 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerShuffle: Enhancing Robustness in Vision Transformers by Randomizing Layer Execution Order
Jul 05, 2024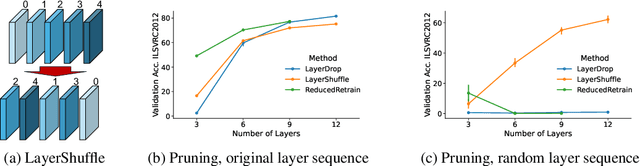

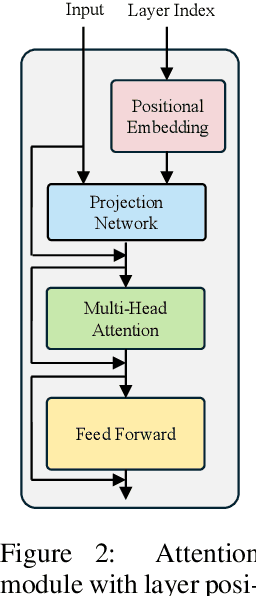

Due to their architecture and how they are trained, artificial neural networks are typically not robust toward pruning, replacing, or shuffling layers at test time. However, such properties would be desirable for different applications, such as distributed neural network architectures where the order of execution cannot be guaranteed or parts of the network can fail during inference. In this work, we address these issues through a number of proposed training approaches for vision transformers whose most important component is randomizing the execution order of attention modules at training time. We show that with our proposed approaches, vision transformers are indeed capable to adapt to arbitrary layer execution orders at test time assuming one tolerates a reduction (about 20\%) in accuracy at the same model size. We also find that our trained models can be randomly merged with each other resulting in functional ("Frankenstein") models without loss of performance compared to the source models. Finally, we layer-prune our models at test time and find that their performance declines gracefully.
Algorithmic Ways of Seeing: Using Object Detection to Facilitate Art Exploration
Mar 28, 2024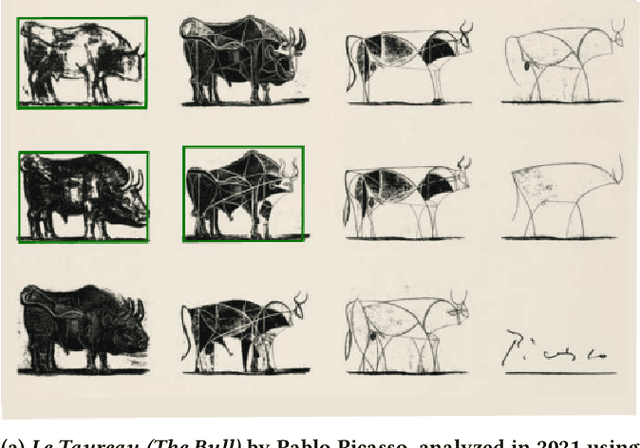
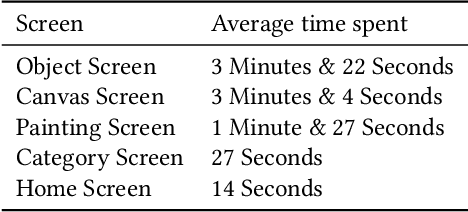
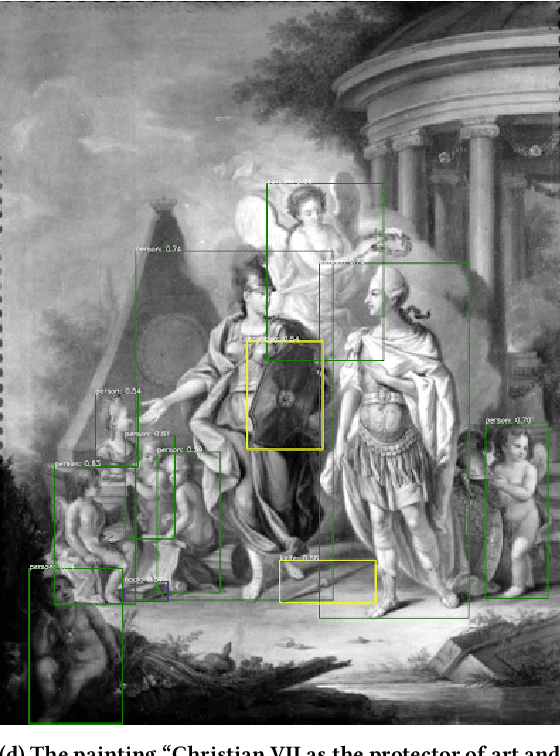

This Research through Design paper explores how object detection may be applied to a large digital art museum collection to facilitate new ways of encountering and experiencing art. We present the design and evaluation of an interactive application called SMKExplore, which allows users to explore a museum's digital collection of paintings by browsing through objects detected in the images, as a novel form of open-ended exploration. We provide three contributions. First, we show how an object detection pipeline can be integrated into a design process for visual exploration. Second, we present the design and development of an app that enables exploration of an art museum's collection. Third, we offer reflections on future possibilities for museums and HCI researchers to incorporate object detection techniques into the digitalization of museums.
CLIPMasterPrints: Fooling Contrastive Language-Image Pre-training Using Latent Variable Evolution
Jul 07, 2023



Models leveraging both visual and textual data such as Contrastive Language-Image Pre-training (CLIP), are increasingly gaining importance. In this work, we show that despite their versatility, such models are vulnerable to what we refer to as fooling master images. Fooling master images are capable of maximizing the confidence score of a CLIP model for a significant number of widely varying prompts, while being unrecognizable for humans. We demonstrate how fooling master images can be mined by searching the latent space of generative models by means of an evolution strategy or stochastic gradient descent. We investigate the properties of the mined fooling master images, and find that images trained on a small number of image captions potentially generalize to a much larger number of semantically related captions. Further, we evaluate two possible mitigation strategies and find that vulnerability to fooling master examples is closely related to a modality gap in contrastive pre-trained multi-modal networks. From the perspective of vulnerability to off-manifold attacks, we therefore argue for the mitigation of modality gaps in CLIP and related multi-modal approaches. Source code and mined CLIPMasterPrints are available at https://github.com/matfrei/CLIPMasterPrints.
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
Feb 12, 2023



Procedural Content Generation (PCG) algorithms provide a technique to generate complex and diverse environments in an automated way. However, while generating content with PCG methods is often straightforward, generating meaningful content that reflects specific intentions and constraints remains challenging. Furthermore, many PCG algorithms lack the ability to generate content in an open-ended manner. Recently, Large Language Models (LLMs) have shown to be incredibly effective in many diverse domains. These trained LLMs can be fine-tuned, re-using information and accelerating training for new tasks. In this work, we introduce MarioGPT, a fine-tuned GPT2 model trained to generate tile-based game levels, in our case Super Mario Bros levels. We show that MarioGPT can not only generate diverse levels, but can be text-prompted for controllable level generation, addressing one of the key challenges of current PCG techniques. As far as we know, MarioGPT is the first text-to-level model. We also combine MarioGPT with novelty search, enabling it to generate diverse levels with varying play-style dynamics (i.e. player paths). This combination allows for the open-ended generation of an increasingly diverse range of content.
Hardware-aware mobile building block evaluation for computer vision
Aug 26, 2022



In this work we propose a methodology to accurately evaluate and compare the performance of efficient neural network building blocks for computer vision in a hardware-aware manner. Our comparison uses pareto fronts based on randomly sampled networks from a design space to capture the underlying accuracy/complexity trade-offs. We show that our approach allows to match the information obtained by previous comparison paradigms, but provides more insights in the relationship between hardware cost and accuracy. We use our methodology to analyze different building blocks and evaluate their performance on a range of embedded hardware platforms. This highlights the importance of benchmarking building blocks as a preselection step in the design process of a neural network. We show that choosing the right building block can speed up inference by up to a factor of 2x on specific hardware ML accelerators.
Anchor Pruning for Object Detection
Apr 01, 2021
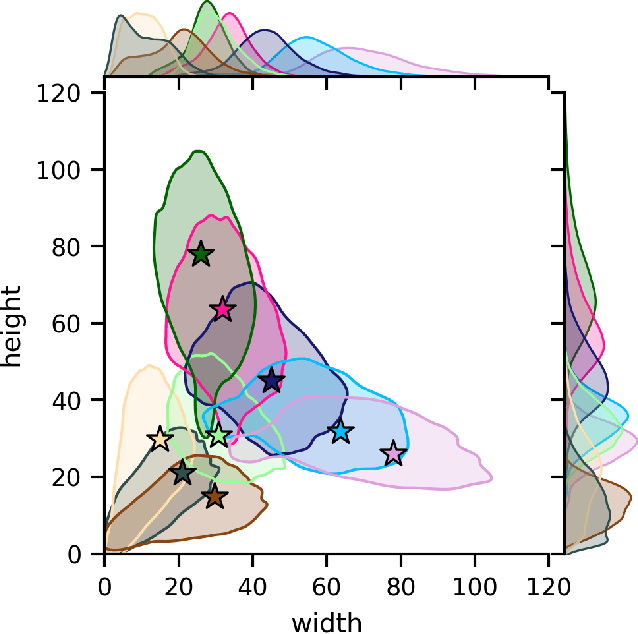
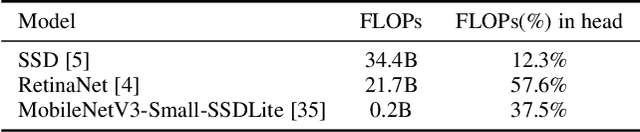
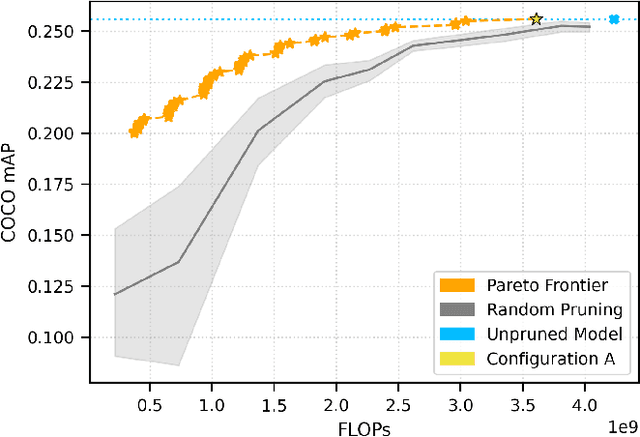
This paper proposes anchor pruning for object detection in one-stage anchor-based detectors. While pruning techniques are widely used to reduce the computational cost of convolutional neural networks, they tend to focus on optimizing the backbone networks where often most computations are. In this work we demonstrate an additional pruning technique, specifically for object detection: anchor pruning. With more efficient backbone networks and a growing trend of deploying object detectors on embedded systems where post-processing steps such as non-maximum suppression can be a bottleneck, the impact of the anchors used in the detection head is becoming increasingly more important. In this work, we show that many anchors in the object detection head can be removed without any loss in accuracy. With additional retraining, anchor pruning can even lead to improved accuracy. Extensive experiments on SSD and MS COCO show that the detection head can be made up to 44% more efficient while simultaneously increasing accuracy. Further experiments on RetinaNet and PASCAL VOC show the general effectiveness of our approach. We also introduce `overanchorized' models that can be used together with anchor pruning to eliminate hyperparameters related to the initial shape of anchors.
Towards Deep Physical Reservoir Computing Through Automatic Task Decomposition And Mapping
Oct 25, 2019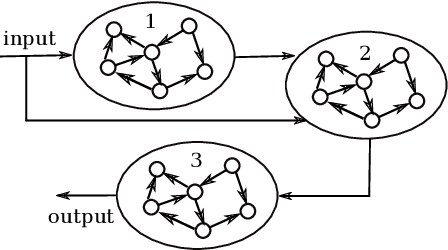

Photonic reservoir computing is a promising candidate for low-energy computing at high bandwidths. Despite recent successes, there are bounds to what one can achieve simply by making photonic reservoirs larger. Therefore, a switch from single-reservoir computing to multi-reservoir and even deep physical reservoir computing is desirable. Given that backpropagation can not be used directly to train multi-reservoir systems in our targeted setting, we propose an alternative approach that still uses its power to derive intermediate targets. In this work we report our findings on a conducted experiment to evaluate the general feasibility of our approach by training a network of 3 Echo State Networks to perform the well-known NARMA-10 task using targets derived through backpropagation. Our results indicate that our proposed method is well-suited to train multi-reservoir systems in a efficient way.
Training Passive Photonic Reservoirs with Integrated Optical Readout
Oct 08, 2018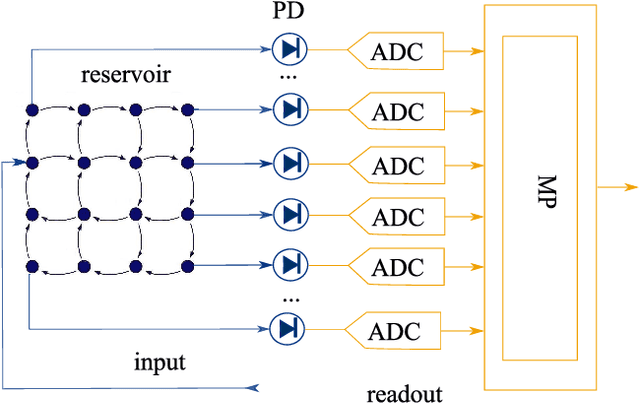

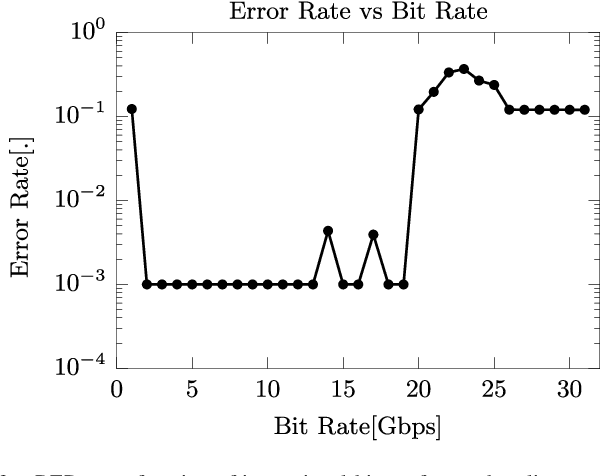

As Moore's law comes to an end, neuromorphic approaches to computing are on the rise. One of these, passive photonic reservoir computing, is a strong candidate for computing at high bitrates (> 10 Gbps) and with low energy consumption. Currently though, both benefits are limited by the necessity to perform training and readout operations in the electrical domain. Thus, efforts are currently underway in the photonic community to design an integrated optical readout, which allows to perform all operations in the optical domain. In addition to the technological challenge of designing such a readout, new algorithms have to be designed in order to train it. Foremost, suitable algorithms need to be able to deal with the fact that the actual on-chip reservoir states are not directly observable. In this work, we investigate several options for such a training algorithm and propose a solution in which the complex states of the reservoir can be observed by appropriately setting the readout weights, while iterating over a predefined input sequence. We perform numerical simulations in order to compare our method with an ideal baseline requiring full observability as well as with an established black-box optimization approach (CMA-ES).