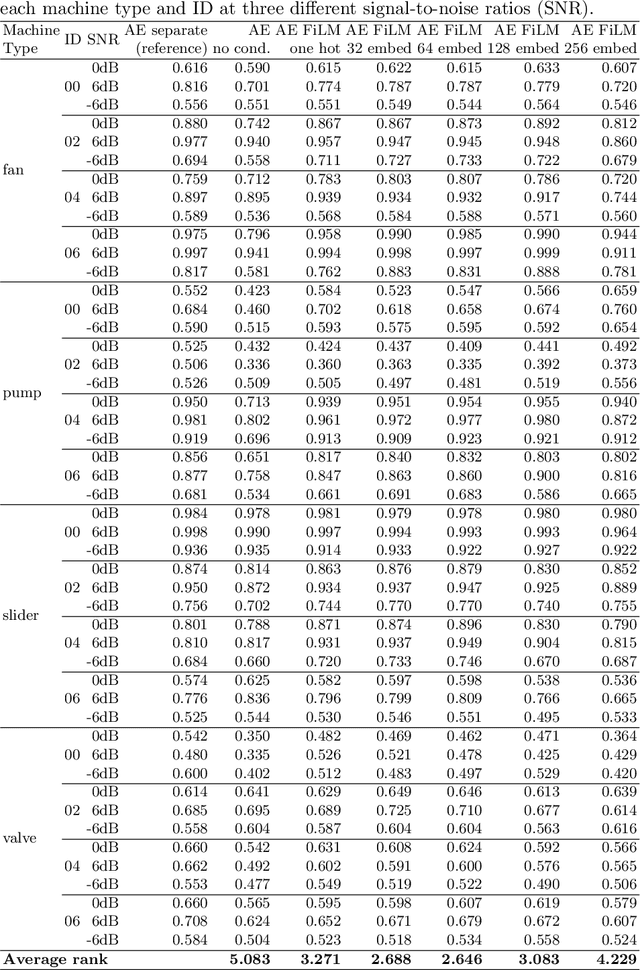
A common assumption of novelty detection is that the distribution of both "normal" and "novel" data are static. However, this is often not the case in scenarios where data evolves over time, or when the definition of normal and novel depends on contextual information, leading to changes in these distributions. This can lead to significant difficulties when attempting to train a model on datasets where the distribution of normal data in one scenario is similar to that of novel data in another scenario. In this paper we propose a context-aware approach to novelty detection for deep autoencoders. We create a semi-supervised network architecture which utilises auxiliary labels in order to reveal contextual information and allows the model to adapt to a variety of normal and novel scenarios. We evaluate our approach on both synthetic image data and real world audio data displaying these characteristics.
Personalized, Health-Aware Recipe Recommendation: An Ensemble Topic Modeling Based Approach
Jul 31, 2019
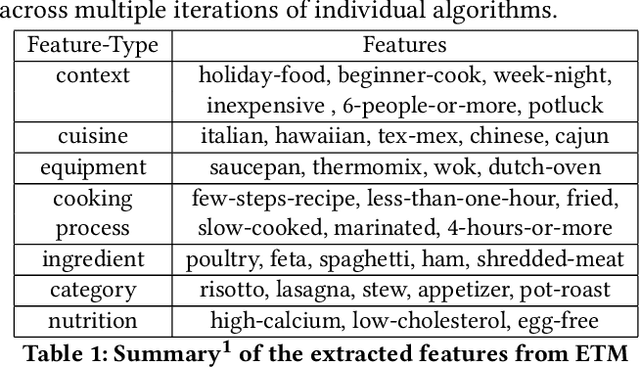

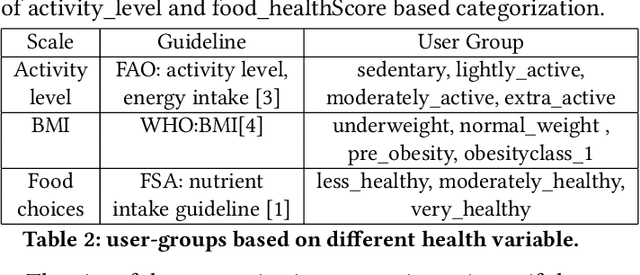
Food choices are personal and complex and have a significant impact on our long-term health and quality of life. By helping users to make informed and satisfying decisions, Recommender Systems (RS) have the potential to support users in making healthier food choices. Intelligent users-modeling is a key challenge in achieving this potential. This paper investigates Ensemble Topic Modelling (EnsTM) based Feature Identification techniques for efficient user-modeling and recipe recommendation. It builds on findings in EnsTM to propose a reduced data representation format and a smart user-modeling strategy that makes capturing user-preference fast, efficient and interactive. This approach enables personalization, even in a cold-start scenario. This paper proposes two different EnsTM based and one Hybrid EnsTM based recommenders. We compared all three EnsTM based variations through a user study with 48 participants, using a large-scale,real-world corpus of 230,876 recipes, and compare against a conventional Content Based (CB) approach. EnsTM based recommenders performed significantly better than the CB approach. Besides acknowledging multi-domain contents such as taste, demographics and cost, our proposed approach also considers user's nutritional preference and assists them finding recipes under diverse nutritional categories. Furthermore, it provides excellent coverage and enables implicit understanding of user's food practices. Subsequent analysis also exposed correlation between certain features and a healthier lifestyle.