 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Signs as Signs: One-Shot ISLR to Facilitate Functional Sign Language Technologies
Feb 27, 2025Isolated Sign Language Recognition (ISLR) is crucial for scalable sign language technology, yet language-specific approaches limit current models. To address this, we propose a one-shot learning approach that generalises across languages and evolving vocabularies. Our method involves pretraining a model to embed signs based on essential features and using a dense vector search for rapid, accurate recognition of unseen signs. We achieve state-of-the-art results, including 50.8% one-shot MRR on a large dictionary containing 10,235 unique signs from a different language than the training set. Our approach is robust across languages and support sets, offering a scalable, adaptable solution for ISLR. Co-created with the Deaf and Hard of Hearing (DHH) community, this method aligns with real-world needs, and advances scalable sign language recognition.
Word Synchronization Challenge: A Benchmark for Word Association Responses for LLMs
Feb 12, 2025This paper introduces the Word Synchronization Challenge, a novel benchmark to evaluate large language models (LLMs) in Human-Computer Interaction (HCI). This benchmark uses a dynamic game-like framework to test LLMs ability to mimic human cognitive processes through word associations. By simulating complex human interactions, it assesses how LLMs interpret and align with human thought patterns during conversational exchanges, which are essential for effective social partnerships in HCI. Initial findings highlight the influence of model sophistication on performance, offering insights into the models capabilities to engage in meaningful social interactions and adapt behaviors in human-like ways. This research advances the understanding of LLMs potential to replicate or diverge from human cognitive functions, paving the way for more nuanced and empathetic human-machine collaborations.
Learned Thresholds Token Merging and Pruning for Vision Transformers
Jul 20, 2023Vision transformers have demonstrated remarkable success in a wide range of computer vision tasks over the last years. However, their high computational costs remain a significant barrier to their practical deployment. In particular, the complexity of transformer models is quadratic with respect to the number of input tokens. Therefore techniques that reduce the number of input tokens that need to be processed have been proposed. This paper introduces Learned Thresholds token Merging and Pruning (LTMP), a novel approach that leverages the strengths of both token merging and token pruning. LTMP uses learned threshold masking modules that dynamically determine which tokens to merge and which to prune. We demonstrate our approach with extensive experiments on vision transformers on the ImageNet classification task. Our results demonstrate that LTMP achieves state-of-the-art accuracy across reduction rates while requiring only a single fine-tuning epoch, which is an order of magnitude faster than previous methods. Code is available at https://github.com/Mxbonn/ltmp .
Towards the extraction of robust sign embeddings for low resource sign language recognition
Jun 30, 2023Isolated Sign Language Recognition (SLR) has mostly been applied on relatively large datasets containing signs executed slowly and clearly by a limited group of signers. In real-world scenarios, however, we are met with challenging visual conditions, coarticulated signing, small datasets, and the need for signer independent models. To tackle this difficult problem, we require a robust feature extractor to process the sign language videos. One could expect human pose estimators to be ideal candidates. However, due to a domain mismatch with their training sets and challenging poses in sign language, they lack robustness on sign language data and image based models often still outperform keypoint based models. Furthermore, whereas the common practice of transfer learning with image based models yields even higher accuracy, keypoint based models are typically trained from scratch on every SLR dataset. These factors limit their usefulness for SLR. From the existing literature, it is also not clear which, if any, pose estimator performs best for SLR. We compare the three most popular pose estimators for SLR: OpenPose, MMPose and MediaPipe. We show that through keypoint normalization, missing keypoint imputation, and learning a pose embedding, we can obtain significantly better results and enable transfer learning. We show that keypoint-based embeddings contain cross-lingual features: they can transfer between sign languages and achieve competitive performance even when fine-tuning only the classifier layer of an SLR model on a target sign language. We furthermore achieve better performance using fine-tuned transferred embeddings than models trained only on the target sign language. The application of these embeddings could prove particularly useful for low resource sign languages in the future.
Integrated Photonic Reservoir Computing with All-Optical Readout
Jun 28, 2023



Integrated photonic reservoir computing has been demonstrated to be able to tackle different problems because of its neural network nature. A key advantage of photonic reservoir computing over other neuromorphic paradigms is its straightforward readout system, which facilitates both rapid training and robust, fabrication variation-insensitive photonic integrated hardware implementation for real-time processing. We present our recent development of a fully-optical, coherent photonic reservoir chip integrated with an optical readout system, capitalizing on these benefits. Alongside the integrated system, we also demonstrate a weight update strategy that is suitable for the integrated optical readout hardware. Using this online training scheme, we successfully solved 3-bit header recognition and delayed XOR tasks at 20 Gbps in real-time, all within the optical domain without excess delays.
Hardware-aware mobile building block evaluation for computer vision
Aug 26, 2022



In this work we propose a methodology to accurately evaluate and compare the performance of efficient neural network building blocks for computer vision in a hardware-aware manner. Our comparison uses pareto fronts based on randomly sampled networks from a design space to capture the underlying accuracy/complexity trade-offs. We show that our approach allows to match the information obtained by previous comparison paradigms, but provides more insights in the relationship between hardware cost and accuracy. We use our methodology to analyze different building blocks and evaluate their performance on a range of embedded hardware platforms. This highlights the importance of benchmarking building blocks as a preselection step in the design process of a neural network. We show that choosing the right building block can speed up inference by up to a factor of 2x on specific hardware ML accelerators.
Machine Translation from Signed to Spoken Languages: State of the Art and Challenges
Feb 07, 2022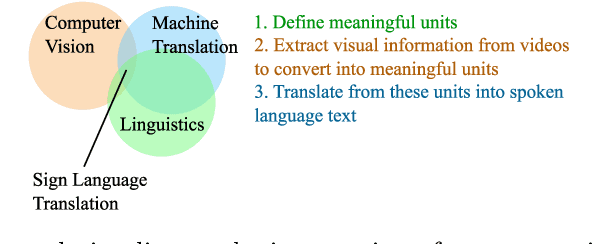
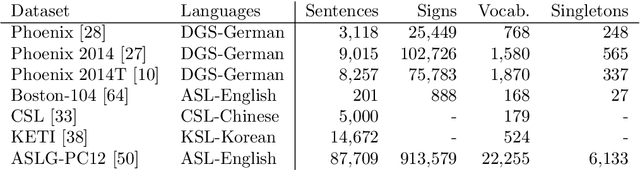

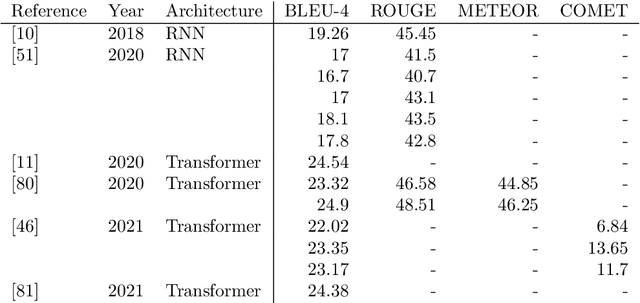
Automatic translation from signed to spoken languages is an interdisciplinary research domain, lying on the intersection of computer vision, machine translation and linguistics. Nevertheless, research in this domain is performed mostly by computer scientists in isolation. As the domain is becoming increasingly popular - the majority of scientific papers on the topic of sign language translation have been published in the past three years - we provide an overview of the state of the art as well as some required background in the different related disciplines. We give a high-level introduction to sign language linguistics and machine translation to illustrate the requirements of automatic sign language translation. We present a systematic literature review to illustrate the state of the art in the domain and then, harking back to the requirements, lay out several challenges for future research. We find that significant advances have been made on the shoulders of spoken language machine translation research. However, current approaches are often not linguistically motivated or are not adapted to the different input modality of sign languages. We explore challenges related to the representation of sign language data, the collection of datasets, the need for interdisciplinary research and requirements for moving beyond research, towards applications. Based on our findings, we advocate for interdisciplinary research and to base future research on linguistic analysis of sign languages. Furthermore, the inclusion of deaf and hearing end users of sign language translation applications in use case identification, data collection and evaluation is of the utmost importance in the creation of useful sign language translation models. We recommend iterative, human-in-the-loop, design and development of sign language translation models.
Anchor Pruning for Object Detection
Apr 01, 2021
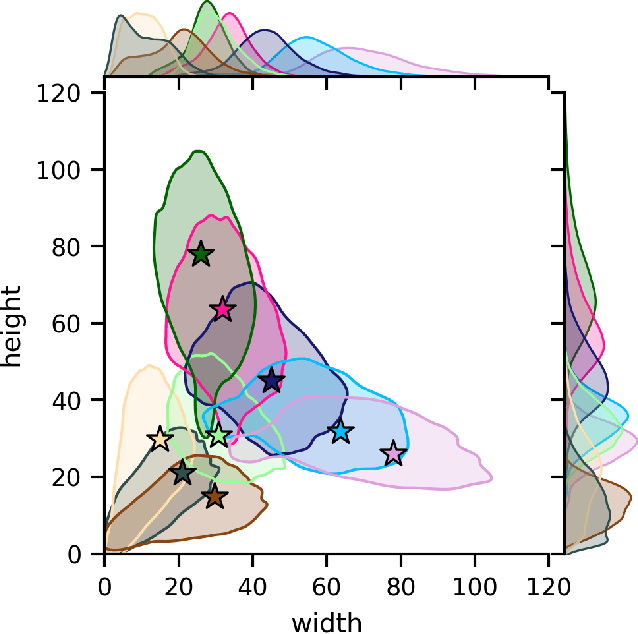
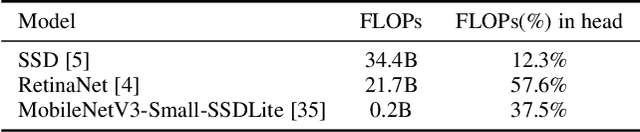
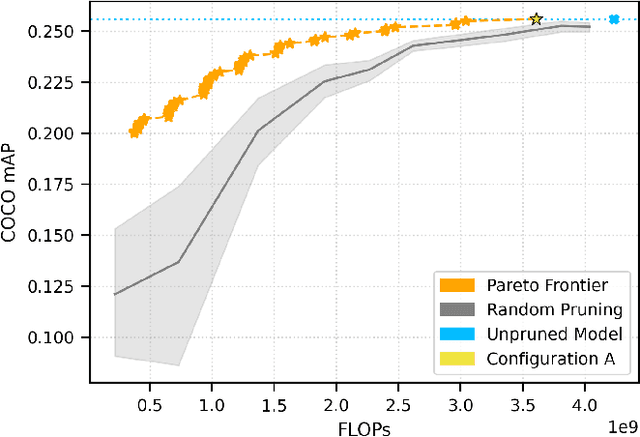
This paper proposes anchor pruning for object detection in one-stage anchor-based detectors. While pruning techniques are widely used to reduce the computational cost of convolutional neural networks, they tend to focus on optimizing the backbone networks where often most computations are. In this work we demonstrate an additional pruning technique, specifically for object detection: anchor pruning. With more efficient backbone networks and a growing trend of deploying object detectors on embedded systems where post-processing steps such as non-maximum suppression can be a bottleneck, the impact of the anchors used in the detection head is becoming increasingly more important. In this work, we show that many anchors in the object detection head can be removed without any loss in accuracy. With additional retraining, anchor pruning can even lead to improved accuracy. Extensive experiments on SSD and MS COCO show that the detection head can be made up to 44% more efficient while simultaneously increasing accuracy. Further experiments on RetinaNet and PASCAL VOC show the general effectiveness of our approach. We also introduce `overanchorized' models that can be used together with anchor pruning to eliminate hyperparameters related to the initial shape of anchors.
PyTorch-Hebbian: facilitating local learning in a deep learning framework
Jan 31, 2021



Recently, unsupervised local learning, based on Hebb's idea that change in synaptic efficacy depends on the activity of the pre- and postsynaptic neuron only, has shown potential as an alternative training mechanism to backpropagation. Unfortunately, Hebbian learning remains experimental and rarely makes it way into standard deep learning frameworks. In this work, we investigate the potential of Hebbian learning in the context of standard deep learning workflows. To this end, a framework for thorough and systematic evaluation of local learning rules in existing deep learning pipelines is proposed. Using this framework, the potential of Hebbian learned feature extractors for image classification is illustrated. In particular, the framework is used to expand the Krotov-Hopfield learning rule to standard convolutional neural networks without sacrificing accuracy compared to end-to-end backpropagation. The source code is available at https://github.com/Joxis/pytorch-hebbian.
Populations of Spiking Neurons for Reservoir Computing: Closed Loop Control of a Compliant Quadruped
Apr 14, 2020
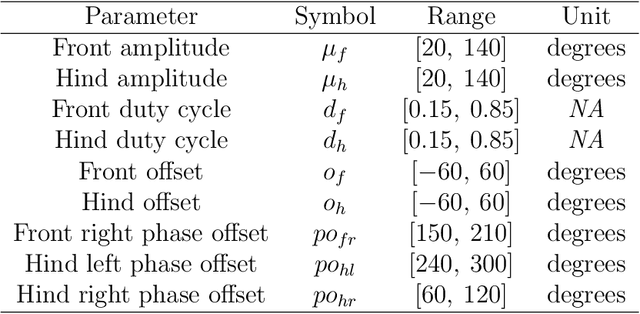


Compliant robots can be more versatile than traditional robots, but their control is more complex. The dynamics of compliant bodies can however be turned into an advantage using the physical reservoir computing frame-work. By feeding sensor signals to the reservoir and extracting motor signals from the reservoir, closed loop robot control is possible. Here, we present a novel framework for implementing central pattern generators with spiking neural networks to obtain closed loop robot control. Using the FORCE learning paradigm, we train a reservoir of spiking neuron populations to act as a central pattern generator. We demonstrate the learning of predefined gait patterns, speed control and gait transition on a simulated model of a compliant quadrupedal robot.