 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerShuffle: Enhancing Robustness in Vision Transformers by Randomizing Layer Execution Order
Jul 05, 2024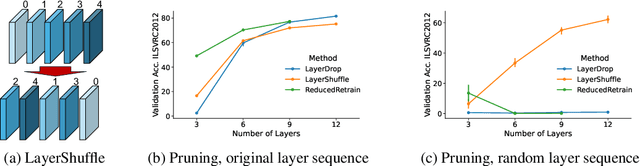

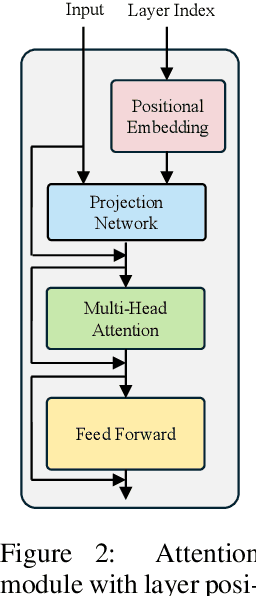

Due to their architecture and how they are trained, artificial neural networks are typically not robust toward pruning, replacing, or shuffling layers at test time. However, such properties would be desirable for different applications, such as distributed neural network architectures where the order of execution cannot be guaranteed or parts of the network can fail during inference. In this work, we address these issues through a number of proposed training approaches for vision transformers whose most important component is randomizing the execution order of attention modules at training time. We show that with our proposed approaches, vision transformers are indeed capable to adapt to arbitrary layer execution orders at test time assuming one tolerates a reduction (about 20\%) in accuracy at the same model size. We also find that our trained models can be randomly merged with each other resulting in functional ("Frankenstein") models without loss of performance compared to the source models. Finally, we layer-prune our models at test time and find that their performance declines gracefully.
Algorithmic Ways of Seeing: Using Object Detection to Facilitate Art Exploration
Mar 28, 2024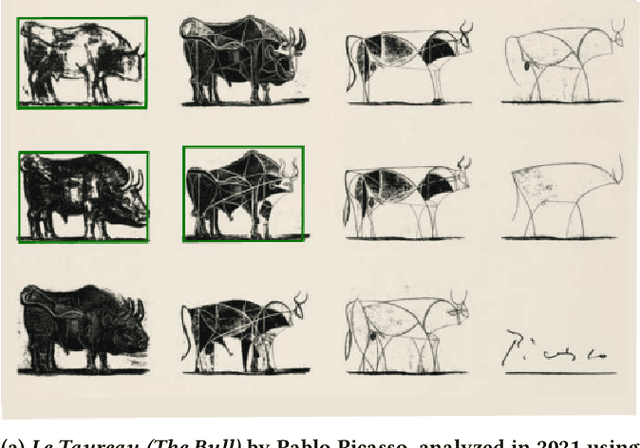
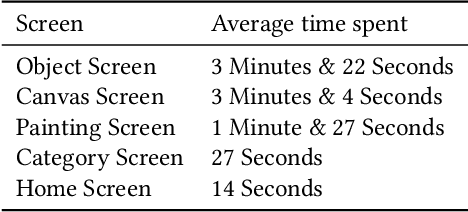
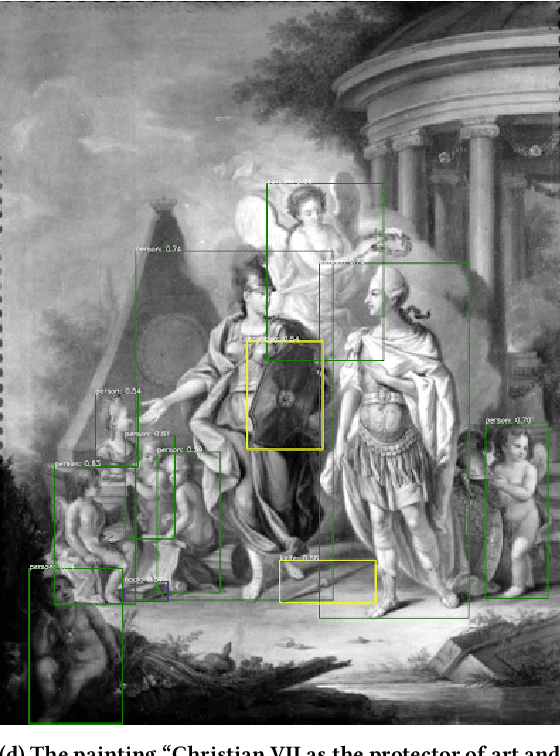

This Research through Design paper explores how object detection may be applied to a large digital art museum collection to facilitate new ways of encountering and experiencing art. We present the design and evaluation of an interactive application called SMKExplore, which allows users to explore a museum's digital collection of paintings by browsing through objects detected in the images, as a novel form of open-ended exploration. We provide three contributions. First, we show how an object detection pipeline can be integrated into a design process for visual exploration. Second, we present the design and development of an app that enables exploration of an art museum's collection. Third, we offer reflections on future possibilities for museums and HCI researchers to incorporate object detection techniques into the digitalization of museums.
CLIPMasterPrints: Fooling Contrastive Language-Image Pre-training Using Latent Variable Evolution
Jul 07, 2023



Models leveraging both visual and textual data such as Contrastive Language-Image Pre-training (CLIP), are increasingly gaining importance. In this work, we show that despite their versatility, such models are vulnerable to what we refer to as fooling master images. Fooling master images are capable of maximizing the confidence score of a CLIP model for a significant number of widely varying prompts, while being unrecognizable for humans. We demonstrate how fooling master images can be mined by searching the latent space of generative models by means of an evolution strategy or stochastic gradient descent. We investigate the properties of the mined fooling master images, and find that images trained on a small number of image captions potentially generalize to a much larger number of semantically related captions. Further, we evaluate two possible mitigation strategies and find that vulnerability to fooling master examples is closely related to a modality gap in contrastive pre-trained multi-modal networks. From the perspective of vulnerability to off-manifold attacks, we therefore argue for the mitigation of modality gaps in CLIP and related multi-modal approaches. Source code and mined CLIPMasterPrints are available at https://github.com/matfrei/CLIPMasterPrints.
Improving Object Detection in Art Images Using Only Style Transfer
Feb 12, 2021
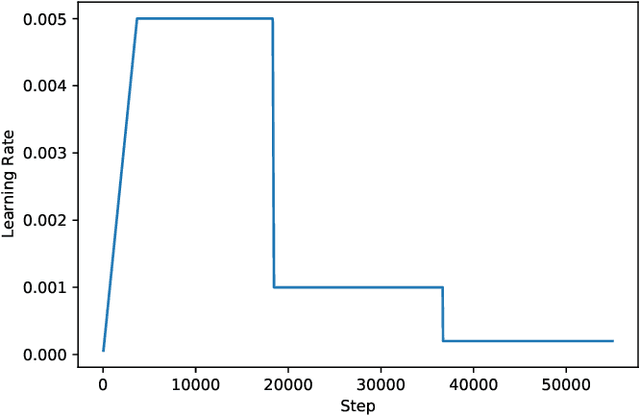
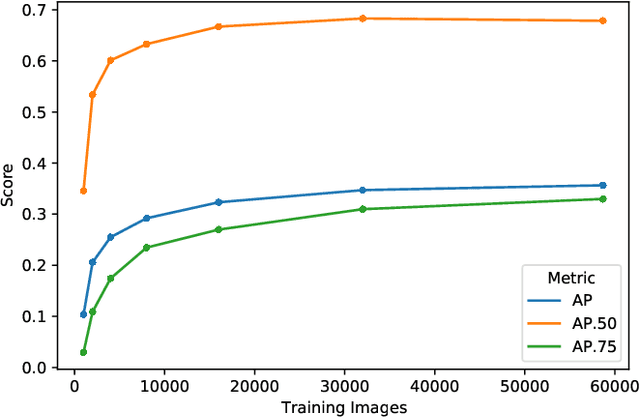

Despite recent advances in object detection using deep learning neural networks, these neural networks still struggle to identify objects in art images such as paintings and drawings. This challenge is known as the cross depiction problem and it stems in part from the tendency of neural networks to prioritize identification of an object's texture over its shape. In this paper we propose and evaluate a process for training neural networks to localize objects - specifically people - in art images. We generate a large dataset for training and validation by modifying the images in the COCO dataset using AdaIn style transfer. This dataset is used to fine-tune a Faster R-CNN object detection network, which is then tested on the existing People-Art testing dataset. The result is a significant improvement on the state of the art and a new way forward for creating datasets to train neural networks to process art images.