 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemann$^2$: Learning Riemannian Submanifolds from Riemannian Data
Mar 07, 2025Latent variable models are powerful tools for learning low-dimensional manifolds from high-dimensional data. However, when dealing with constrained data such as unit-norm vectors or symmetric positive-definite matrices, existing approaches ignore the underlying geometric constraints or fail to provide meaningful metrics in the latent space. To address these limitations, we propose to learn Riemannian latent representations of such geometric data. To do so, we estimate the pullback metric induced by a Wrapped Gaussian Process Latent Variable Model, which explicitly accounts for the data geometry. This enables us to define geometry-aware notions of distance and shortest paths in the latent space, while ensuring that our model only assigns probability mass to the data manifold. This generalizes previous work and allows us to handle complex tasks in various domains, including robot motion synthesis and analysis of brain connectomes.
A History of Philosophy in Colombia through Topic Modelling
Dec 05, 2024



Data-driven approaches to philosophy have emerged as a valuable tool for studying the history of the discipline. However, most studies in this area have focused on a limited number of journals from specific regions and subfields. We expand the scope of this research by applying dynamic topic modelling techniques to explore the history of philosophy in Colombia and Latin America. Our study examines the Colombian philosophy journal Ideas y Valores, founded in 1951 and currently one of the most influential academic philosophy journals in the region. By analyzing the evolution of topics across the journal's history, we identify various trends and specific dynamics in philosophical discourse within the Colombian and Latin American context. Our findings reveal that the most prominent topics are value theory (including ethics, political philosophy, and aesthetics), epistemology, and the philosophy of science. We also trace the evolution of articles focusing on the historical and interpretive aspects of philosophical texts, and we note a notable emphasis on German philosophers such as Kant, Husserl, and Hegel on various topics throughout the journal's lifetime. Additionally, we investigate whether articles with a historical focus have decreased over time due to editorial pressures. Our analysis suggests no significant decline in such articles. Finally, we propose ideas for extending this research to other Latin American journals and suggest improvements for natural language processing workflows in non-English languages.
A survey and benchmark of high-dimensional Bayesian optimization of discrete sequences
Jun 07, 2024Optimizing discrete black-box functions is key in several domains, e.g. protein engineering and drug design. Due to the lack of gradient information and the need for sample efficiency, Bayesian optimization is an ideal candidate for these tasks. Several methods for high-dimensional continuous and categorical Bayesian optimization have been proposed recently. However, our survey of the field reveals highly heterogeneous experimental set-ups across methods and technical barriers for the replicability and application of published algorithms to real-world tasks. To address these issues, we develop a unified framework to test a vast array of high-dimensional Bayesian optimization methods and a collection of standardized black-box functions representing real-world application domains in chemistry and biology. These two components of the benchmark are each supported by flexible, scalable, and easily extendable software libraries (poli and poli-baselines), allowing practitioners to readily incorporate new optimization objectives or discrete optimizers. Project website: https://machinelearninglifescience.github.io/hdbo_benchmark
A Continuous Relaxation for Discrete Bayesian Optimization
Apr 26, 2024To optimize efficiently over discrete data and with only few available target observations is a challenge in Bayesian optimization. We propose a continuous relaxation of the objective function and show that inference and optimization can be computationally tractable. We consider in particular the optimization domain where very few observations and strict budgets exist; motivated by optimizing protein sequences for expensive to evaluate bio-chemical properties. The advantages of our approach are two-fold: the problem is treated in the continuous setting, and available prior knowledge over sequences can be incorporated directly. More specifically, we utilize available and learned distributions over the problem domain for a weighting of the Hellinger distance which yields a covariance function. We show that the resulting acquisition function can be optimized with both continuous or discrete optimization algorithms and empirically assess our method on two bio-chemical sequence optimization tasks.
MarioGPT: Open-Ended Text2Level Generation through Large Language Models
Feb 12, 2023



Procedural Content Generation (PCG) algorithms provide a technique to generate complex and diverse environments in an automated way. However, while generating content with PCG methods is often straightforward, generating meaningful content that reflects specific intentions and constraints remains challenging. Furthermore, many PCG algorithms lack the ability to generate content in an open-ended manner. Recently, Large Language Models (LLMs) have shown to be incredibly effective in many diverse domains. These trained LLMs can be fine-tuned, re-using information and accelerating training for new tasks. In this work, we introduce MarioGPT, a fine-tuned GPT2 model trained to generate tile-based game levels, in our case Super Mario Bros levels. We show that MarioGPT can not only generate diverse levels, but can be text-prompted for controllable level generation, addressing one of the key challenges of current PCG techniques. As far as we know, MarioGPT is the first text-to-level model. We also combine MarioGPT with novelty search, enabling it to generate diverse levels with varying play-style dynamics (i.e. player paths). This combination allows for the open-ended generation of an increasingly diverse range of content.
Bringing robotics taxonomies to continuous domains via GPLVM on hyperbolic manifolds
Oct 04, 2022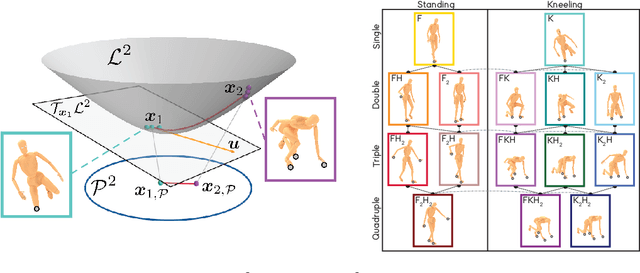
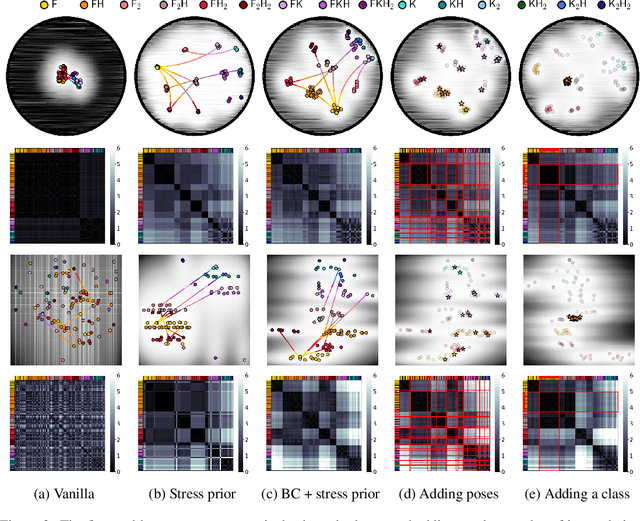

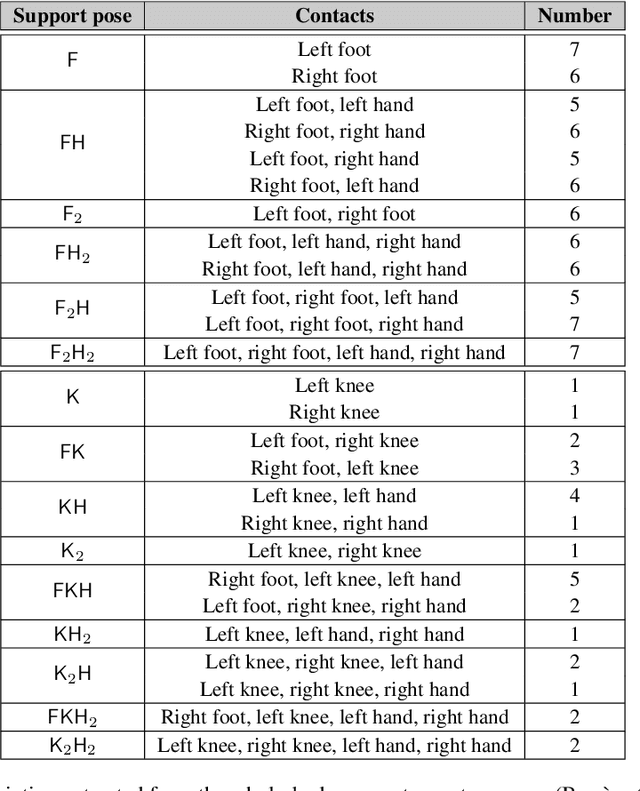
Robotic taxonomies have appeared as high-level hierarchical abstractions that classify how humans move and interact with their environment. They have proven useful to analyse grasps, manipulation skills, and whole-body support poses. Despite the efforts devoted to design their hierarchy and underlying categories, their use in application fields remains scarce. This may be attributed to the lack of computational models that fill the gap between the discrete hierarchical structure of the taxonomy and the high-dimensional heterogeneous data associated to its categories. To overcome this problem, we propose to model taxonomy data via hyperbolic embeddings that capture the associated hierarchical structure. To do so, we formulate a Gaussian process hyperbolic latent variable model and enforce the taxonomy structure through graph-based priors on the latent space and distance-preserving back constraints. We test our model on the whole-body support pose taxonomy to learn hyperbolic embeddings that comply with the original graph structure. We show that our model properly encodes unseen poses from existing or new taxonomy categories, it can be used to generate trajectories between the embeddings, and it outperforms its Euclidean counterparts.
Mario Plays on a Manifold: Generating Functional Content in Latent Space through Differential Geometry
May 31, 2022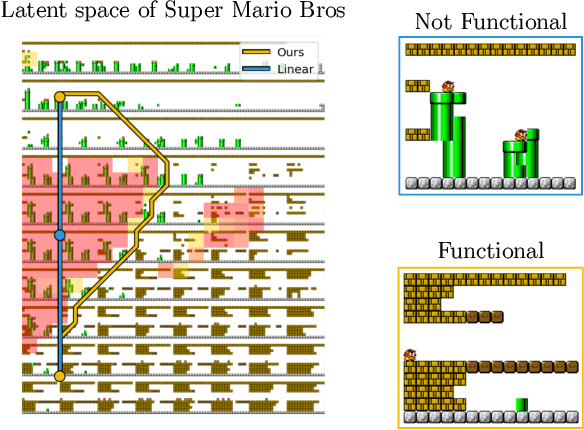
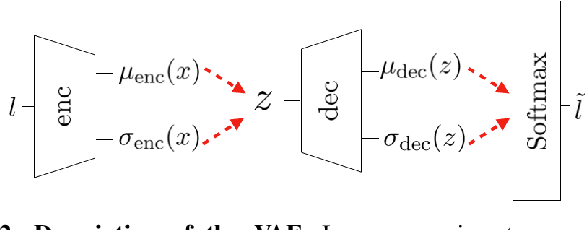
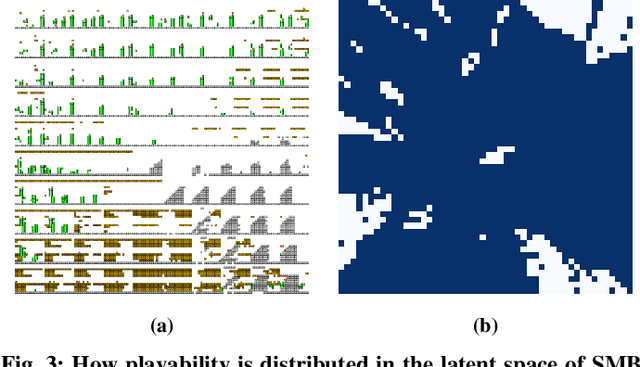
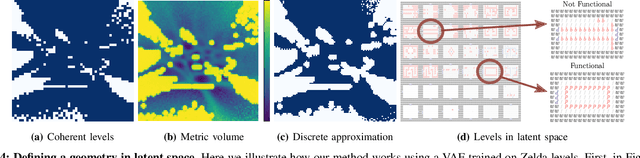
Deep generative models can automatically create content of diverse types. However, there are no guarantees that such content will satisfy the criteria necessary to present it to end-users and be functional, e.g. the generated levels could be unsolvable or incoherent. In this paper we study this problem from a geometric perspective, and provide a method for reliable interpolation and random walks in the latent spaces of Categorical VAEs based on Riemannian geometry. We test our method with "Super Mario Bros" and "The Legend of Zelda" levels, and against simpler baselines inspired by current practice. Results show that the geometry we propose is better able to interpolate and sample, reliably staying closer to parts of the latent space that decode to playable content.
Variational Neural Cellular Automata
Feb 02, 2022
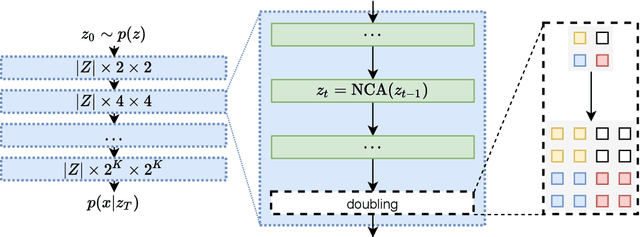


In nature, the process of cellular growth and differentiation has lead to an amazing diversity of organisms -- algae, starfish, giant sequoia, tardigrades, and orcas are all created by the same generative process. Inspired by the incredible diversity of this biological generative process, we propose a generative model, the Variational Neural Cellular Automata (VNCA), which is loosely inspired by the biological processes of cellular growth and differentiation. Unlike previous related works, the VNCA is a proper probabilistic generative model, and we evaluate it according to best practices. We find that the VNCA learns to reconstruct samples well and that despite its relatively few parameters and simple local-only communication, the VNCA can learn to generate a large variety of output from information encoded in a common vector format. While there is a significant gap to the current state-of-the-art in terms of generative modeling performance, we show that the VNCA can learn a purely self-organizing generative process of data. Additionally, we show that the VNCA can learn a distribution of stable attractors that can recover from significant damage.
Pulling back information geometry
Jun 09, 2021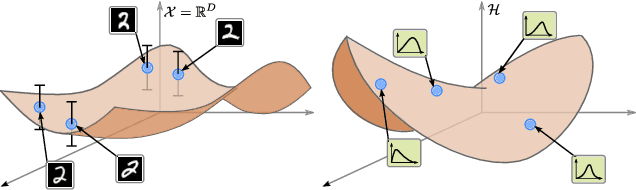

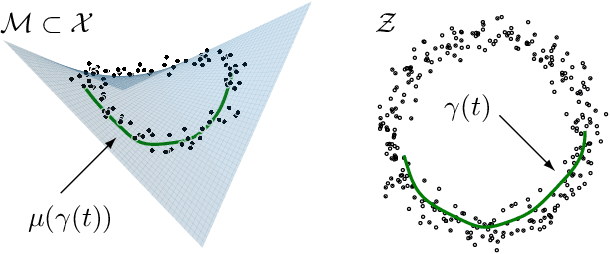

Latent space geometry has shown itself to provide a rich and rigorous framework for interacting with the latent variables of deep generative models. The existing theory, however, relies on the decoder being a Gaussian distribution as its simple reparametrization allows us to interpret the generating process as a random projection of a deterministic manifold. Consequently, this approach breaks down when applied to decoders that are not as easily reparametrized. We here propose to use the Fisher-Rao metric associated with the space of decoder distributions as a reference metric, which we pull back to the latent space. We show that we can achieve meaningful latent geometries for a wide range of decoder distributions for which the previous theory was not applicable, opening the door to `black box' latent geometries.
Fast Game Content Adaptation Through Bayesian-based Player Modelling
May 18, 2021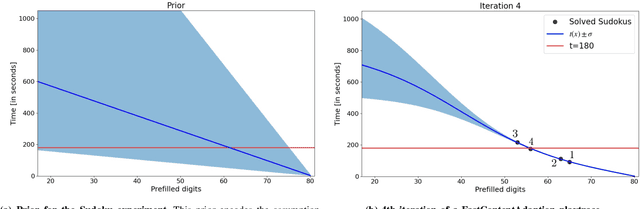
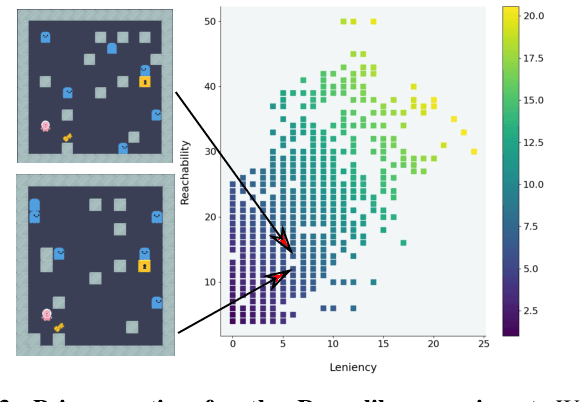
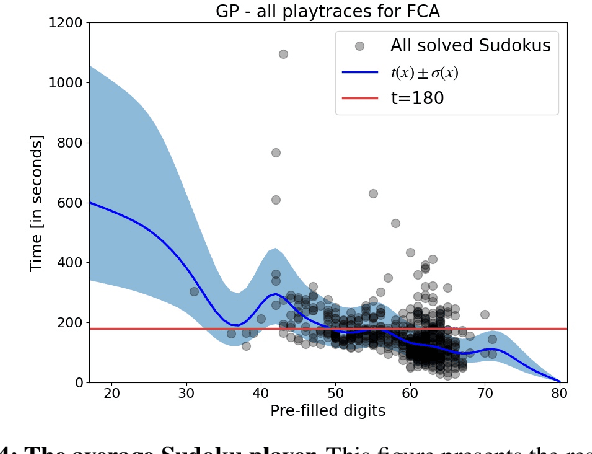
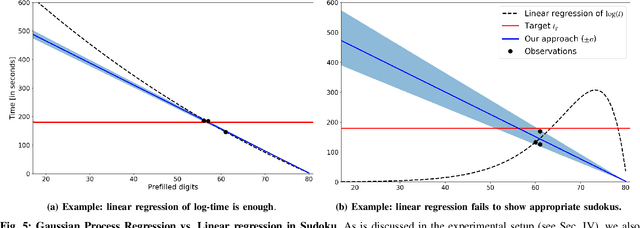
In games (as well as many user-facing systems), adapting content to user's preferences and experience is an important challenge. This paper explores a novel method to realize this goal in the context of dynamic difficulty adjustment (DDA). Here the aim is to constantly adapt the content of a game to the skill level of the player, keeping them engaged by avoiding states that are either too difficult or too easy. Current systems for DDA rely on expensive data mining, or on hand-crafted rules designed for particular domains, and usually adapts to keep players in the flow, leaving no room for the designer to present content that is purposefully easy or difficult. This paper presents a Bayesian Optimization-based system for DDA that is agnostic to the domain and that can target particular difficulties. We deploy this framework in two different domains: the puzzle game Sudoku, and a simple Roguelike game. By modifying the acquisition function's optimization, we are reliably able to present a puzzle with a bespoke difficulty for players with different skill levels in less than five iterations (for Sudoku) and fifteen iterations (for the simple Roguelike), significantly outperforming simpler heuristics for difficulty adjustment in said domains, with the added benefit of maintaining a model of the user. These results point towards a promising alternative for content adaption in a variety of different domains.